
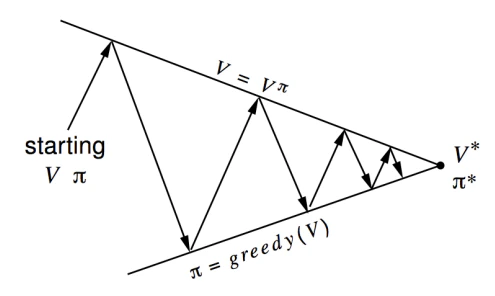
- In the policy evaluation (also called the prediction) step we estimate the state value function .
- In the policy improvement (also called the control) step we apply the greedy heuristic and elect a new policy based on the evaluation of the previous step.
Gridworld policy iteration example
The grid world example shown below is characterized by:- Not discounted episodic MDP (γ = 1)
- Non terminal states 1, …, 14
- One terminal state (shown twice as shaded squares)
- The action that the agent takes, cause the intended state transition with probability 1.0. Actions leading out of the grid leave state unchanged.
- Reward is −1 until the terminal state is reached
- Agent follows a uniform random policy

- The terminal states are shaded. The reward is on all transitions until the terminal states are reached. The non-terminal states are .
- We begin with random values (or 0.0) and a random policy

Policy Evaluation
- Find value function based on initial random policy:
- The result is as shown below:

Policy Improvement
- Next we compute the policy:

Run the Policy Iteration Demo
Open the policy iteration gridworld notebook in Google Colab to implement this algorithm.
References
- Ahmed, Z., Le Roux, N., Norouzi, M., Schuurmans, D. (2018). Understanding the impact of entropy on policy optimization.
- Ma, S., Yu, J. (2016). Transition-based versus State-based Reward Functions for MDPs with Value-at-Risk.
- Mansour, Y., Singh, S. (2013). On the Complexity of Policy Iteration.
- Ross, S., Gordon, G., Andrew Bagnell, J. (2010). A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning.
- Schulman, J., Levine, S., Moritz, P., Jordan, M., Abbeel, P. (2015). Trust Region Policy Optimization.