System Architecture
The system integrates several components into a cohesive educational AI platform:User Interface
A chat application provides the interaction layer, handling text input from students and displaying generated answers with citations. The interface connects to the LLM server and GraphRAG retrieval system to deliver contextual responses.LLM Server
The system runs on local inference servers (Ollama or LM Studio) using the Qwen2.5 model for reasoning and generation. For environments without sufficient local compute, the architecture supports remote API access through OpenRouter while maintaining the same interface.GraphRAG Architecture
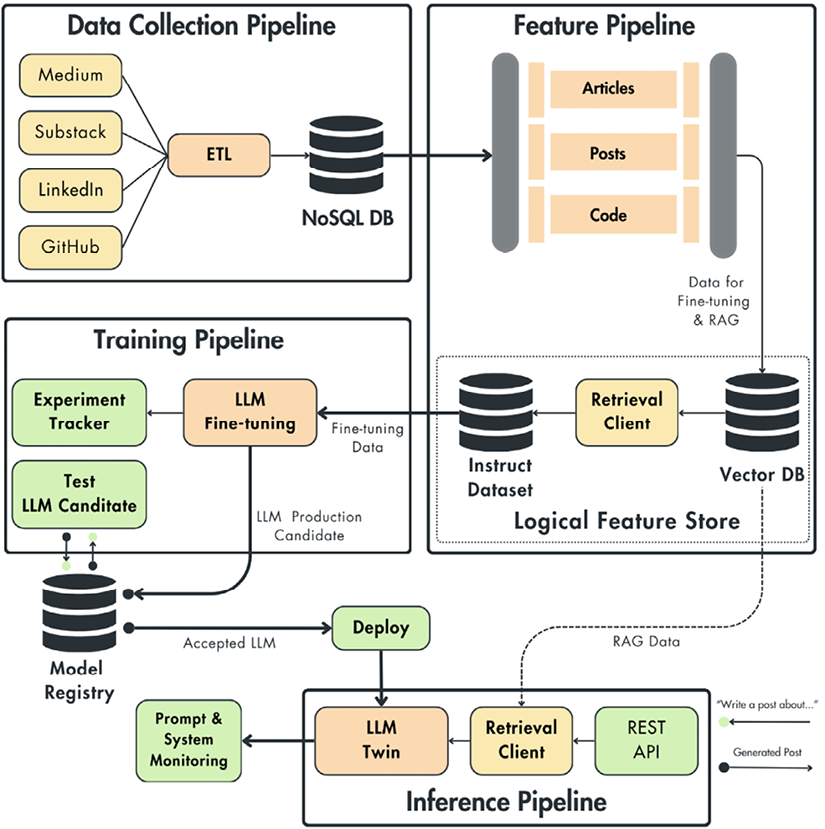
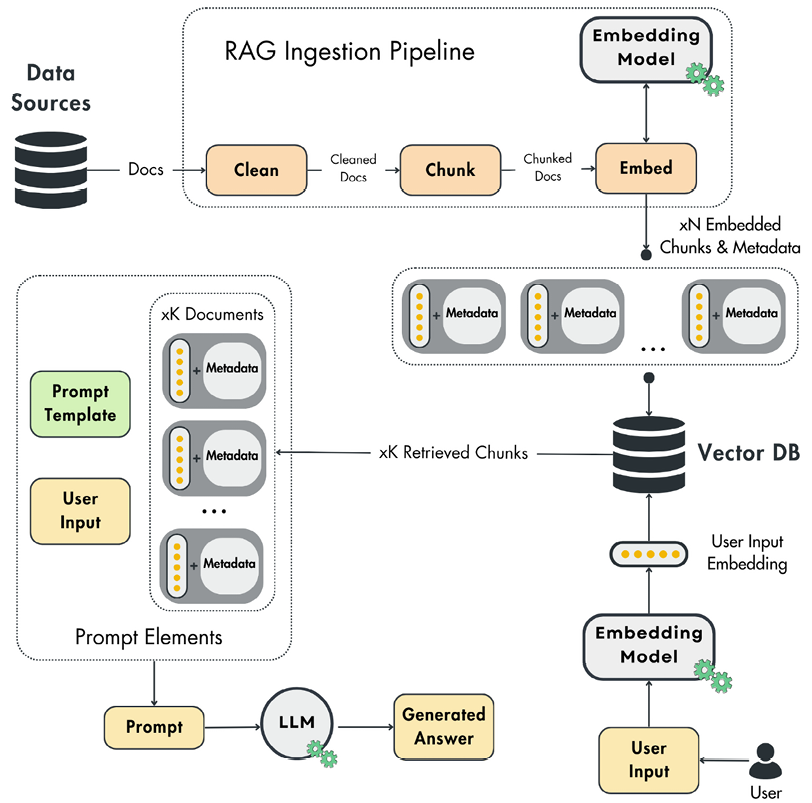
Knowledge Graph Schema
The knowledge graph employs a pedagogically-informed schema designed to support educational interactions:Nodes
- Concept:
(id, title, difficulty, aliases, definitions)- Core learning concepts with metadata - Resource:
(type ∈ [pdf, slide, video, web], span, timecodes)- Course materials with precise references - Example: Worked example snippets demonstrating concept application
Edges
- prereq_of(u → v): Prerequisite relationships forming a directed acyclic graph (DAG) for concept scaffolding
- explains(resource → concept): Links resources to the concepts they explain
- exemplifies(example → concept): Connects examples to their target concepts
- near_transfer(concept ↔ concept): Semantic relationships including siblings, contrasts, is-a, and part-of relations
Data Ingestion Pipeline
The system ingests multiple media sources into a unified knowledge base:- Course Website: Structured content, navigation, and article text
- YouTube Videos: Lecture content with automatic transcription and timecode mapping
- Slide Decks: Presentation materials with concept extraction
Query Processing and Generation
When a user submits a query, the system transforms it into a retrieval problem over the knowledge graph:- Concept Mapping: The query is analyzed to identify candidate concepts
- Subgraph Selection: Relevant concepts are expanded into coherent subgraphs containing:
- Prerequisite chains to scaffold explanations from fundamentals
- Sibling nodes for generating near-transfer comprehension checks
- Attached resources with exact spans (page numbers) and timecodes (video segments)
- Answer Generation: The LLM synthesizes responses following prerequisite chains, progressing from simpler to more complex concepts
- Citation Provision: Each answer includes graph nodes used and resource references
Demonstrated Capabilities
The system showcases advanced educational AI through several example queries:Query 1: Attention in Transformers
Question: “What is attention in transformers and can you provide a python example of how it is used?” Response Characteristics:- Explains dot-product self-attention mechanism
- Clarifies the reasoning behind Q (Query), K (Key), V (Value) vectors
- Provides executable Python code demonstrating attention computation
- Includes citations to course resources with specific page/slide references
Query 2: CLIP Model
Question: “What is CLIP and how it is used in computer vision applications?” Response Characteristics:- Explains dual encoders for text and image modalities
- Describes contrastive loss principle and optimization
- Details dot-product similarity computation
- Demonstrates one-shot classification capabilities
- Links to relevant video timecodes and paper references
Query 3: Variational Lower Bound
Question: “Can you explain the variational lower bound and how it relates to Jensen’s inequality?” Response Characteristics:- Establishes prerequisite understanding of Jensen’s inequality
- Explains variational methods and their mathematical foundations
- Shows how variational autoencoder (VAE) losses employ Jensen’s inequality
- Follows prerequisite chain from probability theory to VAE implementation
- Provides worked examples and resource citations
Technical Implementation
Each response includes transparency features for educational verification:- Knowledge Graph Nodes: Lists specific concepts, resources, and examples retrieved from the graph
- Resource Citations: Provides precise references (page numbers, slide numbers, video timecodes)
- System Prompt Visibility: Exposes the system prompt used for generation (questions are not modified)
- Prerequisite Scaffolding: Visually indicates the concept chain used to structure the explanation
Applications
Erica demonstrates practical applications of GraphRAG in education:- Adaptive Tutoring: Responses adjust to prerequisite knowledge and concept difficulty
- Resource Discovery: Students receive precise pointers to relevant course materials
- Knowledge Transfer Assessment: System identifies opportunities for near-transfer evaluation
- Concept Navigation: Graph structure enables exploration of related concepts and dependencies
- Scaffolded Learning: Explanations follow pedagogically sound progression from fundamentals
Technical Stack
The demonstrator showcases modern AI infrastructure for education:- Knowledge Graph: NetworkX (local) or Neo4j (production scale)
- Vector Store: Embedding-based retrieval for concept mapping
- LLM: Qwen2.5 for reasoning and generation
- Ingestion: Multi-format processing (web, video, PDF, slides)
- Storage: MongoDB for raw content and metadata
- Interface: Chat-based interaction layer