Data Pipeline (DP)
The data pipeline has two objectives:- To create the datasets needed for model training and validation. In the process of doing so, it applies several transformations of the raw images. Commonly, three datasets are produced for model development: Training, Validation and Test. In our case only train and test datasets are produced and we use as needed a portion of the train dataset for validation.
- To apply several transformations to the raw images needed for model inference (for the needs of the serving pipeline).
Batch Data Pipeline (DP)
This is a separate data pipeline that implements a number of Extract Transform Load (ETL) operations necessary exclusively for model development that typically requires batch rather than stream processing. In the Data Pipeline we typically include transformations that are necessary for the specific model training.Real-Time Data Pipeline for Serving
The strictly real-time pipeline based on GStreamer technology. This is required for inference (serving pipeline) subject to the frames per second (fps) requirements of the application that is currently estimated at10fps. Due to industry-wide acceptance of GStreamer we expect to make usage of existing plugins, some of them developed by NVIDIA, for their Deepstream platform.
Model Training Pipeline (TRAIN)
During model training the pipeline uses the datasets generated by the Data Pipeline to train a model. Multiple models are validated and supported with appropriate performance results - see model performance monitoring. The complexity of the model training pipeline will be determined by the amount of labeled data.Model Evaluation and Verification Pipeline (MEVP)
The model evaluation and verification pipeline is common in mission critical applications such as industrial AI and is typically implemented by Quality Assurance (QA) teams. The QA team is typically independent of the team that developed the model and their job is to stress test the trained model using actual production data. It is important to address the issue of model drift due to the long-term varying statistical distributions that gradually make the model less and less effective unless a closed loop system is implemented that leads to periodic model retraining - one of the solutions to address model drift.Model Serving Pipeline (SP)
The development of the model serving pipeline (when the model runs in the actual production environment generating anomaly detections/inferences) includes the requirement specification of:- The hyper-edge computing environment (e.g., the node that hosts the model) in close proximity to each manufacturing machine and performs real-time inference,
- The edge computing that processes and stores inference results and other data streams at the factory level as well as determines the alarm state based on such processing.
Experiment Management (EM)
All experiments during model development are traceable and model performance in terms of validation dataset is exposed in a web frontend.Monitoring and Control (MCTRL)
The solution must be able to alert the machine operator for the presence of an anomaly and this is expected to be provided using visual and audio signals that will be emitted by the hyper-edge device. Due to the statistical (probabilistic) nature of the anomaly detection model output, safeguarding against a spurious model response is imperative. This is typically implemented in what is known in the field as probabilistic reasoning over time. This is a model that considers the per image inference as spurious and attempts to correct for false positives or false negatives and therefore greatly improves the accuracy of triggering the alarm when multiple anomaly detections are observed.Analytics (DASH)
The solution should include a cloud computing environment (either in an AWS VPC or in an internal cloud infrastructure) that typically spans multiple availability zones and produces analytical results based on the warehoused dataset that materialize the streams emitted by the edge environment. Dashboards are typically provided that show aggregations of edge metrics, such as number of seam quality alarm minutes per day, total daily yield per machine, or other statistical quantities of interest to manufacturing teams.Our IoT Architecture - the Kappa approach
The underlying principle behind IoT architectures is that data is always seen as being in motion also known in the industry as the kappa architecture. This is in contrast to architectures, where some data is stored and others are streamed - the so called Lambda architecture.
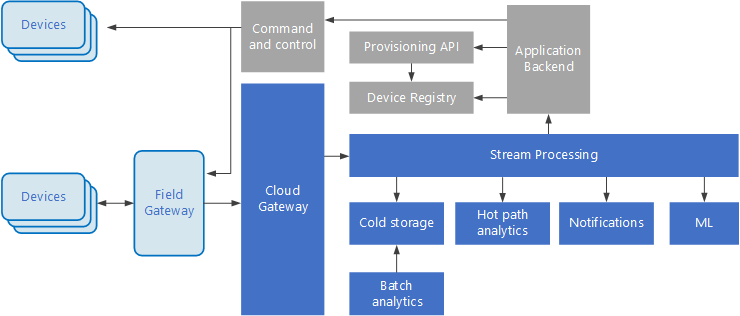
| Block | Component | Description |
|---|---|---|
| Cloud gateway | Gateway & Controller | This implements the Management and Control APIs of the application and is responsible for access and provisioning the compute, storage and network for the various services to function. The gateway may take the form of an appliance that provisions a fixed configuration and as such may not offer an API itself. |
| Streaming Ingestion | GStreamer & Jetstream | The streaming component spans two subdomains of the operational domain - the strict realtime subdomain and almost real-time subdomain where events are produced and distributed to various consumers. For the real-time subdomain where typically the inference pipeline operates under, the Deepstream SDK using GStreamer elements will be used to satisfy a min 10fps sustainable throughput. Some of these elements have been accelerated by NVIDIA for optimal execution on edge GPUs. For the almost real-time subdomain, NATS Jetstream will be used that persists all published events. |
Please note that at the current stage of the project where we focus on model training we will not be implementing the Kappa-architecture. This needs to be done when the model is pushed to production.