These notes heavily borrow from the CS229N 2019 set of notes on NMT.

- Translation: taking a sentence in one language as input and outputting the same sentence in another language.
- Conversation: taking a statement or question as input and responding to it.
- Summarization: taking a large body of text as input and outputting a summary of it.
- Code Generation: Natural Language to formal language code (e.g. python)
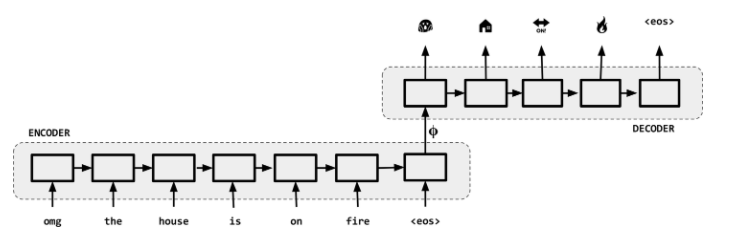
Sequence-to-Sequence (Seq2Seq)
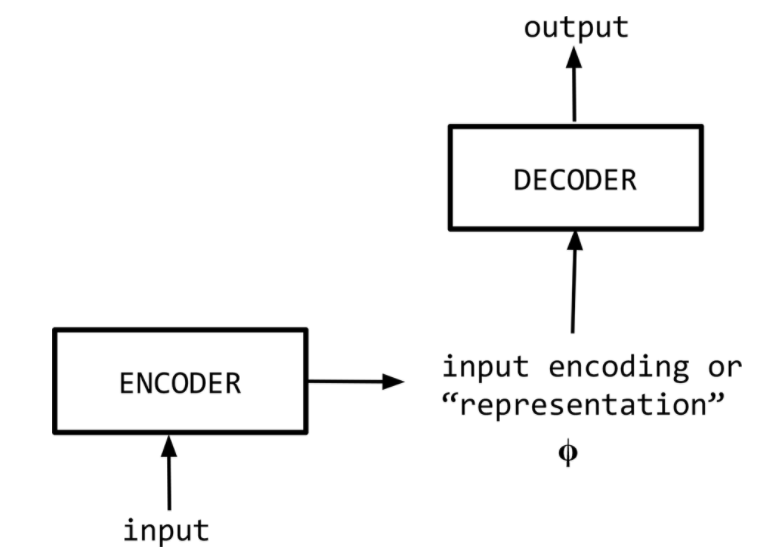
Sequence-to-sequence, or “Seq2Seq”, was first published in 2014. At a high level, a sequence-to-sequence model is an end-to-end model made up of two recurrent neural networks (LSTMs):- an encoder, which takes the a source sequence as input and encodes it into a fixed-size “context vector” , and
- a decoder, which uses the context vector from above as a “seed” from which to generate an output sequence.
Encoder
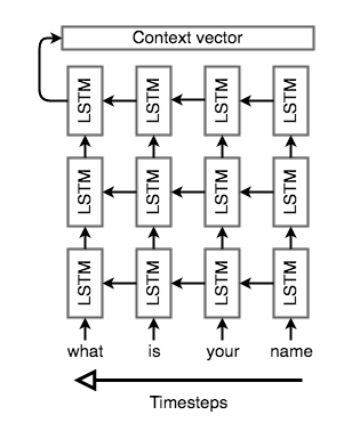
The encoder network reads the input sequence and generates a fixed-dimensional context vector for the sequence. To do that we use an RNN that mathematically, it evolves its hidden state as follows: and can be in e.g. any non-linear function such as an bidirectional RNN with a given depth. In the following we use the term RNN to refer to a gated RNN such as an LSTM. The context vector is generated from the sequence of hidden states, The bidirectional RNN is shown schematically below.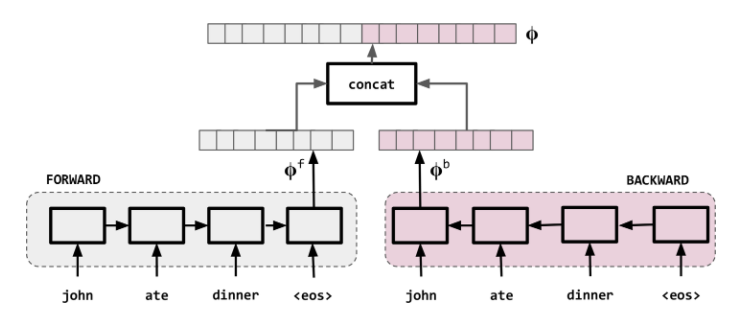
Decoder
The decoder is “aware” of the target words that it’s generated so far and of the input. In fact it is an example of conditional language model because it conditions on the source sentence or its representation - the context . The decoder directly calculates, We can write this as: and then use the product rule of probability to decompose this to: We can now write, In this equation is a probability distribution represented by a softmax across all all the words of the vocabulary. We can use an RNN to model the conditional probabilities To that end, we’ll keep the “stacked” LSTM architecture from the encoder, but we’ll initialize the hidden state of our first layer with the context vector. Once the decoder is set up with its context, we’ll pass in a special token to signify the start of output generation; in literature, this is usually an<SOS> token appended to the end of the input (there’s also one at the end of the output). Then, we’ll run all stacked layers of LSTM, one after the other, following at the end with a softmax on the final layer’s output that can tell us the most probable output word.
Both the encoder and decoder are trained at the same time, so that they both learn the same context vector representation as shown next.
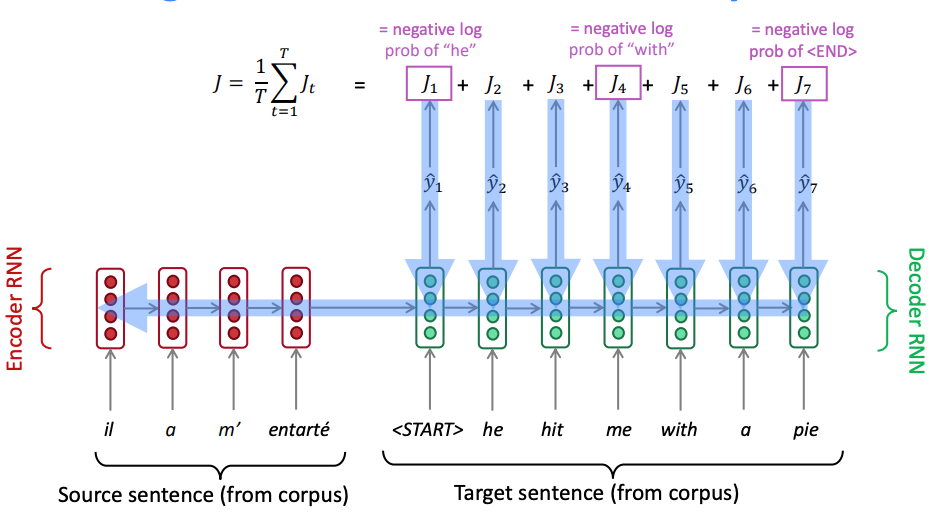
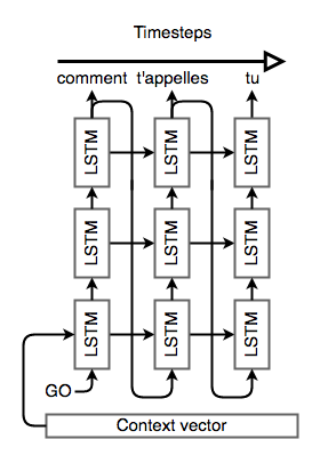
PyTorch reference
Key references: (Cho et al., 2014; Wiseman & Rush, 2016; Bahdanau et al., 2014; Sutskever et al., 2014; Lipton et al., 2015)
References
- Bahdanau, D., Cho, K., Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate.
- Cho, K., Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., et al. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.
- Lipton, Z., Berkowitz, J., Elkan, C. (2015). A Critical Review of Recurrent Neural Networks for Sequence Learning.
- Sutskever, I., Vinyals, O., Le, Q. (2014). Sequence to Sequence Learning with Neural Networks.
- Wiseman, S., Rush, A. (2016). Sequence-to-Sequence Learning as Beam-Search Optimization.