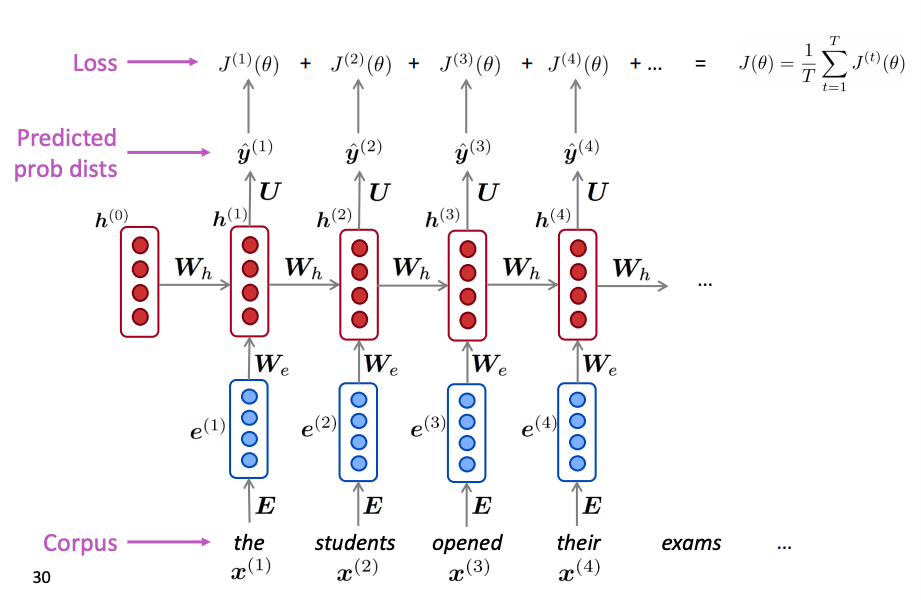
- We start with big corpus of text which is a sequence of tokens where T is the number of words / tokens in the corpus.
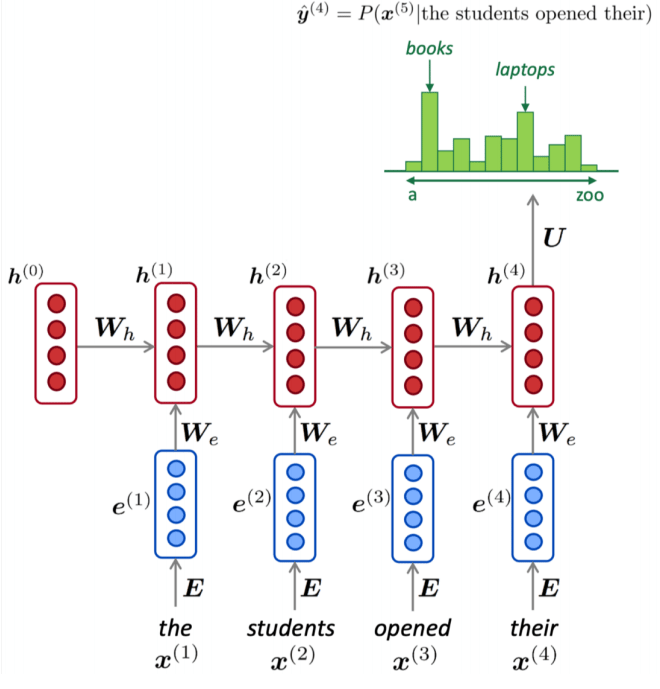
- Every time step we feed one word at a time to the LSTM and compute the output probability distribution , which is, by construction, a conditional probability distribution of every word in the vocabulary given the words we have seen so far.
- The loss function at time step is the CE between the predicted probability distribution and the distribution that corresponds to the one-hot encoded next token.
- Average all the t-step losses
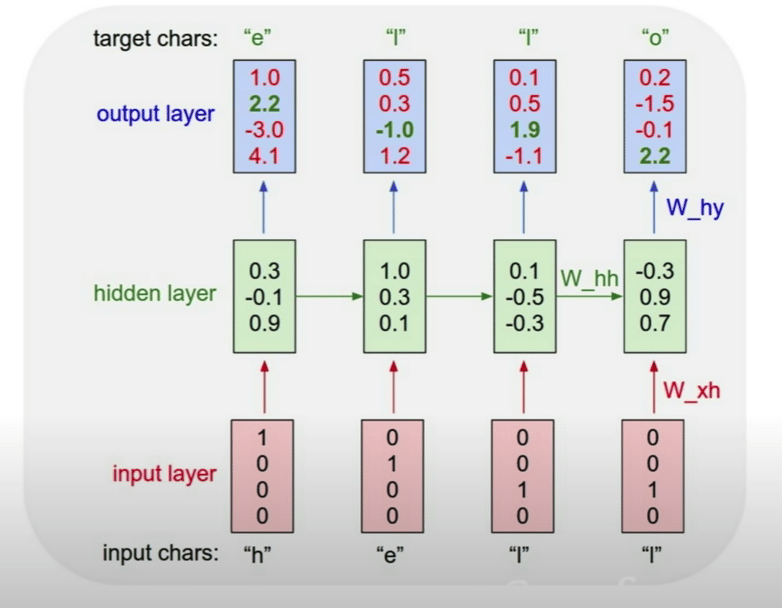
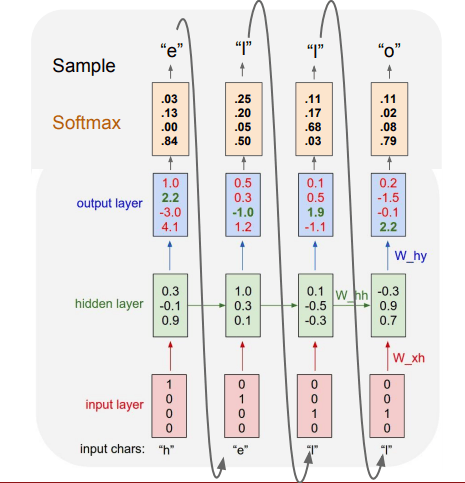
PyTorch reference
Key references: (Sak et al., 2014; Dauphin et al., 2016; Collins et al., 2016; Kim et al., 2015; Cho et al., 2014)
References
- Cho, K., Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., et al. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.
- Collins, J., Sohl-Dickstein, J., Sussillo, D. (2016). Capacity and Trainability in Recurrent Neural Networks.
- Dauphin, Y., Fan, A., Auli, M., Grangier, D. (2016). Language Modeling with Gated Convolutional Networks.
- Kim, Y., Jernite, Y., Sontag, D., Rush, A. (2015). Character-Aware Neural Language Models.
- Sak, H., Senior, A., Beaufays, F. (2014). Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition.