The gradient of a neuron is proportional to its input
Start with a single neuron. It forms a weighted sum of its inputs and passes it through a sigmoid: The partial derivative of the output with respect to a weight is For any scalar loss on top, the chain rule gives Two things to read off. The gradient of weight is the input scaled by a single number shared across all weights, so the gradient vector points along the input. And carries , which collapses toward zero when is large: a saturated neuron has a small gradient no matter how large the input is.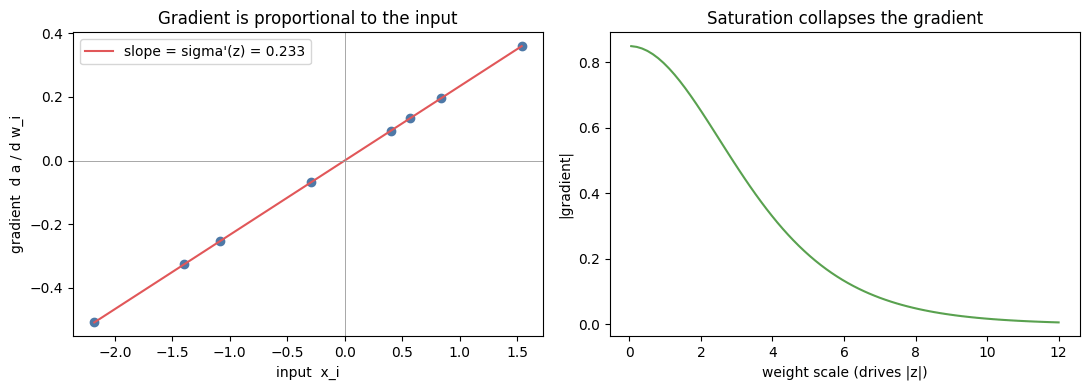
Extending to a fully connected ReLU layer
A fully connected layer applies and then a ReLU, . ReLU has derivative , so With an upstream gradient and the gate , write . Then Every row of is the input vector scaled by one entry of , so again the weight gradient points along the input. Keep an eye on the bias gradient, : there is no factor of in it. That asymmetry returns later.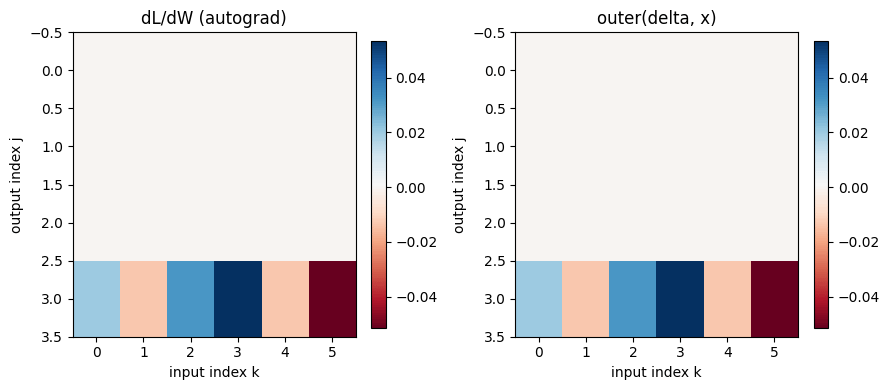
Controlling the input distribution with batch normalization
Because each layer’s weight gradient is the input scaled by , the scale of the inputs feeding a layer sets the scale of its gradients. Batch normalization standardizes those values per feature across a mini-batch, with learnable scale and shift . This is the cheap, per-feature, differentiable relative of whitening: whitening removes all correlations by working with the full covariance matrix, while batch normalization only fixes the per-feature mean and variance (the diagonal). Place batch normalization before the ReLU. If the pre-activation is approximately Gaussian, then and is a rectified Gaussian: a spike of zeros plus the positive tail. The fraction of dead units is so sets how much of the distribution the ReLU clips to zero.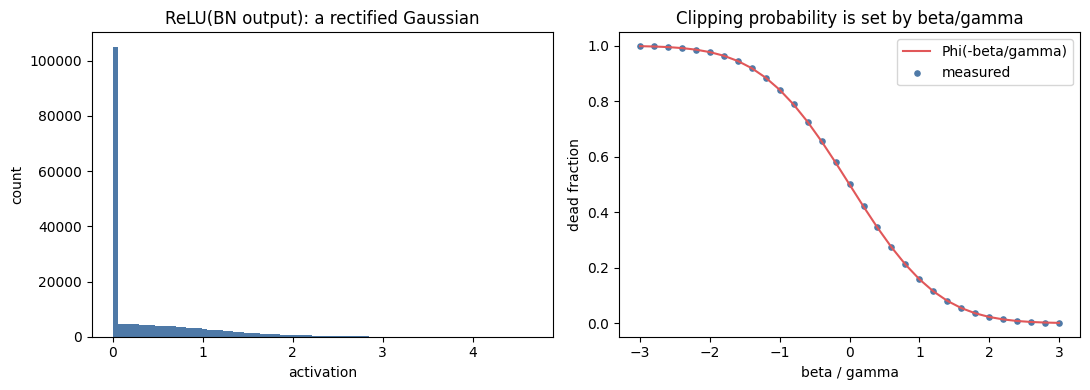
Training and inference
Batch normalization behaves differently in the two phases. During training, each mini-batch is normalized with its own mean and variance, so the statistics a sample sees depend on the other samples in the batch. During inference you want the output for a given input to be fixed, so the layer instead uses running estimates of the mean and variance, accumulated as moving averages over the training batches. The learnable scale and shift are applied in both phases.Where this intuition breaks down
The build above is the story usually told for batch normalization. Most of it is a useful heuristic rather than a theorem. This section keeps the parts that survive scrutiny and shows, with one short experiment each, where the rest fails.The bias gradient does not scale with the input
The weight gradient carries a factor of ; the bias gradient, , does not. Hold the ReLU gate fixed (set so scaling by a positive constant cannot flip any sign) and scale the input. The weight gradient scales with it; the bias gradient does not.Standardizing is not Gaussianizing
Batch normalization fixes only the first two moments. A bimodal pre-activation, standardized, has mean and variance but is still bimodal: the “clipped Gaussian” picture is a central-limit approximation that becomes accurate only as the layer fan-in grows.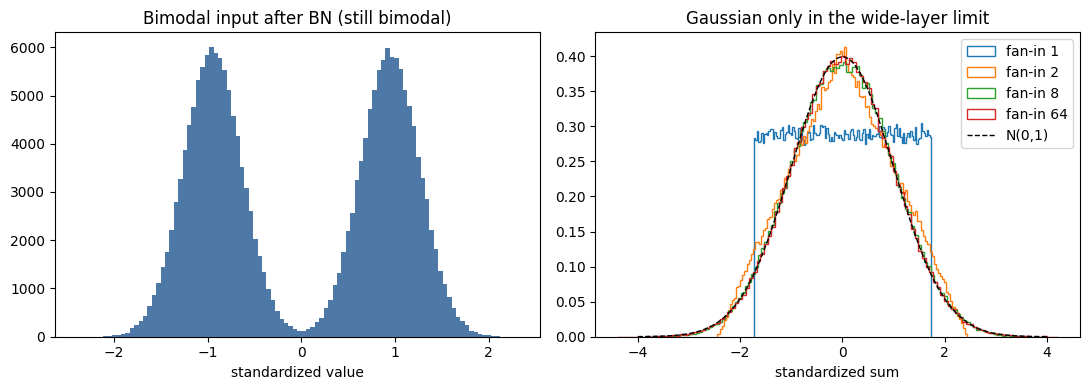
Batch normalization is not whitening
Per-feature standardization leaves the off-diagonal covariance untouched. Two strongly correlated pre-activations stay correlated after batch normalization, so the per-unit clipping picture ignores how units co-activate. Removing that correlation is exactly what whitening does, at a cost batch normalization avoids.The clipping probability is learned, not enforced
Because and are trainable, batch normalization does not pin the distribution to . The affine step can reproduce any mean and variance, which means the dead fraction is something the network learns, not something the layer imposes.What actually controls the gradient magnitude: scale invariance
The defensible version of “batch normalization controls the gradient” needs no Gaussian assumption. Batch normalization is invariant to the scale of the weights feeding it, , so the forward pass ignores the weight scale and the gradient absorbs it inversely: Large weights therefore produce proportionally smaller gradients, which decouples the effective step size from the parameter scale.Why batch normalization actually helps
The motivation in this build, “the gradient depends on the input, so we must control the input distribution”, is the internal covariate shift argument from the original paper. Later work (Santurkar et al., 2018) showed batch normalization does not actually reduce covariate shift: injecting noise after batch normalization, which increases the shift, still trains well. The measured effect is a smoother loss landscape, with more predictive (Lipschitz) gradients, which is what lets you raise the learning rate. The figure below shows the gradient distribution at initialization is far better behaved with batch normalization than without.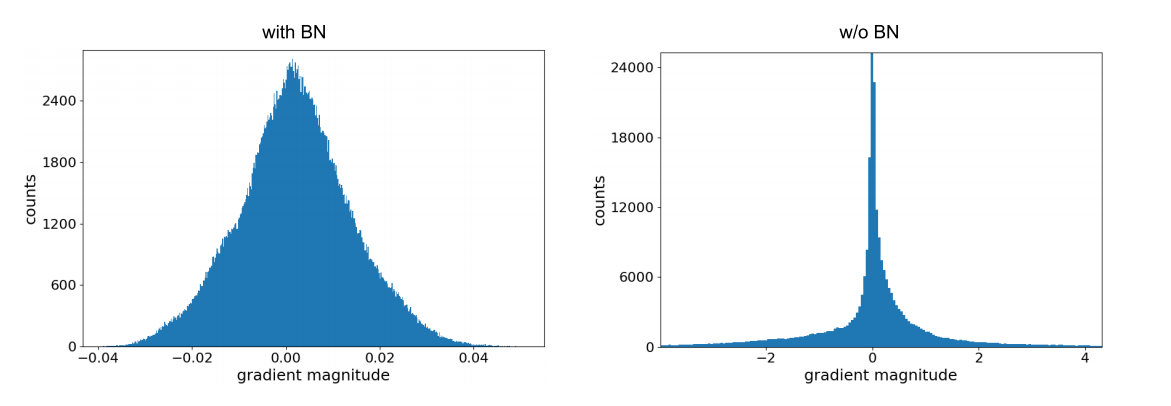
What survives
- The weight gradient really is proportional to the input, for a single neuron and for a fully connected ReLU layer.
- The bias gradient is not: it depends on the input only through the ReLU gate.
- “Batch normalization before ReLU controls a clipped Gaussian” is an approximation. It fixes two moments, assumes the rest is Gaussian (true only for wide layers), and leaves correlations in place, so it is not whitening.
- The clipping probability is learned through the affine parameters, not imposed by the layer.
- The claim that holds without a Gaussian assumption is scale invariance, with gradients scaling as . The optimization benefit is landscape smoothing, not the removal of internal covariate shift.
- Whether batch normalization sits before or after the ReLU is an empirical choice, not a theoretical requirement.
References
- Ioffe & Szegedy, 2015. Batch Normalization.
- Santurkar et al., 2018. How Does Batch Normalization Help Optimization?
- Bjorck et al., 2018. Understanding Batch Normalization.
- LeCun et al., Efficient BackProp.
- Internal: Data preprocessing and whitening.