Behavioral Cloning with CarRacing-v3
Behavioral cloning (BC) is the simplest form of imitation learning: collect expert demonstrations, then train a policy via supervised learning to map observations to actions. It is the starting point for understanding why imitation learning works, and why it fails. In this section you will:- Train an expert policy using PPO
- Collect expert driving demonstrations
- Train a BC policy via supervised learning on the expert’s data
- Observe distribution shift, the core failure mode of BC
- Fix it with DAgger (Dataset Aggregation)
Setup
Step 1: Create the environment
Step 2: Train an expert policy
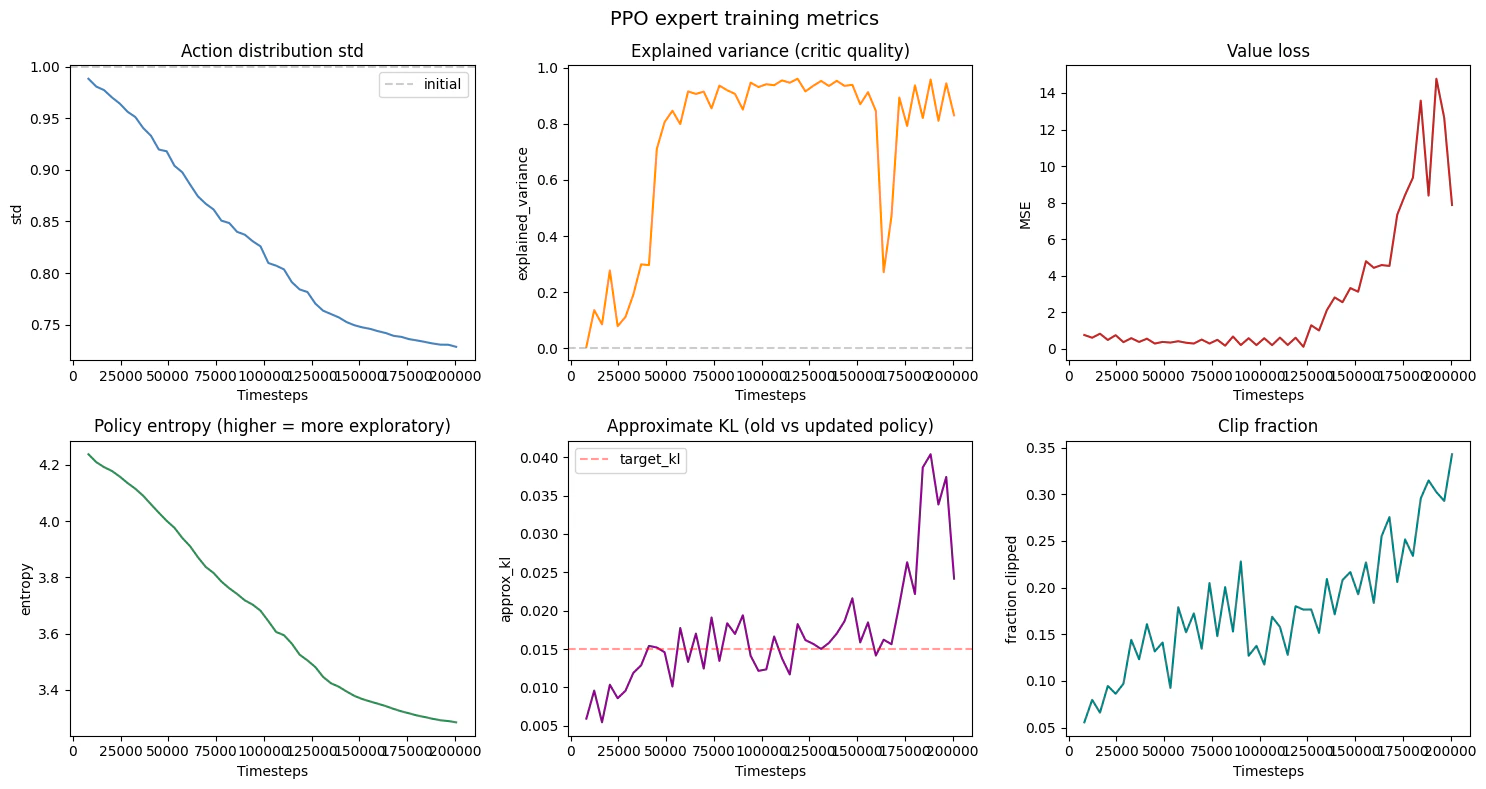
We train an expert using PPO. In a real setting you might use a pre-trained checkpoint or human teleoperation. Here PPO acts as our “expert driver.” Note: Training for 200k timesteps takes ~5-10 minutes on CPU.Reading PPO training output
PPO logs a block of metrics after each rollout-and-update iteration. Withverbose=1 you would see something like this:
std) is a separate learned parameter (state-independent log_std). Actions are sampled from Normal(mean, std) at training time and set to mean at evaluation time when deterministic=True. There is no diffusion head, modern diffusion-based action heads (Chi et al. 2023) are an alternative used in some manipulation BC systems, but they are not required for continuous control and SB3 PPO does not use them.
Each metric and the trend you should expect during a healthy run:
The next cell plots these metrics over the course of training using the data captured by the callback above.
Step 3: Collect expert demonstrations
Roll out the expert to collect (observation, action) pairs, this is our training data for behavioral cloning.
Step 4: Train a behavioral cloning policy
BC is supervised learning: a CNN maps observations to actions, trained with MSE loss against the expert’s recorded actions.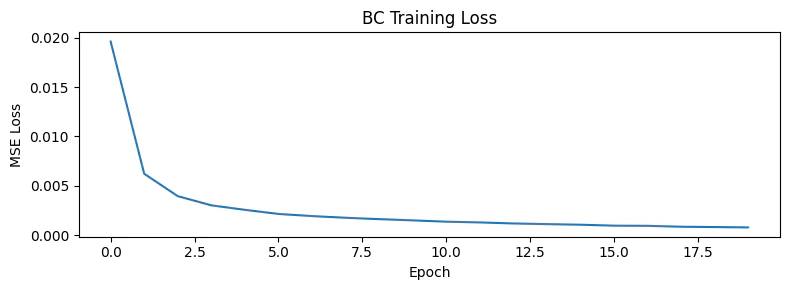
Step 5: Evaluate and observe distribution shift
Deploy the BC policy and compare against the expert. What you will observe: the BC policy performs noticeably worse than the expert. On straight sections it may track the road, but on sharp turns it drifts off. Once off-track, it enters states the expert never demonstrated, predictions become unreliable, and the car spirals further off course. This is compounding error from distribution shift: at training time, the policy only saw states along the expert’s trajectory. At test time, any small deviation puts the agent in unfamiliar territory.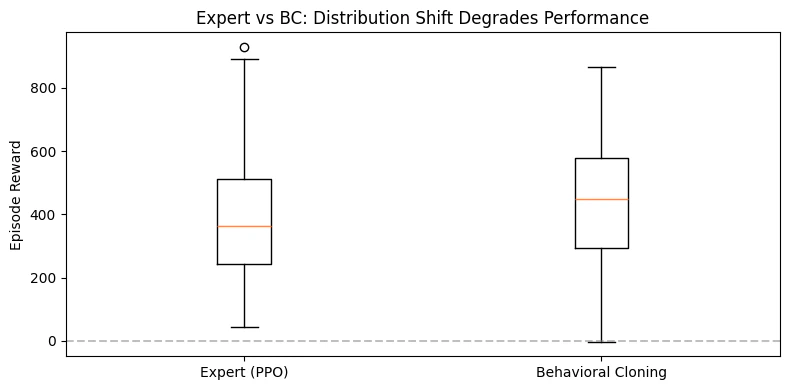
Step 6: Fix it with DAgger
DAgger (Dataset Aggregation) addresses distribution shift by iteratively collecting new data from the learner’s trajectory, labeled by the expert. The algorithm:- Train an initial BC policy on expert demonstrations
- Roll out the learner’s policy in the environment
- Ask the expert to label the states the learner visited (what would you have done here?)
- Add this new data to the training set
- Retrain and repeat
Compare all three policies
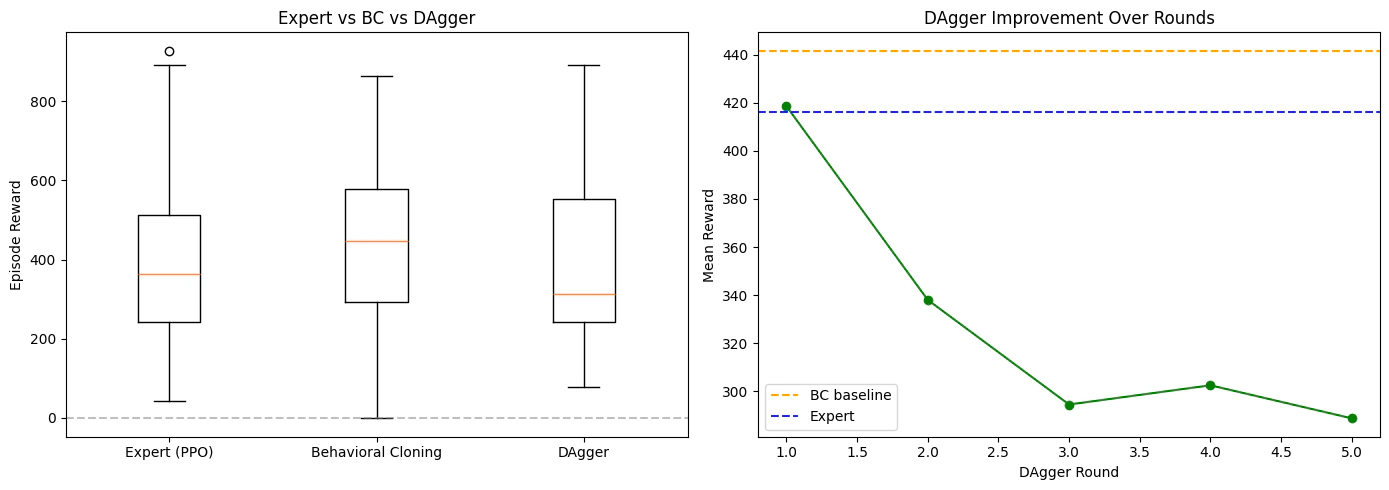
Summary
The distribution shift problem you observed here, and DAgger’s fix of relabeling learner-visited states, reappears throughout robot learning. Later in the course, you will revisit these ideas in the context of world models and VLA architectures, where the same fundamental challenge is addressed at larger scale.
Further reading
- Bagnell (2015). An Invitation to Imitation, accessible introduction to the theory
- Ross et al. (2011). A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning, the DAgger paper
- Bojarski et al. (2016). End to End Learning for Self-Driving Cars, NVIDIA’s original end-to-end driving work
- The imitation library documentation provides complete tutorials for BC, DAgger, GAIL, and AIRL