Derivation of the bias-variance decomposition
Throughout the derivation, treat as fixed and let all randomness sit in (equivalently, in ). Define Add and subtract inside the squared error: Expand the square: By linearity of expectation, and pulling the constant factor out of the cross term: The cross term vanishes because the inner deviation has zero mean: leaving the bias-variance decomposition stated above: The derivation follows the standard estimator-MSE argument from Wikipedia, specialized to the prediction setting where the estimator is the model’s output . Note that this form assumes the target is deterministic; if itself carries irreducible noise with variance , the decomposition gains an additive term and becomes .Interpretation
The decomposition splits the prediction error into two competing sources and as shown in the plots above, increasing model capacity can really increase the variance of . We have seen that as is fit to exactly match, or memorize, the data, it minimizes the bias (in fact for model complexity the bias is 0) but it also exhibits significant variability that is itself translated to . Although the definition of model capacity is far more rigorous, we will broadly associate complexity with capacity and borrow the figure below from Ian Goodfellow’s book to demonstrate the tradeoff between bias and variance. What we have done with regularization is to find the that minimizes generalization error, i.e., find the optimal model capacity.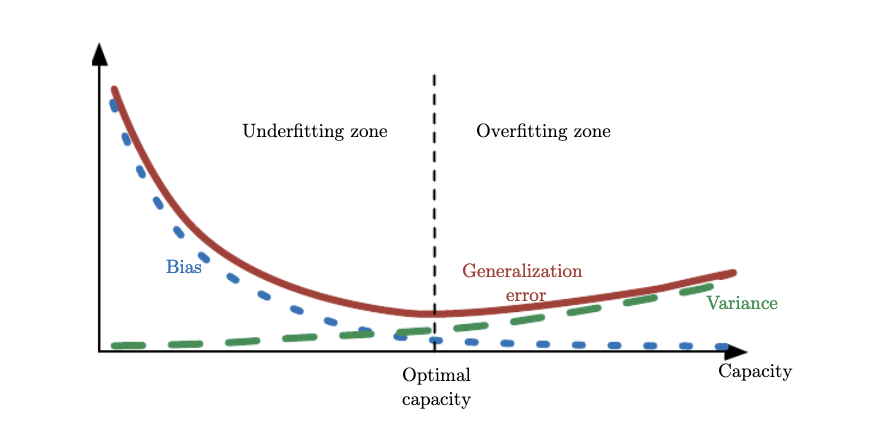
Bias and Variance Decomposition during the training process
Apart from the composition of the generalization error for various model capacities, it is interesting to make some general comments regarding the decomposition of the generalization error (also known as empirical risk) during training. Early in training the bias is large because the predictor output is far from the target function. The variance is very small because the data has had little influence yet. Late in training the bias is small because the predictor has learned the underlying function. However if train for too long then the predictor will also have learned the noise specific to the dataset (overfitting). In such case the variance will be large because the noise varies between training and test datasets.Do not extrapolate the U-shaped curve above to highly over-parameterized models. Modern over-parameterized neural networks empirically exhibit a double descent risk curve (Belkin et al., 2018; Nakkiran et al., 2019): as capacity grows past the interpolation threshold, the test error first rises (classical regime) and then falls again in the over-parameterized regime, sometimes below the optimum of the classical U-curve. The bias-variance picture above remains a good guide in the under-parameterized regime that this page focuses on, but cannot predict generalization behavior of contemporary deep models.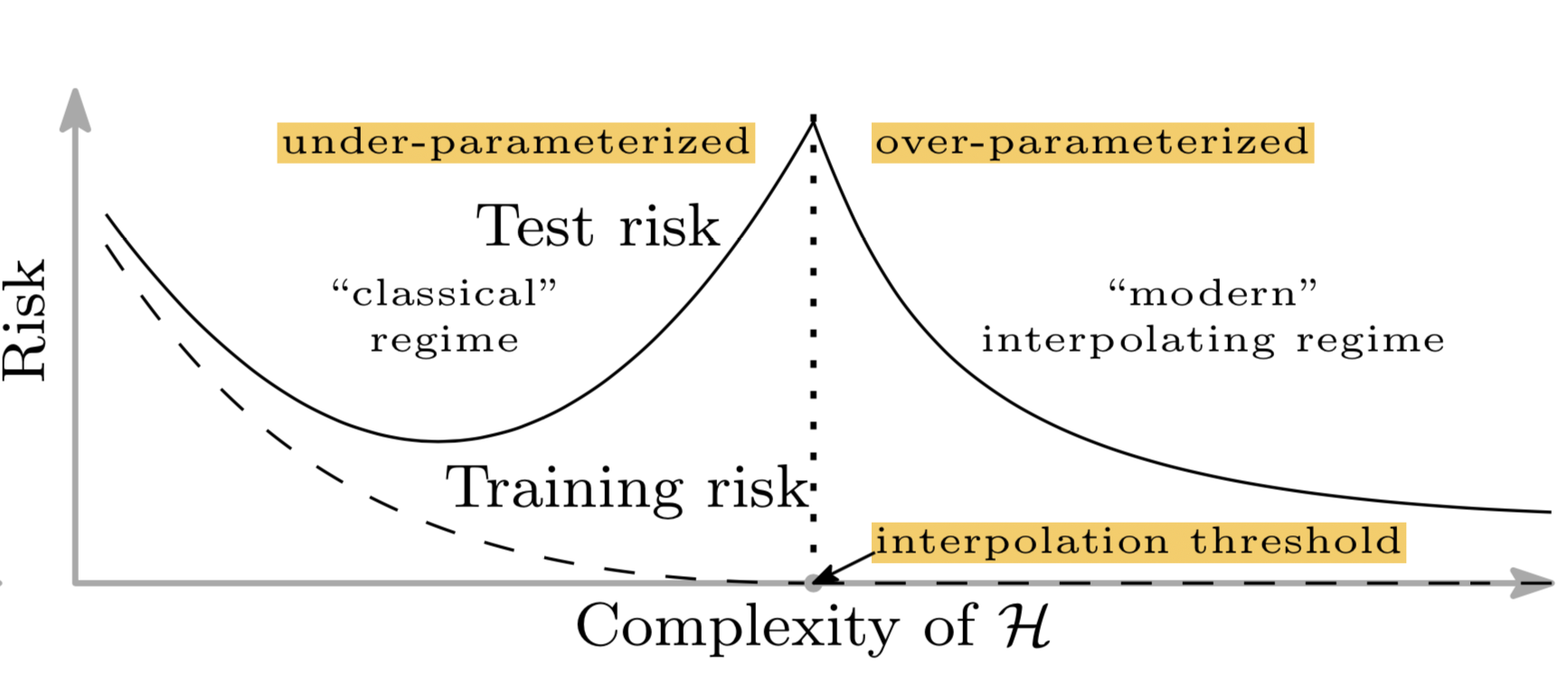
References
- Belkin, M., Hsu, D., Ma, S., Mandal, S. (2018). Reconciling modern machine learning practice and the bias-variance trade-off.
- Nakkiran, P., Kaplun, G., Kalimeris, D., Yang, T., Edelman, B., et al. (2019). SGD on neural networks learns functions of increasing complexity.