3Blue1Brown
You can watch these videos for a more elementary treatment of the topic.Deep Learning Book
The corresponding chapter of Ian Goodfellow’s Deep Learning book is what you need to know as data scientists.Gilbert Strang
Let me introduce you MIT prof G Strang - probably the best educator in America. He has published this playlist of youtube videos on Linear Algebra.Recitation Video
Linear Algebra recitation for my classes. Recitation was delivered by my TA Shweta Selvaraj Achary.
Key Points
We can now summarize the points to pay attention to, for ML applications. In the following we assume a data matrix with rows and columns. We also assume that the matrix is such that it has independent rows or columns, called the matrix rank.Projections
Its important to understand this basic operator and its geometric interpretation as it is met in problems like Ordinary Least Squares but also all over ML and other fields such as compressed sensing. In the following we assume that the reader is familiar with the concept of vector spaces and subspaces. Let be a vector subspace of . For example in , are the lines and planes going through the origin. The projection operator onto implements a linear transformation: . We will stick to to maintain the ability to plot the operations involved. We also define the orthogonal subspace, The transformation projects onto space in the sense that when you apply this operator, every vector in any other space results in the subspace . In our example above, This means that any components of the vector that belonged to are gone when applying the projection operator. Effectively, the original space is decomposed into Now we can treat projections onto specific subspaces such as lines and planes passing through the origin. For a line defined by a direction vector we can define the projection onto the line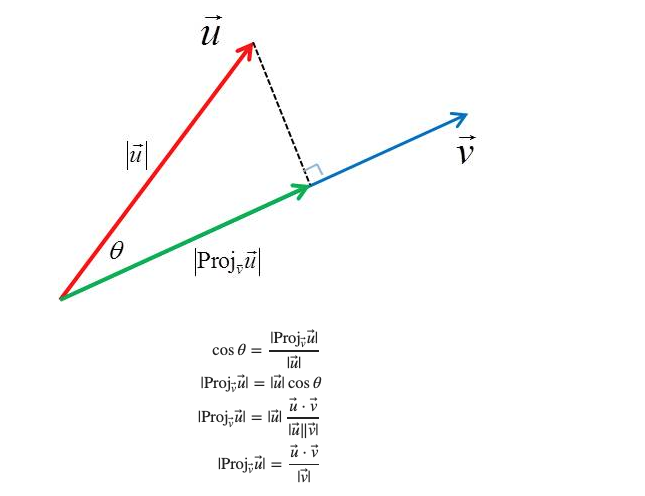
The Four Fundamental Subspaces
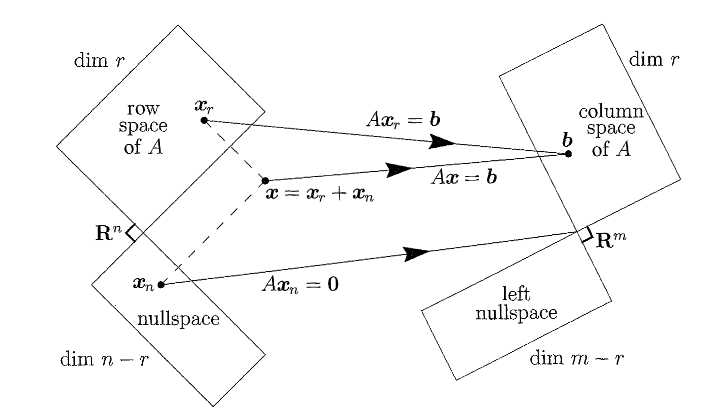
- The column space of , denoted by , with dimension .
- The nullspace of , denoted by , with dimension .
- The row space of which is the column space of , with dimension
- The left nullspace of , which is the nullspace of , denoted by , with dimension .

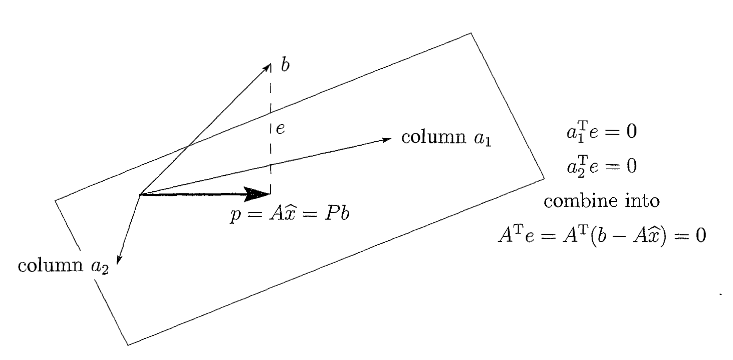
Eigenvalues and Eigenvectors
The following video gives an intuitive explanation of eigenvalues and eigenvectors and its included here due to its visualizations that it offers. The video must be viewed in conjunction with Strang’s introduction
A geometric interpretation of the eigenvectors and eigenvalues is given in the following figure: