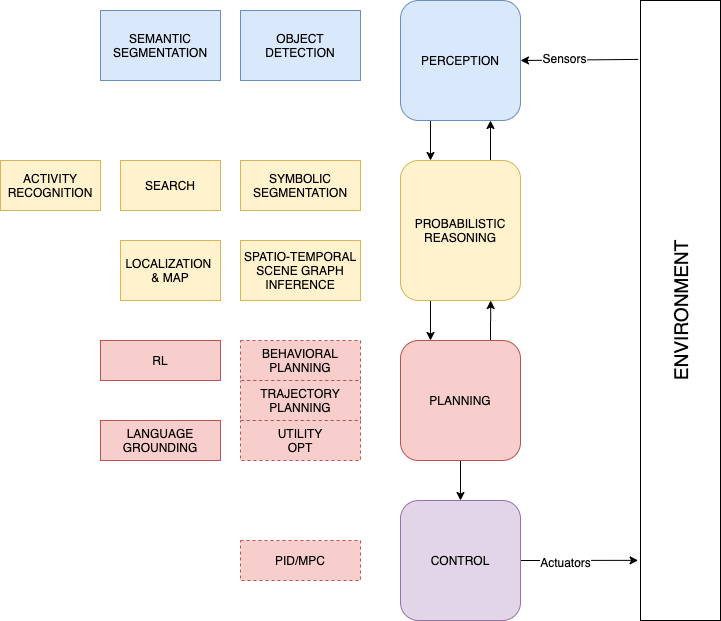
- Introduce the concept of state that encapsulates multiple random variables and consider dynamical systems with non-trivial non-linear dynamics (state transition models) common in robotics and many other fields.
- Introduce the time index explicitly in the aforementioned state evolution as represented via a graphical model.
The Bayesian Filter
We are introducing this algorithm, by considering a embodied agent (a robot) that moves in an environment.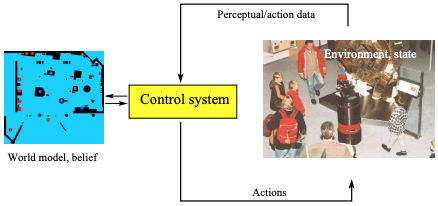
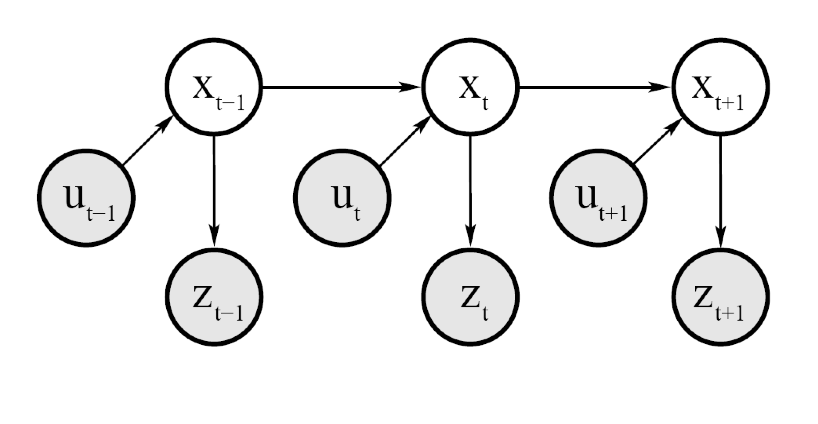
(b) the measurement update step that that weighs the belief with the probability that measurement was observed. Bayes Filter
= bayes_filter( for all do: (prediction) (measurement update) endfor
Door state estimation
To illustrate how the Bayes filter is useful, lets look at a practical example. This example was borrowed from Sebastian Thrun’s book, “Probabilistic Robotics”, MIT Press, 2006. The problem we are considering is estimating the state of a door using an agent (robot) equipped with a monocular camera.
Measurement Model
No real agent has ideal sensing abilities so the sensor or measurement model is noisy and lets assume for simplicity that its given by:
The values in the measurement model above are not necessarily chosen randomly as computer vision algorithms (or LIDAR) may find it easier to detect a closed door from an open door, since with an open door the camera sees the clutter inside the room and the LIDAR may confuse the clutter returns with a closed door.
Transition Model
Lets also assume that the agent is using a arm manipulator to push the door open if its closed. Note So we have the following transition distribution:
As we mentioned before, by convention the agent first acts and then senses. If you reverse sensing and action you arrive in the same equations with just some index differences.
Lets assume that at , the agent takes no action but senses the door is open. The two steps of RSE are as follows:
Recursive State Estimation at - Step 1: Prediction
For all possible values of the state variable we have The fact that the belief at this point equals the prior belief (stored in the agent) is explained from the fact that inaction shouldn’t change the environment state and the environment state does not change itself over time in this specific case.Recursive State Estimation at - Step 2: Measurement Update
In this step we are using the perception subsystem to adjust the belief with what it is telling us: For the two possible states at we have The normalizing factor can now be calculated: . Therefore:Recursive State Estimation at - Step 1: Prediction
In the next time step lets assume that the agent pushes the door and senses that its open. Its easy to verify thatRecursive State Estimation at - Step 2: Measurement Update
and with we can estimate the posterior belief for . This example, although simplistic is indicative of the ability of the Bayes filter to incorporate perception and action into one framework. Although the example was for an embodied agent with a manipulator, the notion of action is optional. Beliefs can be recursively updated even if the action is not taken explicitly by the agent. Your cell phones have the ability to localize themselves using exactly the same Bayesian filter with different sensing (RF signals) despite the fact that they don’t move by themselves but are carried by you in their environment. Key references: (Bottou, 2011; Ali Eslami et al., 2016; Schmidhuber, 2015; McGregor et al., 2015)References
- Ali Eslami, S., Heess, N., Weber, T., Tassa, Y., Szepesvari, D., et al. (2016). Attend, Infer, Repeat: Fast Scene Understanding with Generative Models.
- Bottou, L. (2011). From Machine Learning to Machine Reasoning.
- McGregor, S., Baltieri, M., Buckley, C. (2015). A Minimal Active Inference Agent.
- Schmidhuber, J. (2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models.