- Eliminate all recurrent connections present in earlier RNN architectures, therefore allowing the model to be trained as well as produce inference results much faster since we dont need to wait for the previous token to be processed. Because we broke the sequential nature of processing the input we need to encode explicitly the order that the token show up in the input context. This is done by adding positional encodings to the input embeddings.
- Use attention mechanisms to allow the context-free embeddings, such as the word2vec embeddings, to be adjusted based on the context of the input sequence. These attention mechanisms will be present in the encoder or the decoder or in both encoder & decoder. We call this mechanism attention, since effectively each token attends to the other tokens of the input sequence that adjust mostly its embedding.
- I love bears
- She bears the pain
- Bears won the game
Simple self-attention mechanism
To achieve such mapping, we are enabling the other tokens to affect the initial coxtext-free representation via a simple dot-product mechanism that involves the input token and all other tokens in the context. Such attention mechanism is called simple self-attention and the ‘self’ refers to the token’s dot product with itself and each and every other token of the input context. This is shown in the next figure where we have formed the input context matrix with dimensions [T, d] where is the length of the input context and is the embedding dimension. In this example a token is [dx1] vector with and we have tokens. Minimal realistic values for the size of such matrices are and (Llama-2), although higher values are typically used.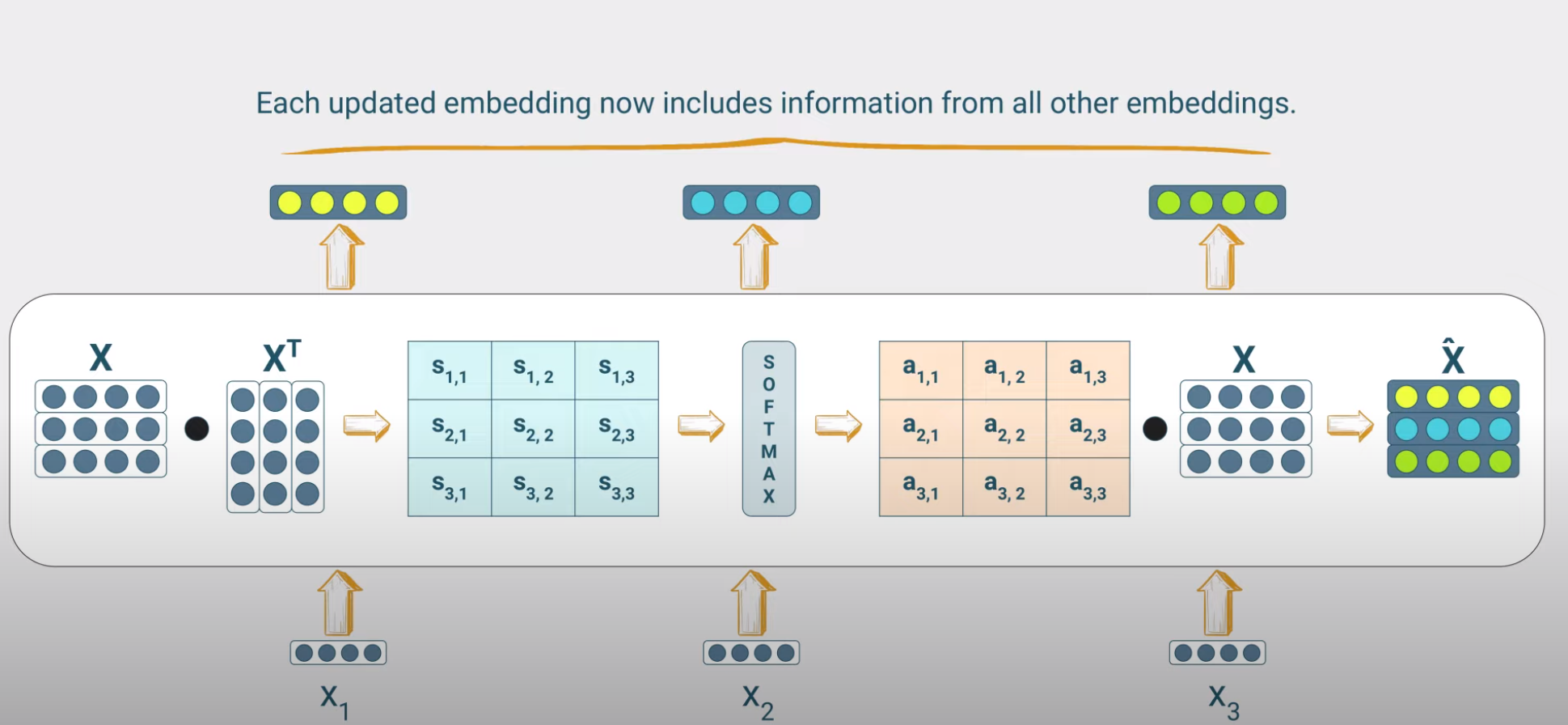
Resources
- An interesting video for the many attention mechanisms that are the roots of self-attention found in transformers.
- Perhaps one of the best from scratch implementation of Transformers in Tensorflow.
PyTorch reference
Key references: (Vaswani et al., 2017; Jaderberg et al., 2015; Luong et al., 2015; Dauphin et al., 2016; Chan et al., 2015)
References
- Chan, W., Jaitly, N., Le, Q., Vinyals, O. (2015). Listen, Attend and Spell.
- Dauphin, Y., Fan, A., Auli, M., Grangier, D. (2016). Language Modeling with Gated Convolutional Networks.
- Jaderberg, M., Simonyan, K., Zisserman, A., Kavukcuoglu, K. (2015). Spatial Transformer Networks.
- Luong, M., Pham, H., Manning, C. (2015). Effective Approaches to Attention-based Neural Machine Translation.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., et al. (2017). Attention Is All You Need.