title: Using ConvNets with Small Datasets This section is a PyTorch adaptation of the canonical small-dataset convnet example from Deep Learning with Python (F. Chollet, Chapter 5). We use the
pantelism/cats-vs-dogs dataset hosted on Hugging Face (the same 4,000-image Kaggle
subset used in the original) and demonstrate:
- Baseline: training a small convnet from scratch → clear overfitting with only 2,000 training samples
- Regularization: data augmentation + dropout → substantially lower validation loss and higher accuracy
cats_and_dogs_small.pth for use by the companion
visualization section.
Dataset
pantelism/cats-vs-dogs is a Parquet imagefolder dataset on Hugging Face containing
the 4,000-image Kaggle cats-vs-dogs subset used in the original Chollet notebook.
It has three pre-built splits, train (2,000 images), validation (1,000), and
test (1,000), with a ClassLabel feature mapping 0 → cat and 1 → dog.
We load it directly with load_dataset and wrap it in a lightweight PyTorch Dataset.
Model architecture
We replicate the Chollet convnet, fourConv2d → ReLU → MaxPool2d blocks that
progressively increase depth (32 → 64 → 128 → 128) while halving spatial dimensions
(150 → 74 → 36 → 17 → 7), followed by a fully-connected head.
An optional Dropout(0.5) layer is inserted before the first dense layer for the
regularised variant.
Baseline: training from scratch with no regularisation
We train for 20 epochs with RMSprop and binary cross-entropy loss. With only 2,000 training samples the network overfits quickly: training accuracy climbs to ~95% while validation accuracy plateaus around 70–72%, a textbook overfitting signature.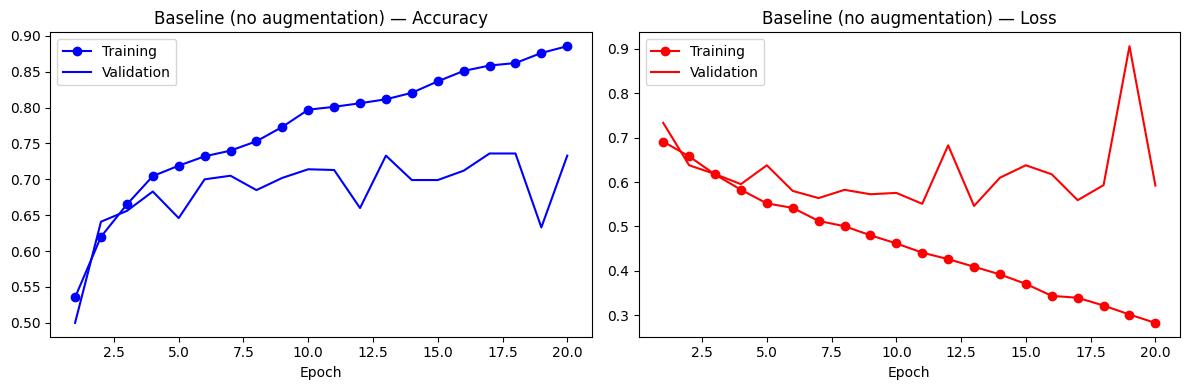
Data augmentation + dropout
Data augmentation generates new views of each training image on-the-fly, random horizontal flips, rotations, translations, shears, and crop-resizes, so the model never sees the exact same pixel pattern twice. Combined withDropout(0.5), this
substantially reduces the train-validation gap characteristic of overfitting.
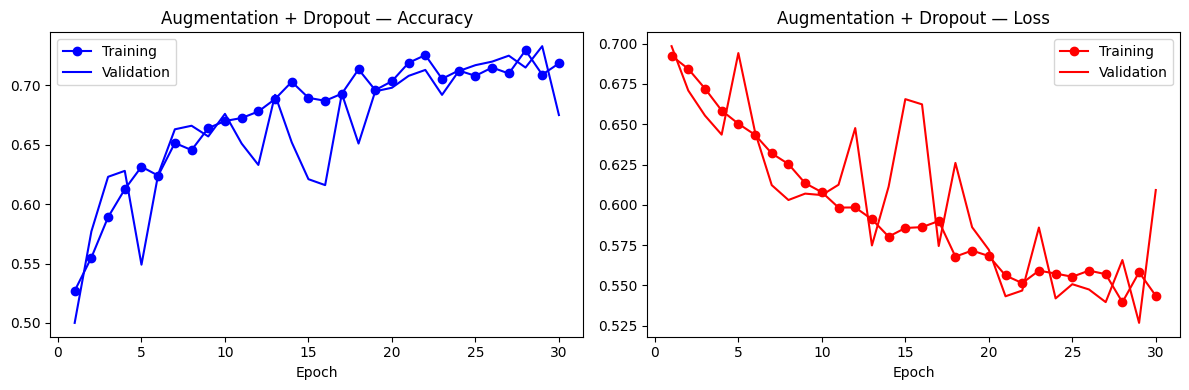
Evaluation on the held-out test set
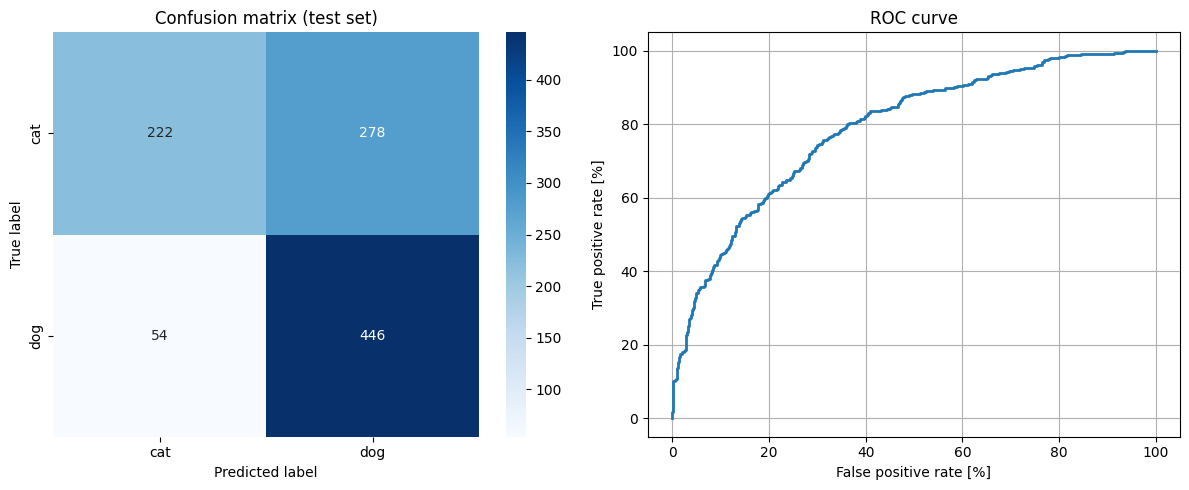
We evaluate the regularised model on the 1,000-image test split and report:- Confusion matrix, to see which mistakes are made
- ROC curve, to characterise the trade-off across thresholds
- Test accuracy, headline metric
cats_and_dogs_small.pth for the companion
visualisation section.