- The first is a technique for learning the Q-function via TD-learning that we have seen in the prediction section.
- The second is a method for evolving the policy using the learned Q-function.
SARSA - TD Learning
In the TD prediction section, we have met the TD prediction step for but for control we need to predict the . The TD(0), also known as single-step TD, tree for SARSA is shown below: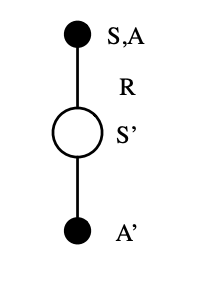

References
- Ma, S., Yu, J. (2016). Transition-based versus State-based Reward Functions for MDPs with Value-at-Risk.
- O’Donoghue, B., Munos, R., Kavukcuoglu, K., Mnih, V. (2016). Combining policy gradient and Q-learning.
- Rafati, J., Noelle, D. (2019). Learning sparse representations in reinforcement learning.
- Szepesvári, C., Cochran, J., Cox, L., Keskinocak, P., Kharoufeh, J., et al. (2010). Reinforcement Learning Algorithms for MDPs. Wiley Encyclopedia of Operations Research and Management Science.
- Tu, S., Recht, B. (2018). The Gap Between Model-Based and Model-Free Methods on the Linear Quadratic Regulator: An Asymptotic Viewpoint.