Computing the value functions given a policy
In this section we describe how to calculate the value functions by establishing a recursive relationship similar to the one we did for the return. We replace the expectations with summations over quantities such as states and actions. Lets start with the state-value function that can be written as,All above expectations are with respect to policy . In addition there is some missing details in the above derivation.
- The immediate reward,
- The discounted value of the successor state .
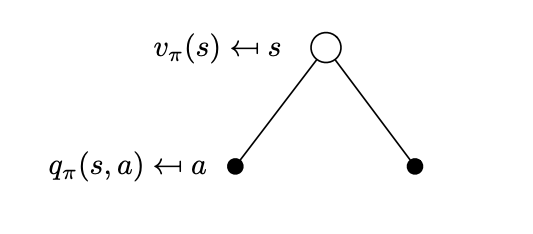
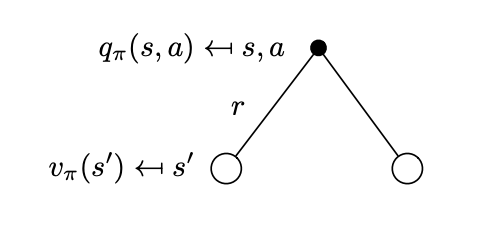
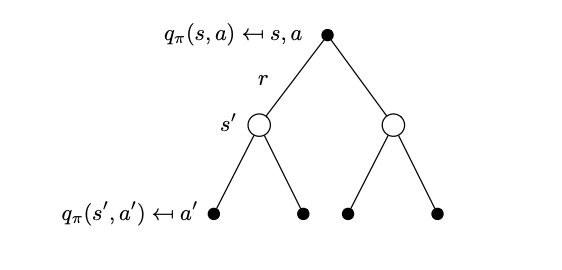
Bellman State-Action Value Expectation Equation
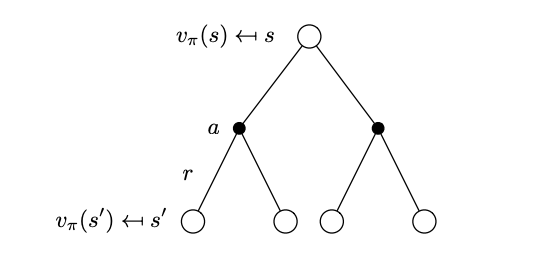
Bellman State Value Expectation Equation
In the compact form (2nd line of the equation) we denote:
References
- Li, Y. (2017). Deep Reinforcement Learning: An Overview.
- Ma, S., Yu, J. (2016). Transition-based versus State-based Reward Functions for MDPs with Value-at-Risk.
- Mansour, Y., Singh, S. (2013). On the Complexity of Policy Iteration.
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., et al. (2013). Playing Atari with Deep Reinforcement Learning.
- Tamar, A., Wu, Y., Thomas, G., Levine, S., Abbeel, P. (2016). Value Iteration Networks.