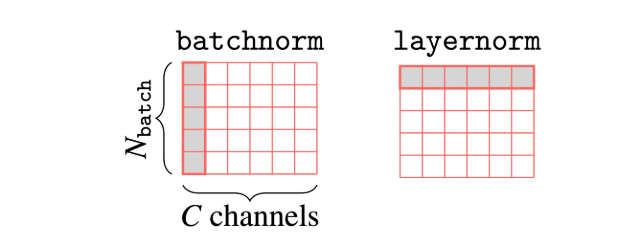
Difference between Batch Normalization and Layer Normalization. LN operates across feature dimensions for each sample independently.
Limitations of Batch Normalization
Batch Normalization (BN) helps training efficiency by positioning activations in a trainable way. However, it has limitations with small batch sizes since it operates across the batch dimension and normalizes activations for each feature/channel across the batch. Smaller batch sizes result in inaccurate statistics. This is particularly problematic in LLMs that require small mini-batches due to memory constraints.Layer Normalization
For architectures such as recurrent networks and transformers, we apply Layer Normalization. The layer normalization of an input vector is computed as: where the mean and variance are: Here:- and are learnable parameters (of shape )
- is a small constant for numerical stability
- denotes element-wise multiplication
Key Difference from Batch Normalization
Layer Normalization operates across the feature dimensions for each sample independently, normalizing the activations in a trainable way. This is effectively the transpose of Batch Normalization:When to Use Layer Normalization
- Recurrent Neural Networks (RNNs): Variable sequence lengths make BN difficult
- Transformers: Self-attention mechanisms benefit from LN
- Small batch training: When memory constraints limit batch size
- Online learning: Single-sample updates