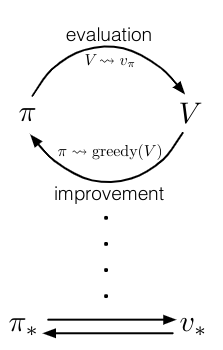
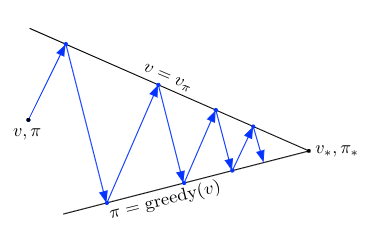
GPI Algorithms
The following tables summarize the algorithms between sample backup and full backup and are provided in this GPI section for reference.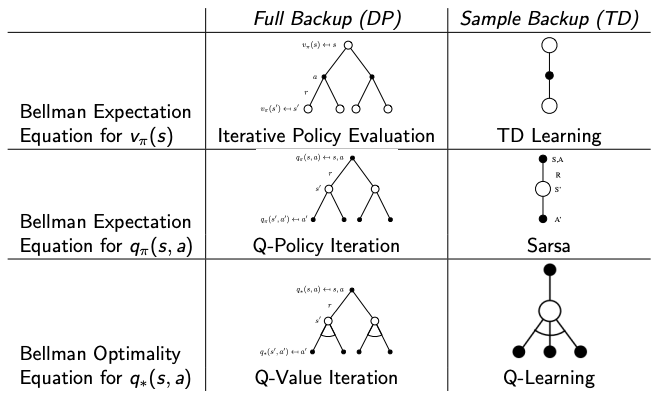

References
- Ma, S., Yu, J. (2016). Transition-based versus State-based Reward Functions for MDPs with Value-at-Risk.
- Mansour, Y., Singh, S. (2013). On the Complexity of Policy Iteration.
- Schulman, J., Levine, S., Moritz, P., Jordan, M., Abbeel, P. (2015). Trust Region Policy Optimization.
- Tamar, A., Wu, Y., Thomas, G., Levine, S., Abbeel, P. (2016). Value Iteration Networks.
- Tamar, A., Wu, Y., Thomas, G., Levine, S., Abbeel, P. (2016). Value Iteration Networks.