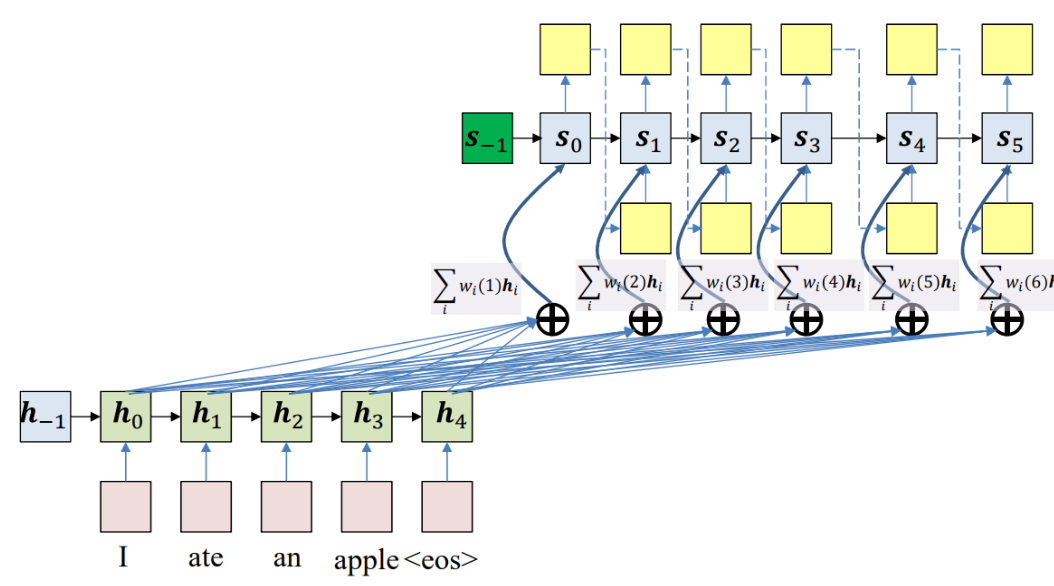
- During encoding the output of bidirectional LSTM encoder can provide the contextual representation of each input word . Let the encoder hidden vectors be denoted as where is the length of the input sentence.
- During decoding we compute the RNN decoder hidden states using a recursive relationship,
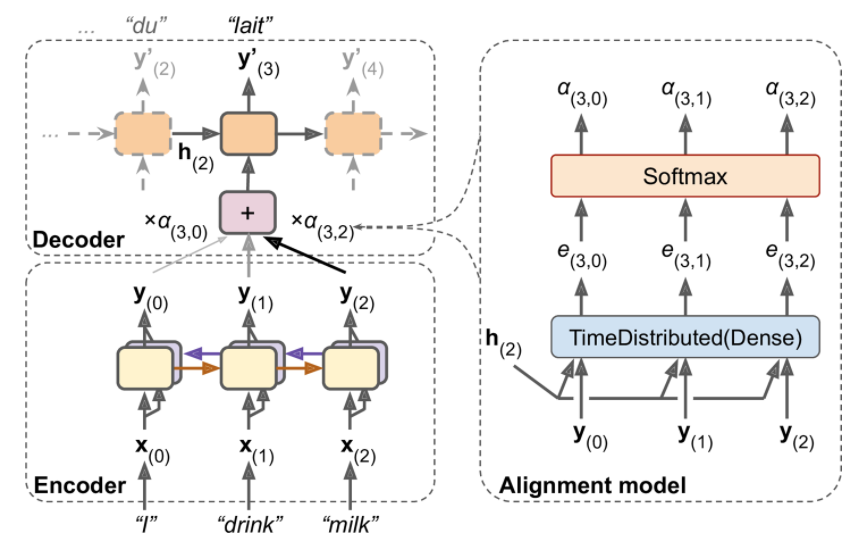
- For each hidden state from the source sentence (key), is the sequence index of the encoder hidden state, we compute a score
- The score values are normalized using a softmax layer to produce the attention weight vector . All the weights for a given decoder time step add up to 1.
- The context vector is then the attention weighted average of the hidden state vectors (values) from the original sentence.
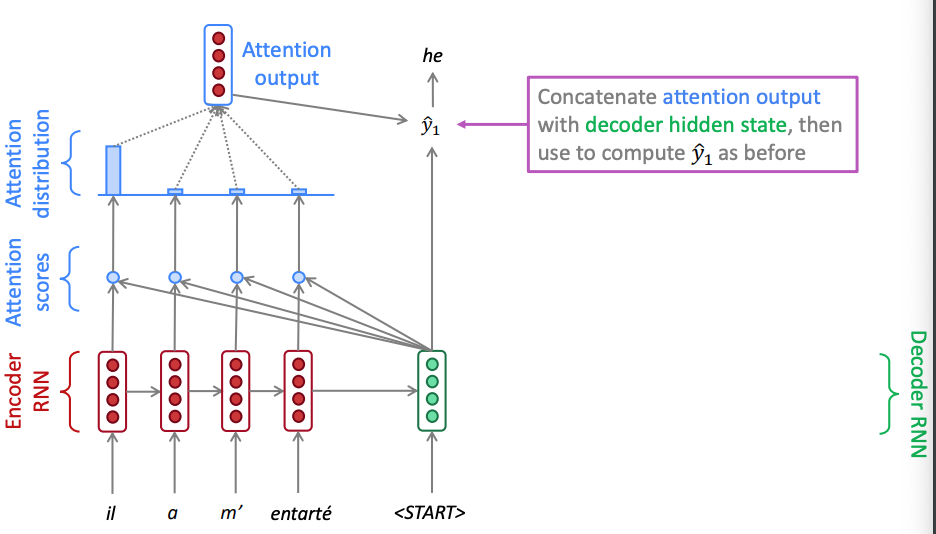
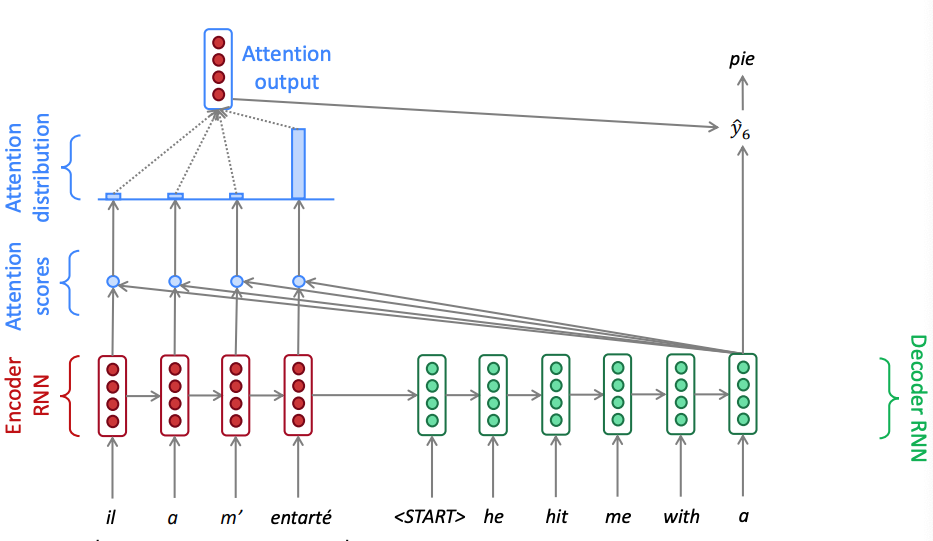
Scoring functions
There are multiple attention mechanisms and typically the Bahdanau attention is often quoted. It implements a fully connected neural network in the scoring function that adds the projected encoder and decoder hidden states (additive attention): During the decoding step it concatenates the encoder output with the decoder’s previous hidden state and this is why sometimes is also called concatenative attention. There is alsp multiplicative attention that uses a dot product between encoder and decoder hidden states and there is also a Luong attention that uses a linear unit for scoring. Note that in this case we use the current decoder hidden state. Notice that the there is no concatenation during the decoding step. In the workshop we will use the multiplicative attention mechanism.PyTorch reference
Key references: (Luong et al., 2015; Sennrich et al., 2015; Cho et al., 2014; Wiseman & Rush, 2016; Zaremba et al., 2014)
References
- Cho, K., Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., et al. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.
- Luong, M., Pham, H., Manning, C. (2015). Effective Approaches to Attention-based Neural Machine Translation.
- Sennrich, R., Haddow, B., Birch, A. (2015). Neural Machine Translation of Rare Words with Subword Units.
- Wiseman, S., Rush, A. (2016). Sequence-to-Sequence Learning as Beam-Search Optimization.
- Zaremba, W., Sutskever, I., Vinyals, O. (2014). Recurrent Neural Network Regularization.