Intuition
The BLEU algorithm evaluates the precision score of a candidate machine translation against a reference human translation. The reference human translation is a assumed to be a model example of a translation, and we use n-gram matching as our metric for how similar a candidate translation is to it. Why simple precision can’t be used? Consider the following example of poor machine translation output with high precision metric using unigrams.
Of the seven words in the candidate translation, all of them appear in the reference translations. Thus the candidate text is given a unigram precision of,
where is number of words from the candidate that are found in the reference, and is the total number of words in the candidate. This is a perfect score, despite the fact that the candidate translation above retains little of the content of either of the references.
The modification that BLEU makes is fairly straightforward. For each word in the candidate translation, the algorithm takes its maximum total count, , in any of the reference translations. In the example above, the word “the” appears twice in reference 1, and once in reference 2. Thus .
For the candidate translation, the count of each word is clipped to a maximum of for that word. In this case, “the” has and thus is clipped to 2. These clipped counts are then summed over all distinct words in the candidate. This sum is then divided by the total number of unigrams in the candidate translation. In the above example, the modified unigram precision score would be:
More formally, the BLUE score is a cumulative score that refers to the calculation of individual n-gram scores at all orders from 1 to n and weighs them by calculating the weighted geometric mean, i.e.
where the brevity penalty considers the length of the reference (R) and candidate (C) sentences.
and is the n-gram precision.
You can remember BLUE by drawing the diagram we saw in binary classification metrics
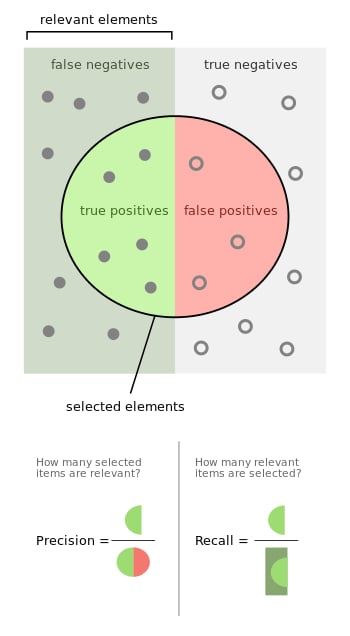
BLUE is concerned with the first two rows and calculates the n-gram precision as the usual ratio of the counts .