-
The whole purpose of probabilistic modeling is to introduce uncertainty into our problem statement. There are three types of uncertainties, which fall into the broader aleatoric and epistemic categories:
- Inherent stochasticity - e.g. impact of wind in self-driving car control systems at moderate to high speed.
- Incomplete observability - e.g. sensor imperfections causing loss of sensing information
- Incomplete modeling - e.g. models and algorithms that are not implementable to an analog world and need to be discretized.
-
Probabilities can be used in two ways.
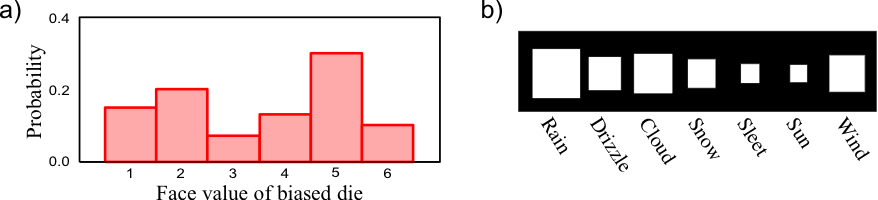
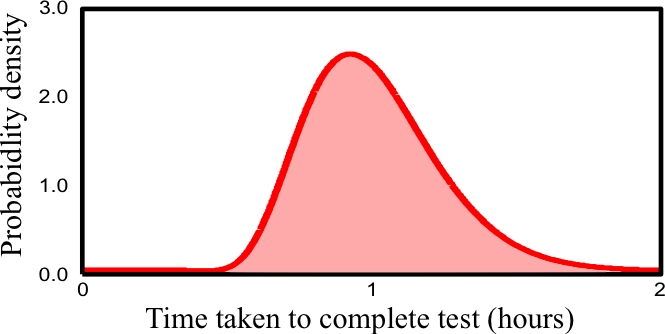
- Probabilities can describe frequencies of outcomes in random experiments
- Probabilities can also be used, more generally, to describe degrees of belief in propositions that do not involve random variables. This more general use of probability to quantify beliefs is known as the Bayesian viewpoint. It is also known as the subjective interpretation of probability, since the probabilities depend on assumptions.



Sum and Product rules
The following video explains the sum and product rules that are extensivbely used in data science and for understanding the Bayes rule.Sum rule and the Marginal Probability
Given the joint what is the marginal probability ?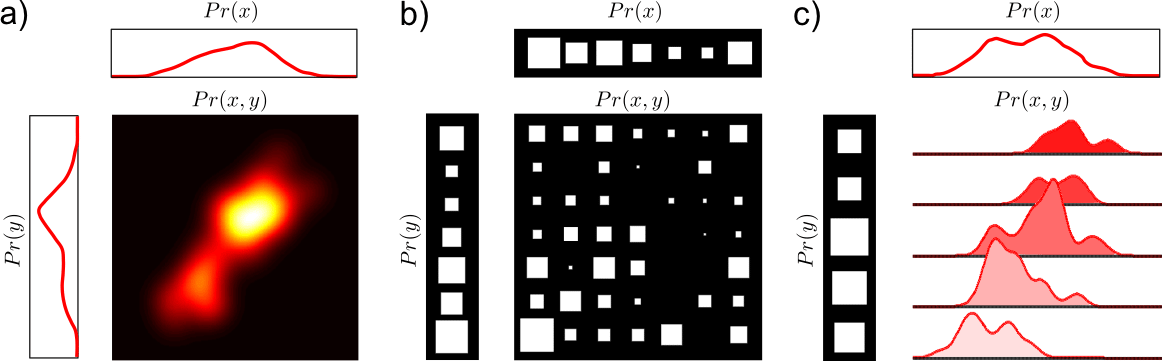
Conditional Probability and the Product or chain rule
This is obtained from the definition of conditional probability: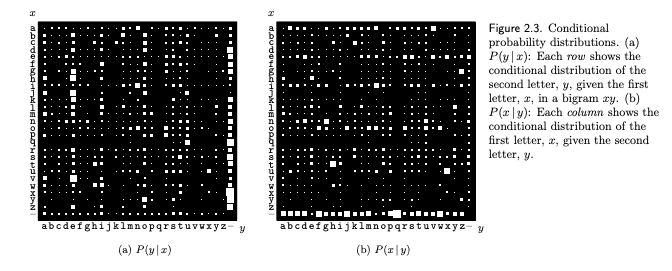
Are and in the example above independent?
References
- Frazier, P. (2018). A Tutorial on Bayesian Optimization.
- Kendall, A., Gal, Y. (2017). What uncertainties do we need in Bayesian deep learning for computer vision?.
- Kendall, A., Gal, Y. (2017). What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?.