> ## Documentation Index
> Fetch the complete documentation index at: https://aegean.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Maximum Likelihood Estimation of Conditional Models
> Applying Maximum Likelihood to conditional distributions for supervised learning regression tasks.
The discussion in the [marginal distribution](/aiml-common/lectures/optimization/maximum-likelihood/marginal_maximum_likelihood) is equivalently applicable to the conditional distribution $p_{model}(\mathbf y \mid \mathbf x, \mathbf w)$ which governs supervised learning, $y$ being the symbol of the label / target variable. Therefore all machine learning software frameworks offer excellent APIs on CE calculation.
$L(\mathbf w) = - \mathbb{E}_{\mathbf x, \mathbf y \sim \hat p_{data}} \log p_{model}(\mathbf y \mid \mathbf x; \mathbf w)$
The attractiveness of the ML solution is that the CE (also known as log-loss) is general and we *don't need to re-design it* when we change the model.
## Visualizing the regression function - the conditional mean
It is now instructive to go over an example to understand that even the plain-old mean squared error (MSE), the objective that is common in the regression setting, falls under the same umbrella - it's the cross entropy between $\hat p_{data}$ and a Gaussian model.
Please follow the discussion associated with [Section 5.5.1 of Ian Goodfellow's Deep Learning book](https://www.deeplearningbook.org/contents/ml.html) or section 20.2.4 of Russell & Norvig's book and consider the following figure for assistance to visualize the relationship of $p_{data}$ and $p_{model}$.
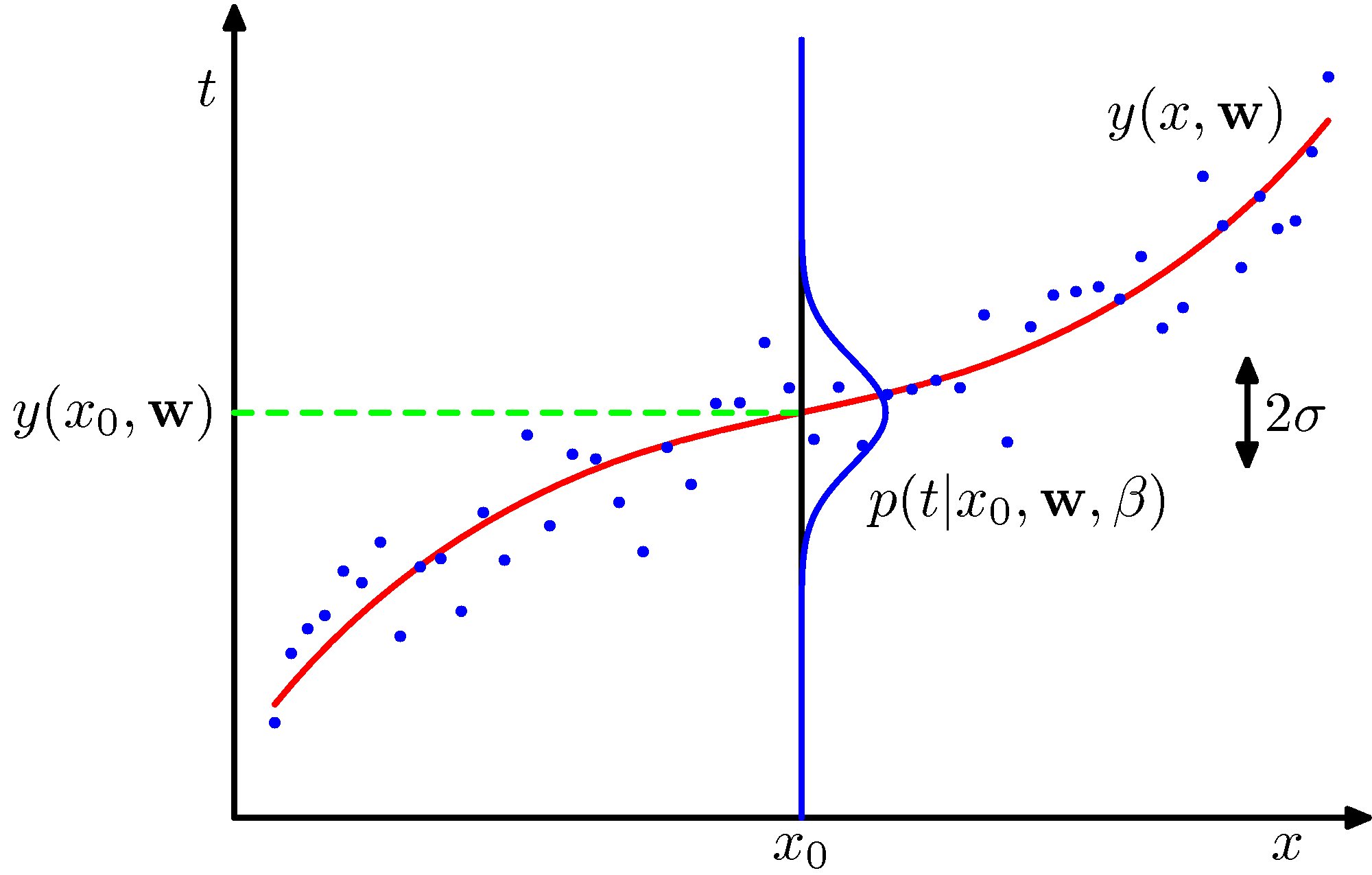 *The green dashed line shows the mean of the $p_{model}$ distribution. Replace the y-axis target variable $t$ with $y$.*
## Key Insight: MSE as Cross-Entropy
When we assume the model distribution is Gaussian:
$p_{model}(\mathbf y \mid \mathbf x; \mathbf w) = \mathcal{N}(\mathbf y \mid f(\mathbf x; \mathbf w), \sigma^2)$
The negative log-likelihood becomes:
$-\log p_{model}(\mathbf y \mid \mathbf x; \mathbf w) = \frac{1}{2\sigma^2}(\mathbf y - f(\mathbf x; \mathbf w))^2 + \text{const}$
This is proportional to the **mean squared error (MSE)**. Therefore, minimizing MSE is equivalent to maximum likelihood estimation under a Gaussian noise assumption.
## What the point estimate leaves out
Maximum likelihood returns a single $\hat{\mathbf w}$, so it gives you one conditional-mean curve $f(\mathbf x; \hat{\mathbf w})$ together with the fixed noise variance $\sigma^2$. Each of these is one source of predictive uncertainty:
* The $\sigma^2$ in the Gaussian is the **aleatoric** uncertainty. It is irreducible by construction: the model assumes the noise is constant, so it appears as the $\frac{1}{2\sigma^2}$ scaling and the additive const, never as something optimization can drive to zero.
* What a point estimate cannot show is how much the curve $f(\mathbf x; \hat{\mathbf w})$ itself would shift if you refit on a different training sample. That spread is the **epistemic** uncertainty, and a single $\hat{\mathbf w}$ is silent about it.
The [aleatoric and epistemic uncertainty](/aiml-common/lectures/aleatoric-epistemic) page picks up exactly here. It treats this Gaussian as the data-generating truth and decomposes the total predictive variance into the $\sigma^2$ floor plus the spread of the fitted model across resampled training sets, the term a point-estimate MLE discards.
## References
* [Marginal Maximum Likelihood](/aiml-common/lectures/optimization/maximum-likelihood/marginal_maximum_likelihood) - Introduction to MLE for marginal distributions
* [MLE of Gaussian Parameters](/aiml-common/lectures/optimization/maximum-likelihood/mle-gaussian-parameters) - Detailed derivation of MLE for Gaussian parameters
* [Section 5.5.1 - Conditional Log-Likelihood](https://www.deeplearningbook.org/contents/ml.html) - Deep Learning Book (Goodfellow, Bengio, Courville)
* Section 20.2.4 of Artificial Intelligence: A Modern Approach (Russell & Norvig)
***
[Edit this page on GitHub](https://github.com/aegean-ai/eaia/edit/main/src/aiml-common/lectures/optimization/maximum-likelihood/conditional_maximum_likelihood.mdx) or [file an issue](https://github.com/aegean-ai/eaia/issues/new/choose).
*The green dashed line shows the mean of the $p_{model}$ distribution. Replace the y-axis target variable $t$ with $y$.*
## Key Insight: MSE as Cross-Entropy
When we assume the model distribution is Gaussian:
$p_{model}(\mathbf y \mid \mathbf x; \mathbf w) = \mathcal{N}(\mathbf y \mid f(\mathbf x; \mathbf w), \sigma^2)$
The negative log-likelihood becomes:
$-\log p_{model}(\mathbf y \mid \mathbf x; \mathbf w) = \frac{1}{2\sigma^2}(\mathbf y - f(\mathbf x; \mathbf w))^2 + \text{const}$
This is proportional to the **mean squared error (MSE)**. Therefore, minimizing MSE is equivalent to maximum likelihood estimation under a Gaussian noise assumption.
## What the point estimate leaves out
Maximum likelihood returns a single $\hat{\mathbf w}$, so it gives you one conditional-mean curve $f(\mathbf x; \hat{\mathbf w})$ together with the fixed noise variance $\sigma^2$. Each of these is one source of predictive uncertainty:
* The $\sigma^2$ in the Gaussian is the **aleatoric** uncertainty. It is irreducible by construction: the model assumes the noise is constant, so it appears as the $\frac{1}{2\sigma^2}$ scaling and the additive const, never as something optimization can drive to zero.
* What a point estimate cannot show is how much the curve $f(\mathbf x; \hat{\mathbf w})$ itself would shift if you refit on a different training sample. That spread is the **epistemic** uncertainty, and a single $\hat{\mathbf w}$ is silent about it.
The [aleatoric and epistemic uncertainty](/aiml-common/lectures/aleatoric-epistemic) page picks up exactly here. It treats this Gaussian as the data-generating truth and decomposes the total predictive variance into the $\sigma^2$ floor plus the spread of the fitted model across resampled training sets, the term a point-estimate MLE discards.
## References
* [Marginal Maximum Likelihood](/aiml-common/lectures/optimization/maximum-likelihood/marginal_maximum_likelihood) - Introduction to MLE for marginal distributions
* [MLE of Gaussian Parameters](/aiml-common/lectures/optimization/maximum-likelihood/mle-gaussian-parameters) - Detailed derivation of MLE for Gaussian parameters
* [Section 5.5.1 - Conditional Log-Likelihood](https://www.deeplearningbook.org/contents/ml.html) - Deep Learning Book (Goodfellow, Bengio, Courville)
* Section 20.2.4 of Artificial Intelligence: A Modern Approach (Russell & Norvig)
***
[Edit this page on GitHub](https://github.com/aegean-ai/eaia/edit/main/src/aiml-common/lectures/optimization/maximum-likelihood/conditional_maximum_likelihood.mdx) or [file an issue](https://github.com/aegean-ai/eaia/issues/new/choose).