The simple RNN architecture with just a single layer of neurons that receive the input x is shown below.
 Simple RNN layer with nneurons RNN neurones mapping the input to the hidden-state at each time step.
A more practical simple RNN architecture is shown below.
Simple RNN layer with nneurons RNN neurones mapping the input to the hidden-state at each time step.
A more practical simple RNN architecture is shown below.
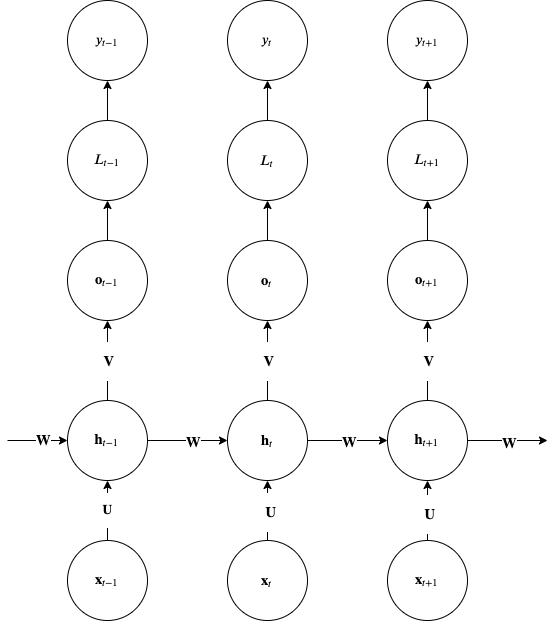 Simple RNN with recurrences between hidden units. This architecture can compute any computable function and therefore is a Universal Turing Machine.
Notice how the path from input xt−1 affects the label yt and also the conditional independence between y given x.
Simple RNN with recurrences between hidden units. This architecture can compute any computable function and therefore is a Universal Turing Machine.
Notice how the path from input xt−1 affects the label yt and also the conditional independence between y given x.
Please note that to use this diagram for backpropagation, you must flip the roles of nodes and edges shown. Tensors must be on edges and RNN functions (gates) must be in the nodes of the graph.
Dimensioning Simple RNNs
In the table below m is the number of examples in the mini-batch.
Please note that there may be multiple layers that can be stacked on top of each other and they can individually keep a hidden state.
Forward Propagation
This network maps the input sequence to a sequence of the same length and implements the following forward pass:
at=Wht−1+Uxt+b
ht=tanh(at)
ot=Vht+c
y^t=softmax(ot)
L(y^1,…,y^τ,y1,…,yτ)=DKL[p^data(y∣x)∣∣pmodel(y∣x;θ)]
=−Ey∣x∼p^datalogpmodel(y∣x;θ)=−∑tlogpmodel(yt∣x1,…,xt;θ)
Notice that RNNs can model very generic distributions logpmodel(x,y;θ). The simple RNN architecture above, effectively models the posterior distribution logpmodel(y∣x;θ) and based on a conditional independence assumption it factorizes into ∑tlogpmodel(yt∣x1,…,xt;θ).
Altough we dont expand further here, note that by connecting the yt−1 to ht via a matrix e.g. R we can avoid this simplifying assumption and be able to model an arbitrary distribution logpmodel(y∣x;θ). In other words just like in the other DNN architectures, connectivity directly affects the representational capacity of the hypothesis set.  Example sentence as input to the RNN
In the figure above you have a hypothetical document (a sentence) that is broken into tokens - lets say that a token is a word in this case. In the simpler case where we need a classification of the whole document, given that τ=6, we are going to receive at t=1, the first token x1 and with an input hidden state h0=0 we will calculate the forward equations for h1, ignoring the output o1 and repeat the unrolling when the next input x2 comes in until we reach the end of sentence token x6 which in this case will calculate the output y6 and loss
−logpmodel(y6∣x1,…,x6;w)
where θ=W,U,V,b,c.
Example sentence as input to the RNN
In the figure above you have a hypothetical document (a sentence) that is broken into tokens - lets say that a token is a word in this case. In the simpler case where we need a classification of the whole document, given that τ=6, we are going to receive at t=1, the first token x1 and with an input hidden state h0=0 we will calculate the forward equations for h1, ignoring the output o1 and repeat the unrolling when the next input x2 comes in until we reach the end of sentence token x6 which in this case will calculate the output y6 and loss
−logpmodel(y6∣x1,…,x6;w)
where θ=W,U,V,b,c.
Back-Propagation Through Time (BPTT)
Lets now see how the training through backward propagation would work for RNNs.
 Understanding RNN memory through BPTT procedure
Backpropagation is similar to that of other neural networks simply because the unrolled architecture resembles a feed forward arrangement. But there is an important difference and we can see it using the above computational graph for the unrolled recurrences t and t−1. During computation of the variable ht we use the value of the variable ht−1 calculated in the previous recurrence. So when we apply the chain rule in the backward phase of BP, for all nodes that involve such variables with recurrent dependencies, the end result is that non local gradients appear from previous backpropagation steps (t in the figure). This is in contrast to other networks where during BP only local to each gate gradients where involved as we have seen earlier.
This is effectively why we say that simple RNNs feature memory. The key point to notice in the backpropagation in recurrence t−1 is the junction between tanh and Vht−1. This junction brings in the gradient ∇ht−1Lt from the backpropagation of the Wht−1 node in recurrence t and just because its a junction, it is added to the backpropagated gradient from above in the current recurrence t−1 i.e.
∇ht−1Lt−1←∇ht−1Lt−1+∇ht−1Lt
Ian Goodfellow’s section 10.2.2 provides the exact equations - please note that you need to know only the intuition behind computational graphs for RNNs. In practice, BPTT is [truncated](https://proceedings.mlr.press/v115/aicher20a.html#:~:text=Truncated%20backpropagation%20through%20time%20(TBPTT,a%20fixed%20number%20of%20lags.) to avoid having to do one full forward pass and one full reverse pass through the training dataset of a e.g. language model that is usually very large, to do a single gradient update. When the truncation level is not sufficiently large, the bias introduced can cause SGD to not converge. In practice, a large truncation size is chosen heuristically (e.g. larger than the expected ‘memory’ of the system) or via cross-validation.
Understanding RNN memory through BPTT procedure
Backpropagation is similar to that of other neural networks simply because the unrolled architecture resembles a feed forward arrangement. But there is an important difference and we can see it using the above computational graph for the unrolled recurrences t and t−1. During computation of the variable ht we use the value of the variable ht−1 calculated in the previous recurrence. So when we apply the chain rule in the backward phase of BP, for all nodes that involve such variables with recurrent dependencies, the end result is that non local gradients appear from previous backpropagation steps (t in the figure). This is in contrast to other networks where during BP only local to each gate gradients where involved as we have seen earlier.
This is effectively why we say that simple RNNs feature memory. The key point to notice in the backpropagation in recurrence t−1 is the junction between tanh and Vht−1. This junction brings in the gradient ∇ht−1Lt from the backpropagation of the Wht−1 node in recurrence t and just because its a junction, it is added to the backpropagated gradient from above in the current recurrence t−1 i.e.
∇ht−1Lt−1←∇ht−1Lt−1+∇ht−1Lt
Ian Goodfellow’s section 10.2.2 provides the exact equations - please note that you need to know only the intuition behind computational graphs for RNNs. In practice, BPTT is [truncated](https://proceedings.mlr.press/v115/aicher20a.html#:~:text=Truncated%20backpropagation%20through%20time%20(TBPTT,a%20fixed%20number%20of%20lags.) to avoid having to do one full forward pass and one full reverse pass through the training dataset of a e.g. language model that is usually very large, to do a single gradient update. When the truncation level is not sufficiently large, the bias introduced can cause SGD to not converge. In practice, a large truncation size is chosen heuristically (e.g. larger than the expected ‘memory’ of the system) or via cross-validation.
Vanishing or exploding gradients
In the figure below we have drafted a conceptual version of what is happening with recurrences over time. Its called an Infinite Impulse Response (IIR) filter for reasons that will be apparent shortly. Infinite Impulse Response (IIR) filter with weight wWith D denoting a unit delay (a memory location that we can store and retrieve a value), the recurrence formula for this system is:ht=wht−1+xtwhere w is a weight (a scalar). Lets consider what happens when an impulse, xt=δt is fed at the input of this system with w=−0.9.h0=−0.9h−1+δ0=1
h1=−0.9h0+δ1=−0.9
h2=−0.9h1+δ2=0.81
h3=−0.9h2+δ3=−0.729With w=−0.9, the h_t (called impulse response) follows a decaying exponential envelope while obviously with w>1.0 it would follow an exponentially increasing envelope. Such recurrences if continue will result in vanishing or exploding responses long after the impulse showed up in the input t=0.Using this primitive IIR filter as an analogy, we can see that the weight plays a crucial role in the impulse response.
Infinite Impulse Response (IIR) filter with weight wWith D denoting a unit delay (a memory location that we can store and retrieve a value), the recurrence formula for this system is:ht=wht−1+xtwhere w is a weight (a scalar). Lets consider what happens when an impulse, xt=δt is fed at the input of this system with w=−0.9.h0=−0.9h−1+δ0=1
h1=−0.9h0+δ1=−0.9
h2=−0.9h1+δ2=0.81
h3=−0.9h2+δ3=−0.729With w=−0.9, the h_t (called impulse response) follows a decaying exponential envelope while obviously with w>1.0 it would follow an exponentially increasing envelope. Such recurrences if continue will result in vanishing or exploding responses long after the impulse showed up in the input t=0.Using this primitive IIR filter as an analogy, we can see that the weight plays a crucial role in the impulse response.  Derivative of tanh non-linearity
Similar the successive application of the W matrix is causing explosive gradients as simplistically (ignoring the non-linearity) the hidden state can be written as:
ht=Wht−1
making after τ steps
ht=Wτh0
If the magnitude of the eigenvalues are less than 1.0 the matrix will create vanishing gradients as it is involved in the ∇htLt expression (see equations in section 10.2.2). This issue is addressed using an evolved RNN architecture called Long Short Term Memory (LSTM).
Derivative of tanh non-linearity
Similar the successive application of the W matrix is causing explosive gradients as simplistically (ignoring the non-linearity) the hidden state can be written as:
ht=Wht−1
making after τ steps
ht=Wτh0
If the magnitude of the eigenvalues are less than 1.0 the matrix will create vanishing gradients as it is involved in the ∇htLt expression (see equations in section 10.2.2). This issue is addressed using an evolved RNN architecture called Long Short Term Memory (LSTM).
PyTorch reference
Key references: (Graves et al., n.d.; Jaderberg et al., 2016; Parisotto et al., 2016)
References
- Graves, A., Wayne, G., Danihelka, I. (n.d.). Neural Turing Machines.
- Jaderberg, M., Czarnecki, W., Osindero, S., Vinyals, O., Graves, A., et al. (2016). Decoupled Neural Interfaces using Synthetic Gradients.
- Parisotto, E., Mohamed, A., Singh, R., Li, L., Zhou, D., et al. (2016). Neuro-Symbolic Program Synthesis.