- optimally act in very large known MDPs or
- optimally act when we don’t know the MDP functions.
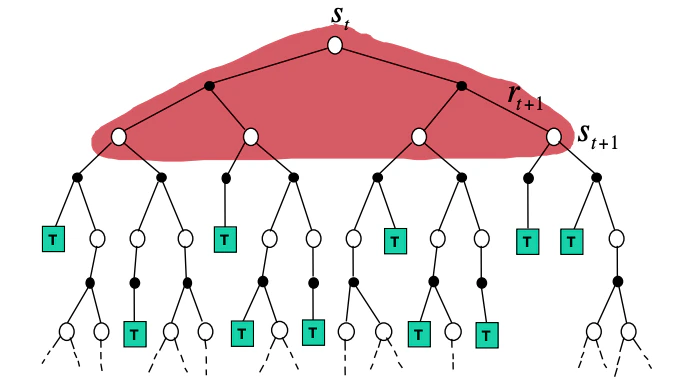
Future value calculation
Two natural questions arise- With what future states and actions we estimate the values,
- How we control / schedule the updates to the values such that we can converge in an optimal policy at some point.
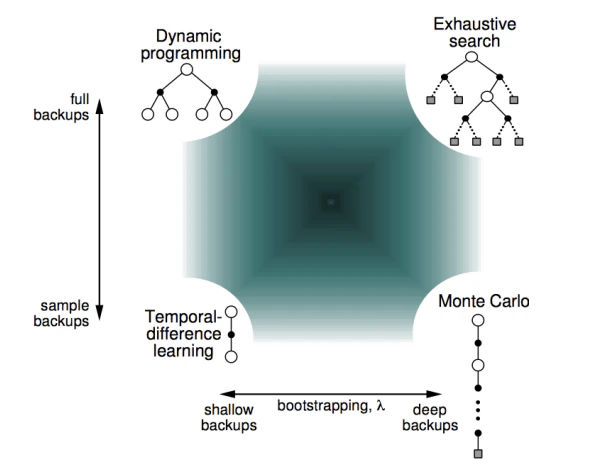
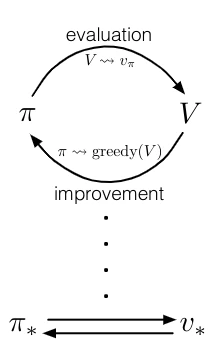
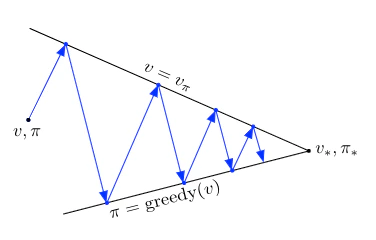
From GPI to modern RL algorithms
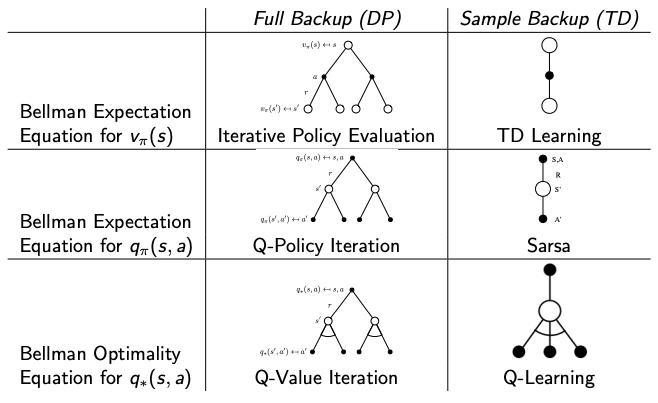
Three families of updates fit inside the GPI skeleton, and they differ along two orthogonal axes, width (full expectation vs. single sample) and depth (one step with bootstrapping vs. all the way to the end of the episode):| Bootstraps (one step, then plug in estimate) | Does not bootstrap (uses full return) | |
|---|---|---|
| Full width (expectation over ) | Dynamic programming, requires a known model | , (exhaustive tree search) |
| Sample width (one drawn from env) | Temporal-difference (TD), Q-learning, SARSA | Monte Carlo (MC), REINFORCE, MC control |
- DP uses full backups: it sweeps every successor and weights by the known . Requires a model.
- MC uses sample backups but waits for the episode to terminate and uses the actual return . Model-free, unbiased, high variance.
- TD uses sample backups and bootstraps: one step of real experience plus the current estimate of or at the next state. Model-free, biased, low variance.

Deep RL
To scale to large problems, we also need to develop approaches that can learn such functions efficiently both in terms of computation and space (memory). We will use DNNs to provide, in the form of approximations, the needed efficiency boost.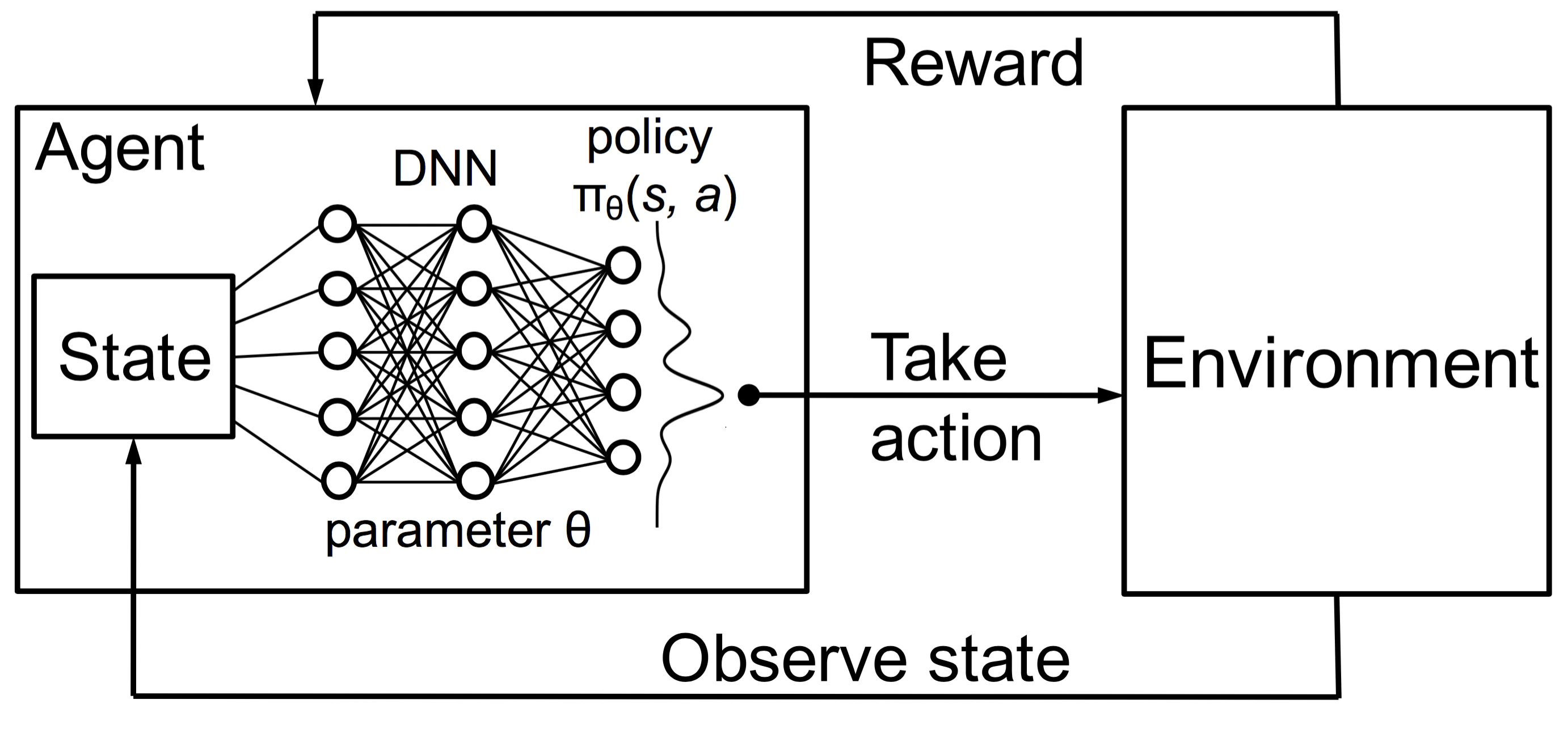
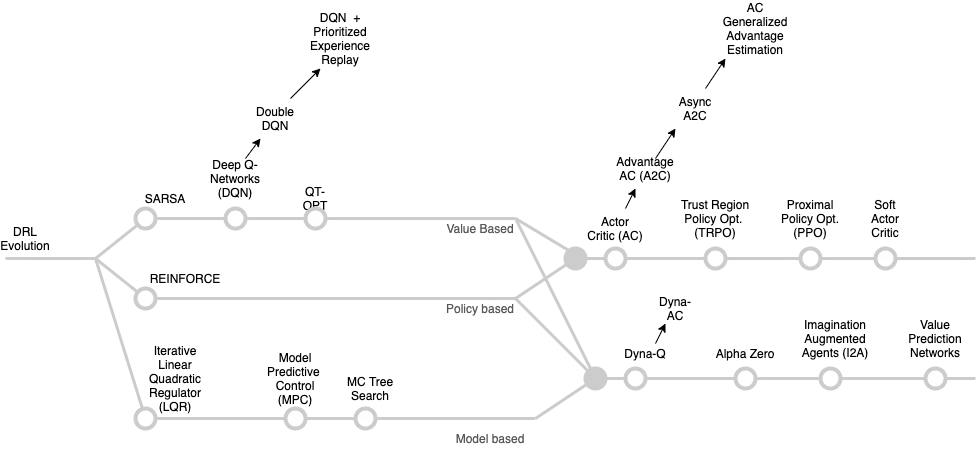
Resources
The reader is encouraged to explore the following resources to get a better understanding of the DRL landscape.- Spinning Up in Deep RL. This is a must read for all computer scientists that are getting started in Deep RL.
- Foundations of Deep RL. This is a practical book available for free via the O’Reilly .
References
- Li, X., Li, L., Gao, J., He, X., Chen, J., et al. (2015). Recurrent Reinforcement Learning: A Hybrid Approach.
- Ma, S., Yu, J. (2016). Transition-based versus State-based Reward Functions for MDPs with Value-at-Risk.
- Schmidhuber, J. (2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models.
- Tamar, A., Wu, Y., Thomas, G., Levine, S., Abbeel, P. (2016). Value Iteration Networks.
- Tamar, A., Wu, Y., Thomas, G., Levine, S., Abbeel, P. (2016). Value Iteration Networks.