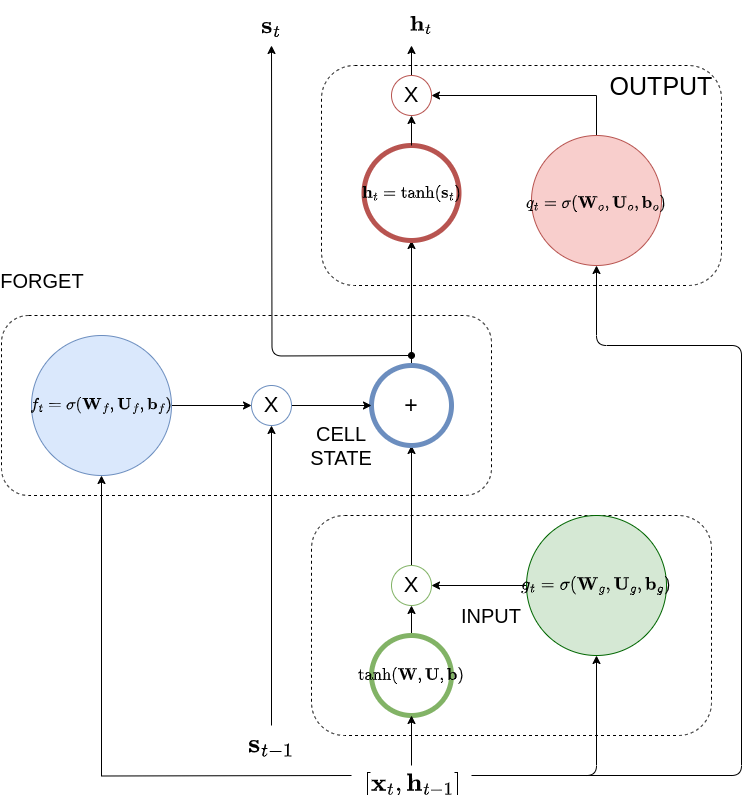
- We use two indices - for the unfolding sequence index and for the cell index of the LSTM hidden layer.
- We also denote by , the i-th row of the matrix .
Forward Pass
The Input Gate
The input gate protects the cell state contents from perturbations by irrelevant inputs to the context. The LSTM in other words learns when to let activations from the input layer into the internal state. As long as the input gate takes value zero, no activation can get in. Quantitatively, input gate calculates the factor, The gate uses the sigmoid function to produce a factor between 0 and 1 for each of the cells of the LSTM hidden layer - each cell is indexed by . This factor is applied to the -th cell’s input that is the combination of a function of the previous hidden state represented by the dot product and a function of the current input, represented by the dot product .The Input Layer
This is formed exactly as the input of the simple RNN layer - see earlier notes.The Forget Gate
The forget gate calculates the forgetting factor, Similar to the input gate, this factor determines the amount of the earlier cell state that is needed to be preserved. Closing, you can expect backpropagation to work similarly to simple RNN case albeit with more complicated expressions. In the LSTM workshop that follows you will have the opportunity to look at an LSTM training from scratch. Hyperparameter optimization for LSTMs is addressed more formally “LSTM: A Search Space Odyssey”Output Gate
The output gate protects the subsequent cells from perturbations by irrelevant to their context hidden state. The output gate learns when to let the hidden state out.The Cell State
This is the heart of the LSTM cell, the cell state is the new memory that is introduced by LSTM - all the earlier factors are used to preserve it as long as it is needed by the use case. The parameters are the recurrent weights, input weights and bias respectively at the input of the i-th LSTM cell.The Hidden State
The hidden state is the output of the LSTM cell. It is a function of the cell state and the output gate. where is the output gate.Output Layer
The output layer is the same as the output layer of the simple RNN. We typically see fully connected layers, softmax and other units depending on the task (classification, regression etc). Note that when both input and output gates are closed (output 0) the input activation is trapped in the memory cell, neither growing nor shrinking, nor affecting the output at intermediate time steps.Backward Pass
In terms of the backwards pass, the constant error carousel enables the gradient to propagate back across many time steps, neither exploding nor vanishing. In this sense, the gates are learning when to let error in, and when to let it out. In practice, the LSTM has shown a superior ability to learn long- range dependencies as compared to simple RNNs.Additional Resources
Additional tutorial resources on LSTMs can be found here:- A Critical Review of Recurrent Neural Networks for Sequence Learning
- Understanding LSTMs
- Illustrated guide to LSTMs
- Simplest possible LSTM explanation video
References
- Collins, J., Sohl-Dickstein, J., Sussillo, D. (2016). Capacity and Trainability in Recurrent Neural Networks.
- Jaderberg, M., Czarnecki, W., Osindero, S., Vinyals, O., Graves, A., et al. (2016). Decoupled Neural Interfaces using Synthetic Gradients.
- Sak, H., Senior, A., Beaufays, F. (2014). Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition.
- Sutskever, I., Vinyals, O., Le, Q. (2014). Sequence to Sequence Learning with Neural Networks.
- Zaremba, W., Sutskever, I., Vinyals, O. (2014). Recurrent Neural Network Regularization.