Introduction
In imitation learning a simulation engine is used to create training datasets. A screenshot of the simulator for the first track is shown below:
Model Architecture and Training Strategy
The model was based on NVIDIA’s work with two preprocessing stages. The original NVIDIA model is shown in the figure below: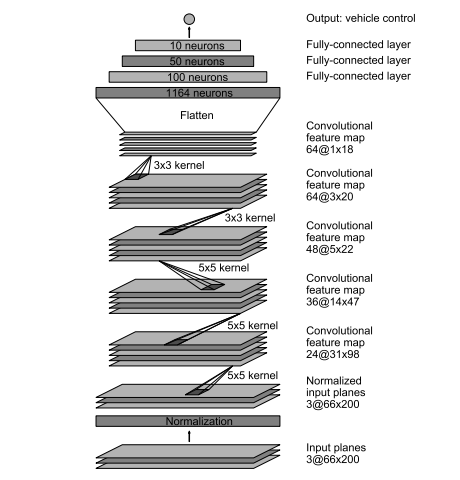
- The preprocessing involved cropping the input images by 30 lines and 20 lines in the top and bottom of all collected images respectively. This was done to eliminate unnecessary for the problem image content.
- Batch normalization for the resulting cropped images was then performed.
Datasets
The training datasets represent in our use case, the correct driving behavior. The dataset collection strategy adopted was as follows:- Initially three complete rounds of track-1 where the vehicle stayed as much as possible in the center of the road were recorded.
- Subsequently the car was positioned such that it faced track-1 in the reverse direction and another three complete rounds of track-1 where recorded.
- In selected turns, the car was positioned in orientations that recovery actions would be taken and the recoveries recorded. Note that only the recoveries where recorded - we have not recorded the deviations from the center of the road as we wanted to teach the network how to recover not how to enter in challenging situations.


 Imitation Learning
Key references: (Ioffe & Szegedy, 2015; Szegedy et al., 2015; Bojarski et al., 2016; Mnih et al., 2013)
Imitation Learning
Key references: (Ioffe & Szegedy, 2015; Szegedy et al., 2015; Bojarski et al., 2016; Mnih et al., 2013)
References
- Bojarski, M., Del Testa, D., Dworakowski, D., Firner, B., Flepp, B., et al. (2016). End to End Learning for Self-Driving Cars.
- Ioffe, S., Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., et al. (2013). Playing Atari with Deep Reinforcement Learning.
- Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z. (2015). Rethinking the Inception Architecture for Computer Vision.