In case you have forgotten the basics of calculus, please review the calculus section before proceeding.
Calculating the Gradient of a Function
Our goal is to compute the components of the gradient of the function where, The computational graph of this function is shown below. Its instructive to print this graph and pencil in all calculations for both this example and others in the backpropagation section. One derivative that we will be using that is not often listed is the derivative of the sigmoid function. The sigmoid derivative can be obtained as follows: Consider Then, on the one hand, the chain rule gives and on the other hand, Equating the two expressions we finally obtain,
Forward Pass
In the forward pass, the algorithm works bottom up (or left to right depending how the computational graph is represented) and calculates the values of all “gates” (gates are the elementary functions that synthesize the function) of the graph and stores their values into variables as they will be used by the backwards pass. There are eight values stored in this specific example.Backwards Pass
In the backwards pass, we reverse direction and start at the top or rightmost node (the stored variables) of the graph and compute the input (in the reverse direction) derivative of input of each gate using the template depicted below: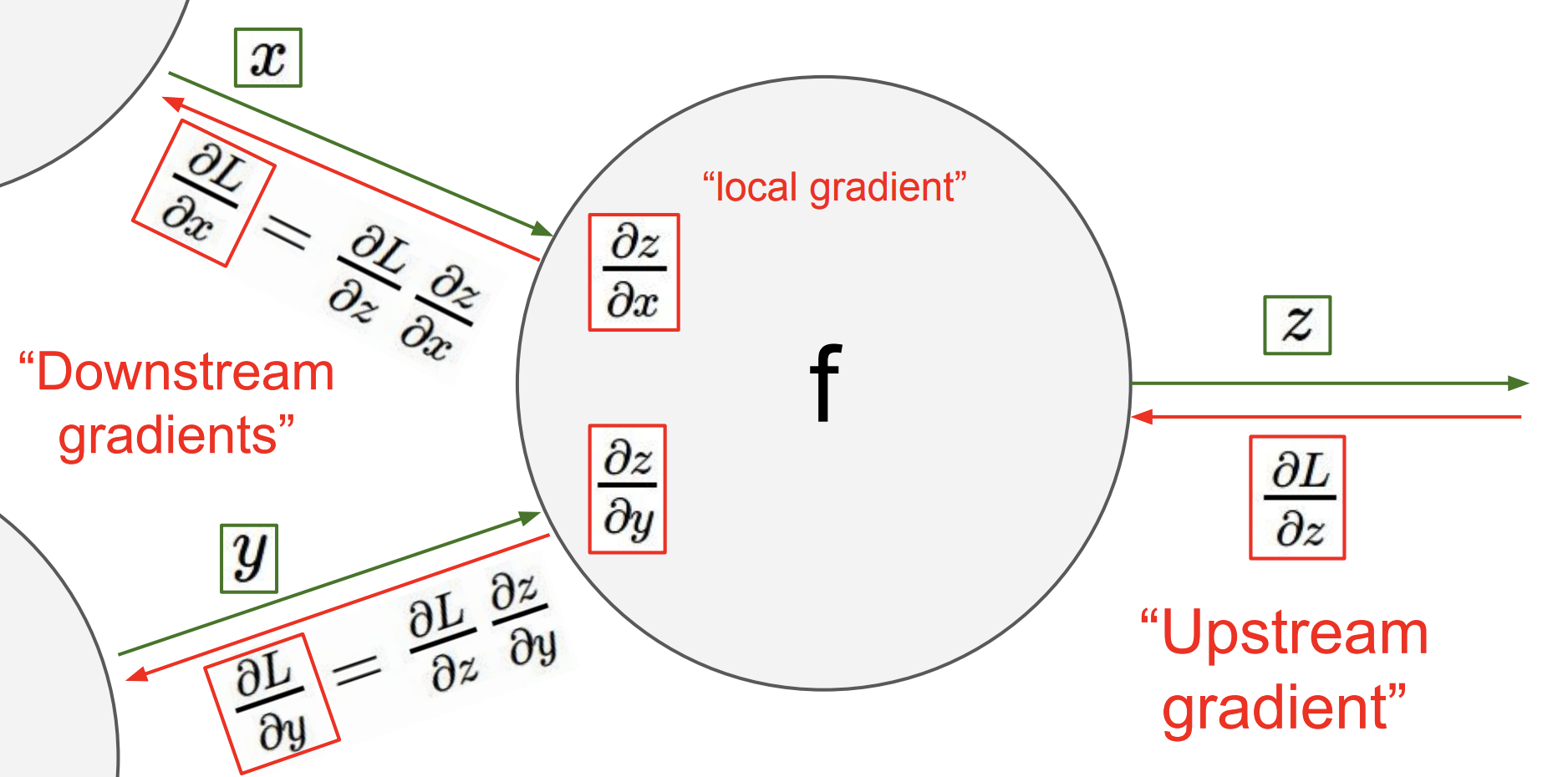

Key references: (Bengio, 2012; Choromanska et al., 2014; Romero et al., 2014; Srivastava et al., 2015; Lin et al., 2016)
References
- Bengio, Y. (2012). Practical recommendations for gradient-based training of deep architectures.
- Choromanska, A., Henaff, M., Mathieu, M., Ben Arous, G., LeCun, Y. (2014). The Loss Surfaces of Multilayer Networks.
- Lin, H., Tegmark, M., Rolnick, D. (2016). Why does deep and cheap learning work so well?.
- Romero, A., Ballas, N., Kahou, S., Chassang, A., Gatta, C., et al. (2014). FitNets: Hints for Thin Deep Nets.
- Srivastava, R., Greff, K., Schmidhuber, J. (2015). Highway Networks.