Multi-head self-attention
Earlier we have seen examples with the token bear being in multiple grammatical patterns that also influence its meaning. To capture such multiplicity we can use multiple attention heads where each attention head learns a different pattern such as the three shown in figure below.
Think of the multiple heads in transformer architectures to be analogous to the multiple filters we use in CNNs.
if \(H\) is the number of heads, indexed by \(h\), then each head delivers
\[H_h = \mathtt{Attention}(Q_h, K_h, Vh)\]
where \(Q_h, K_h, V_h\) are the query, key and value matrices of the \(h-th\) head.
\[Q_h = X W_h^q\] \[K_h = X W_h^k\] \[V_h = X W_h^v\]
where \(W_h^q, W_h^k, W_h^v\) are the weight matrices of the \(h-th\) head.
The output of the multi-head attention is then given by
\[\hat X = \mathtt{concat}(H_1, H_2, ..., H_H)W^o\]
where \(W^o\) is the output weight matrix with dimensions \(H d_v \times d\) and typically \(d_v = d/H\).
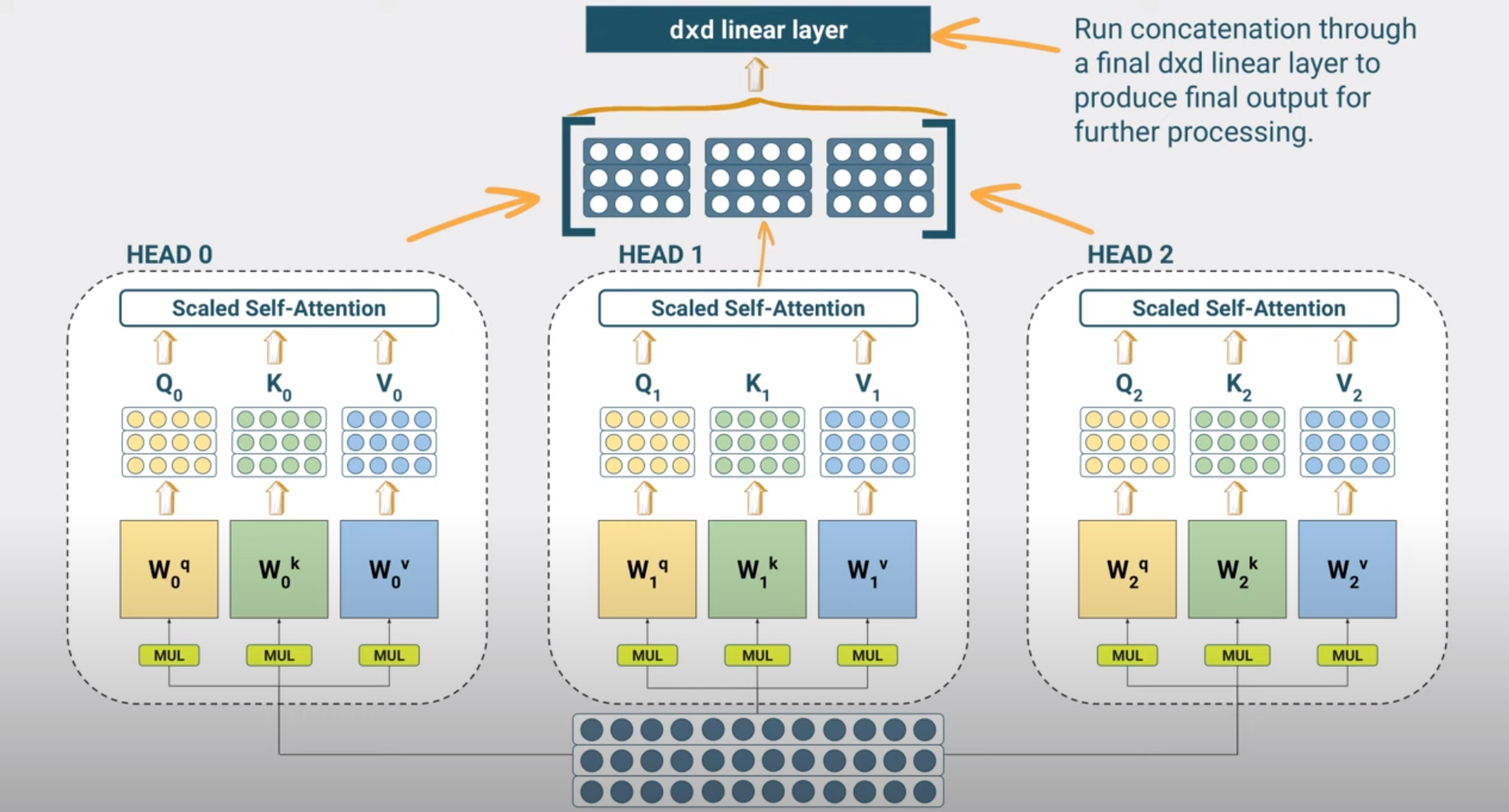
The W^o matrix and the \(W_h^q, W_h^k, W_h^v\) matrices are learned during training. The complexity of running multiple heads does not scale with the number of heads since as you can also see in the code below we divide the head-size by the number of heads, avoiding a corresponding increase in the number of parameters.
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size
num_heads = config.num_attention_heads
head_dim = embed_dim // num_heads
self.heads = nn.ModuleList(
[AttentionHead(embed_dim, head_dim) for _ in range(num_heads)]
)
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, hidden_state):
x = torch.cat([h(hidden_state) for h in self.heads], dim=-1)
x = self.output_linear(x)
return xAttention Blocks with Skip Connections
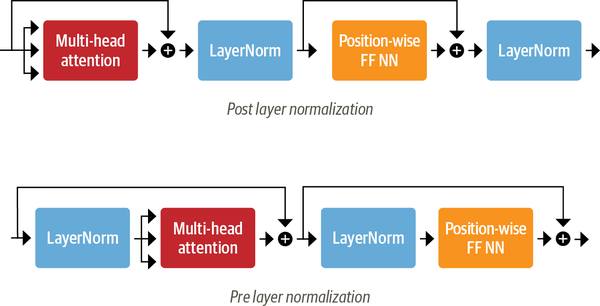
Layer Normalization has been shown to improve training efficiency and therefore we apply layer normalization to the input of the multihead self attention (MHSA).
\[Z = \mathtt{LayerNorm}(\hat X)\]
In addition we borrow the same idea we have seen from ResNet, and add a skip connection from the input to the output of the MHSA.
\[\hat Z = \mathtt{MHSA}(Z) + \hat X\]
We call the above block an attention block and since we know that depth helps in representations learning, we therefore want to stack multiple attention blocks, but before we do so we apply a feedforward layer to the output of each attention block for the reasons we describe below.
Multilayer Perceptron (MLP)
Notice that at its core the output of the multihead self attention is a weighted sum of the input tokens. This is a linear combination of the value vectors and the attention block does not have the capacity to learn non-linear relationships. One cat argue that the attention weights and softmax add some non-linearity but this is not enough and the model will not be able to learn complex dependencies. To address this we add an MLP to the output of the multihead self attention.
\[Y = \mathtt{LayerNorm}(\hat Z)\]
\[\tilde X = \mathtt{MLP}(Y) + \hat Z\]
where the MLP uses skip connection and for some implementations a RELU or GELU activation function shown below is used.
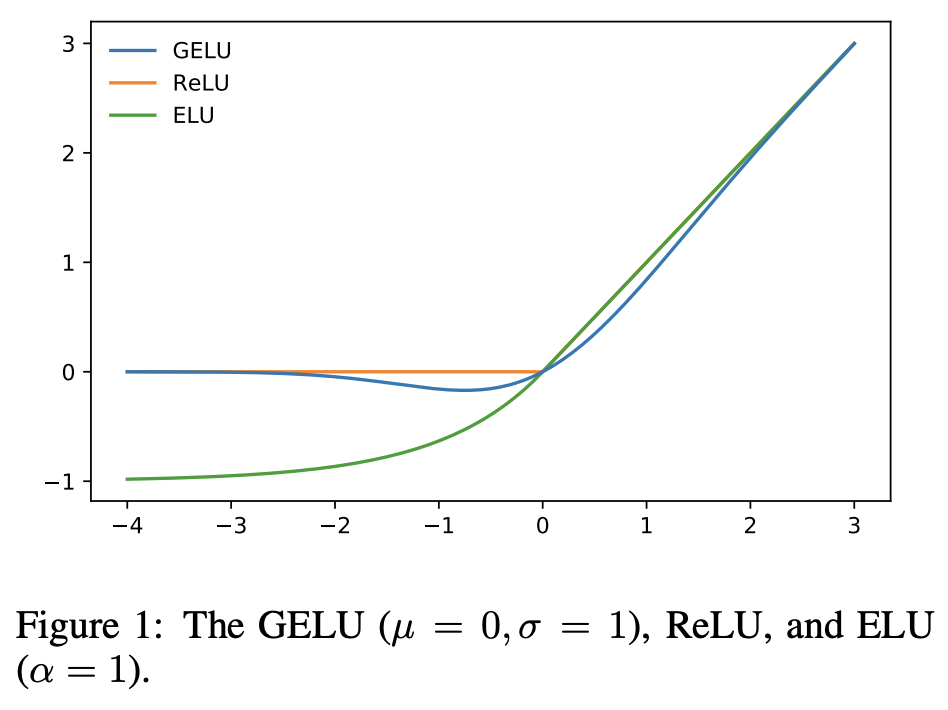
Notably, each token is processed by the MLP independently of the other tokens in the input.
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.linear_2(x)
x = self.dropout(x)
return x