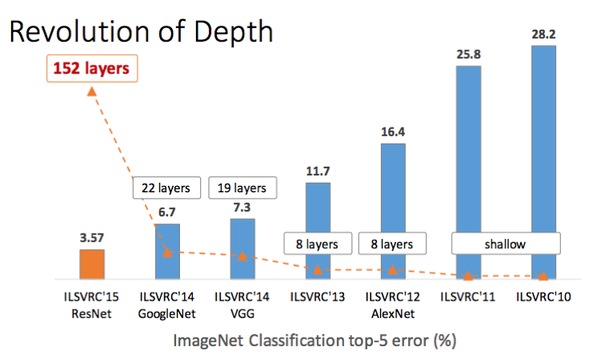
In the figure below we plot the top-5 classification error as a function of depth in CNN architectures. Notice the big jump due to the introduction of the ResNet architecture.
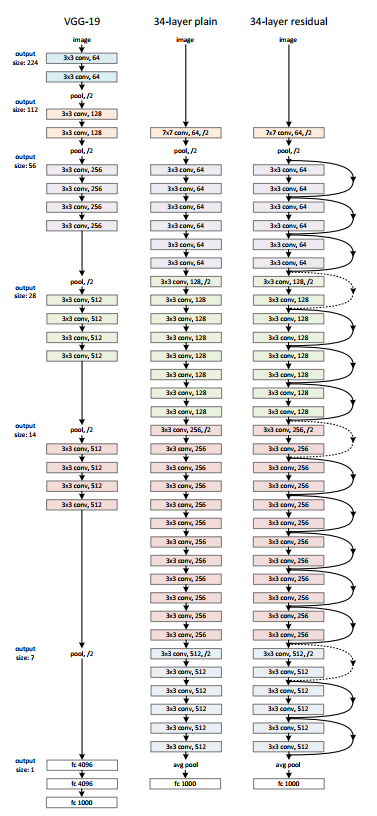
The ResNet Architecture
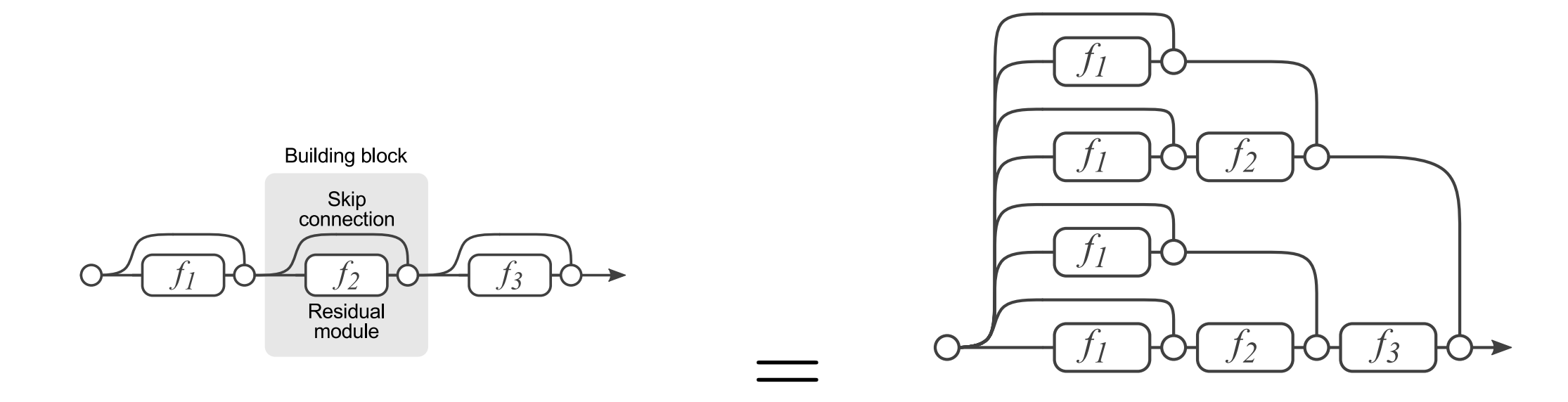
Performance advantages of ResNets
Hinton showed that using dropout, dropping out individual neurons during training, leads to a network that is equivalent to averaging over an ensemble of exponentially many networks.We now show that similar ensemble learning performance advantages are present in residual networks. To do so, we use a simple 3-block network where each layer consists of a residual module and a skip connection bypassing . Since layers in residual networks can comprise multiple convolutional layers, we refer to them as residual blocks. With as is input, the output of the i-th block is recursively defined as where is some sequence of convolutions, batch normalization, and Rectified Linear Units (ReLU) as nonlinearities. In the figure above we have three blocks. Each is defined by where and are weight matrices, · denotes convolution, is batch normalization and . Other formulations are typically composed of the same operations, but may differ in their order. This paper analyses the unrolled network and from that analysis we conclude on mainly three advantages of the architecture:- We see many diverse paths to the gradient as it flows from the to the trainable parameter tensors of each layer.
- We see elements of ensemble learning in the formation of the hypothesis .
- We can eliminate layers from the architecture (blocks) without having to redimension the network, allowing us to trade performance for latancy during inference.
ResNets and Batch Normalization
This notebook is very instructive of what now is considered a canonical new ResNet block that includes batch normalization. Key references: (Zagoruyko & Komodakis, 2016; He et al., 2015; Szegedy et al., 2016; Veit et al., 2016; Xie et al., 2016)References
- He, K., Zhang, X., Ren, S., Sun, J. (2015). Deep Residual Learning for Image Recognition.
- Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A. (2016). Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning.
- Veit, A., Wilber, M., Belongie, S. (2016). Residual Networks Behave Like Ensembles of Relatively Shallow Networks.
- Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K. (2016). Aggregated Residual Transformations for Deep Neural Networks.
- Zagoruyko, S., Komodakis, N. (2016). Wide Residual Networks.