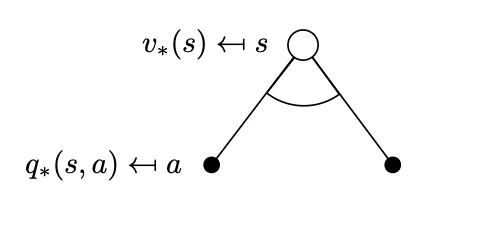
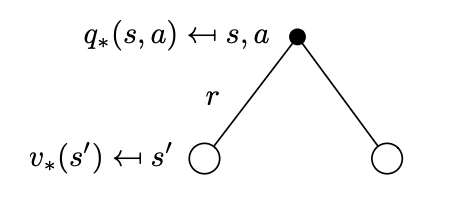
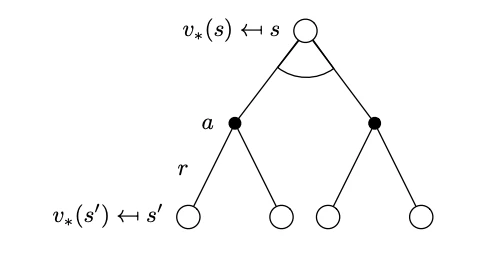
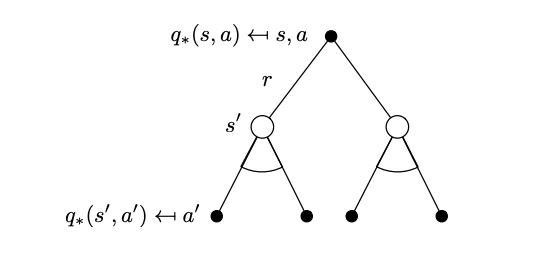
Bellman Optimality BackupThese equations due to the operator are non-linear and can be solved to obtain the MDP solution aka iteratively via a number of methods: policy iteration, value iteration, Q-learning, SARSA. We will see some of these methods in detail in later chapters. The key advantage in the Bellman optimality equations is efficiency:
- They recursively decompose the problem into two sub-problems: the subproblem of the next step and the optimal value function in all subsequent steps of the trajectory.
- They cache the optimal value functions to the sub-problems and by doing so we can reuse them as needed.