- (incremental) Monte-Carlo (MC) and
- Temporal Difference (TD).
Monte-Carlo (MC) State Value Prediction
In MC prediction, value functions and are estimated purely from the experience of the agent across multiple episodes. For example, if an agent follows policy and maintains an average, for each state encountered, the actual return that have followed that state (retrievable at the end of each episode), then the average will converge to the state’s value,, as the number of times that state is encountered approaches infinity. If separate averages are kept for each action taken in each state, then these averages will similarly converge to the action values,. We call estimation methods of this kind Monte Carlo methods because they involve averaging over many random samples of returns. In MC prediction, more specifically, for every state at time we sample one complete trajectory (episode) as shown below.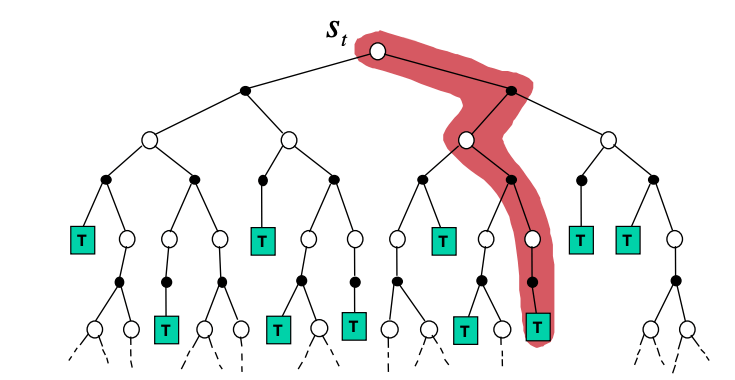
- For each time step that state is visited in an episode
- Increment a counter that counts the visitations of the state
- Calculate the total return
- At the end of multiple episodes, the value is estimated as
References
- Ma, S., Yu, J. (2016). Transition-based versus State-based Reward Functions for MDPs with Value-at-Risk.
- Mansour, Y., Singh, S. (2013). On the Complexity of Policy Iteration.
- Ross, S., Gordon, G., Andrew Bagnell, J. (2010). A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O. (2017). Proximal Policy Optimization Algorithms.
- Weber, T., Racanière, S., Reichert, D., Buesing, L., Guez, A., et al. (2017). Imagination-Augmented Agents for Deep Reinforcement Learning.