Introduction to AI as the course since we have a critical mass of material (videos, slides, web site with links to papers).
In its full implementation Erica will be able to see you, hear you and talk to you. However, for the purpose of this project and knowing how constrained student computers are, we will focus on text-based interactions only.
System Architecture
The system architecture for Rebeca consists of several key components:- User Interface (UI): you need to use a chat application and you can choose any chat interface of your liking provided you use it only for the text input and answer output. For example OpenWebUI may have a RAG interfacing capability but you are not allowed to use that. You are also not allowed to use AI browsers recently introduced by Perplexity (Comet), OpenAI and others.
- LLM Server: The chat should be able to connect to a local Ollama or LM Studio server instance and be configured to use the qwen2.5 model. If your hardware simply does not allow you to run locally any version of the Qwen2.5 models you can use a remote API to access it and we recommend OpenRouter.
- GraphRAG Retrieval Augmented Generation. It combines the strengths of retrieval-based and generation-based models, enabling the model to retrieve relevant information from a large corpus and generate a coherent domain-specific response. The individual components are shown in (see figure above).
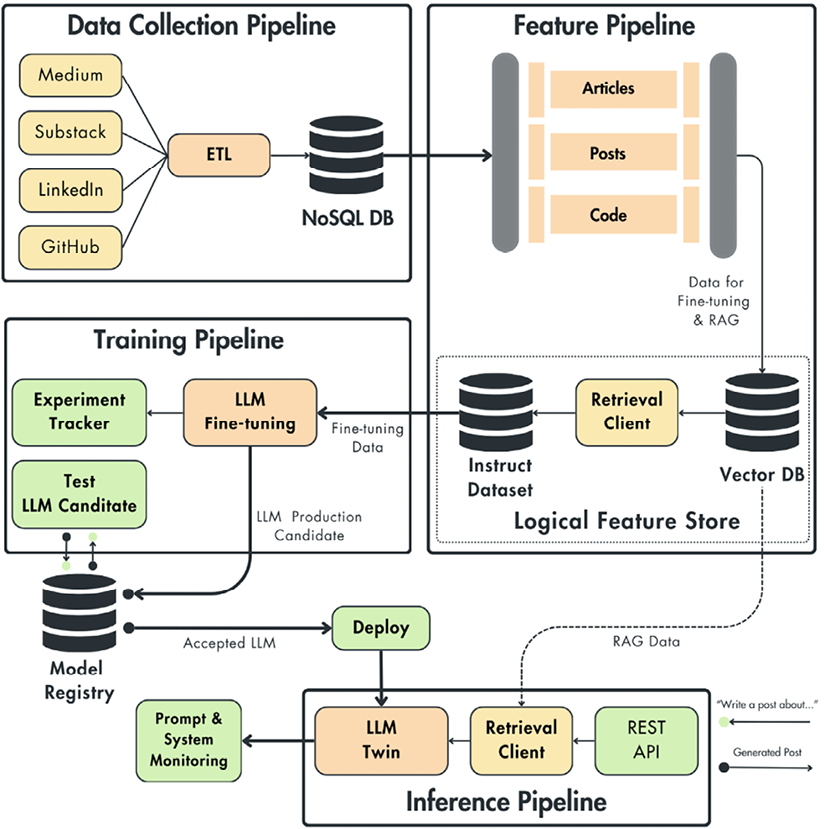
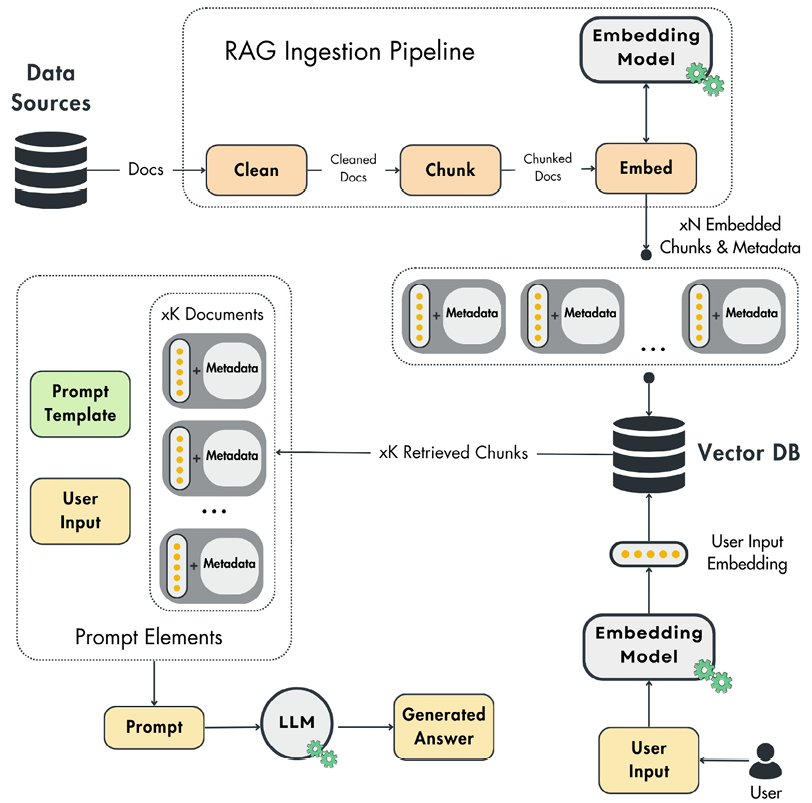
Project Milestones
M1: Environment and Tooling Milestone
This is self explanatory - you need to have at least a docker compose file that will create the development environment for the GraphRAG system.M2: Ingestion Milestone
Here we implement the ingestion pipeline that will ingest multiple media sources such as the course web site, youtube videos related to the course and the slides. The ingestion pipeline should be able to store the raw data in a database of your choice. Ensure you have a notebook cell / markdown file that prints all the URLs that you have ingested either explicitly or via a database query. You can use Mongodb for storing the raw data or simply use files in a directory structure.M3: GraphRAG Construction Milestone
Implement the Knowledge Graph. The KG will have as Nodes the following relations:concept:(id, title, difficulty, aliases, definitions)resource:(type ∈ [pdf, slide, video, web], span, timecodes)example: worked example snippets
prereq_of(u → v)- DAG used by the plannerexplains(resource → concept)exemplifies(example → concept)near_transfer(concept ↔ concept)- siblings, contrasts_with, is_a, part_of
M4: Query and Generation Milestone
Given a user query , turn it into a set of candidate concepts and map those concepts (nodes) into subgraphs that will be used to generate the answer. You can use any method you like to do the mapping and you have to explain the rationale behind your choice. Effectively retrieval is now a subgraph selection problem where the subgraph is a small, semantically coherent neighborhood with:- prerequisite chain(s) to scaffold explanations
- sibling nodes to generate near-transfer checks (although asking questions to the student is optional)
- attached resources / references with exact spans (eg page numbers) and timecodes (video segments).