Introduction
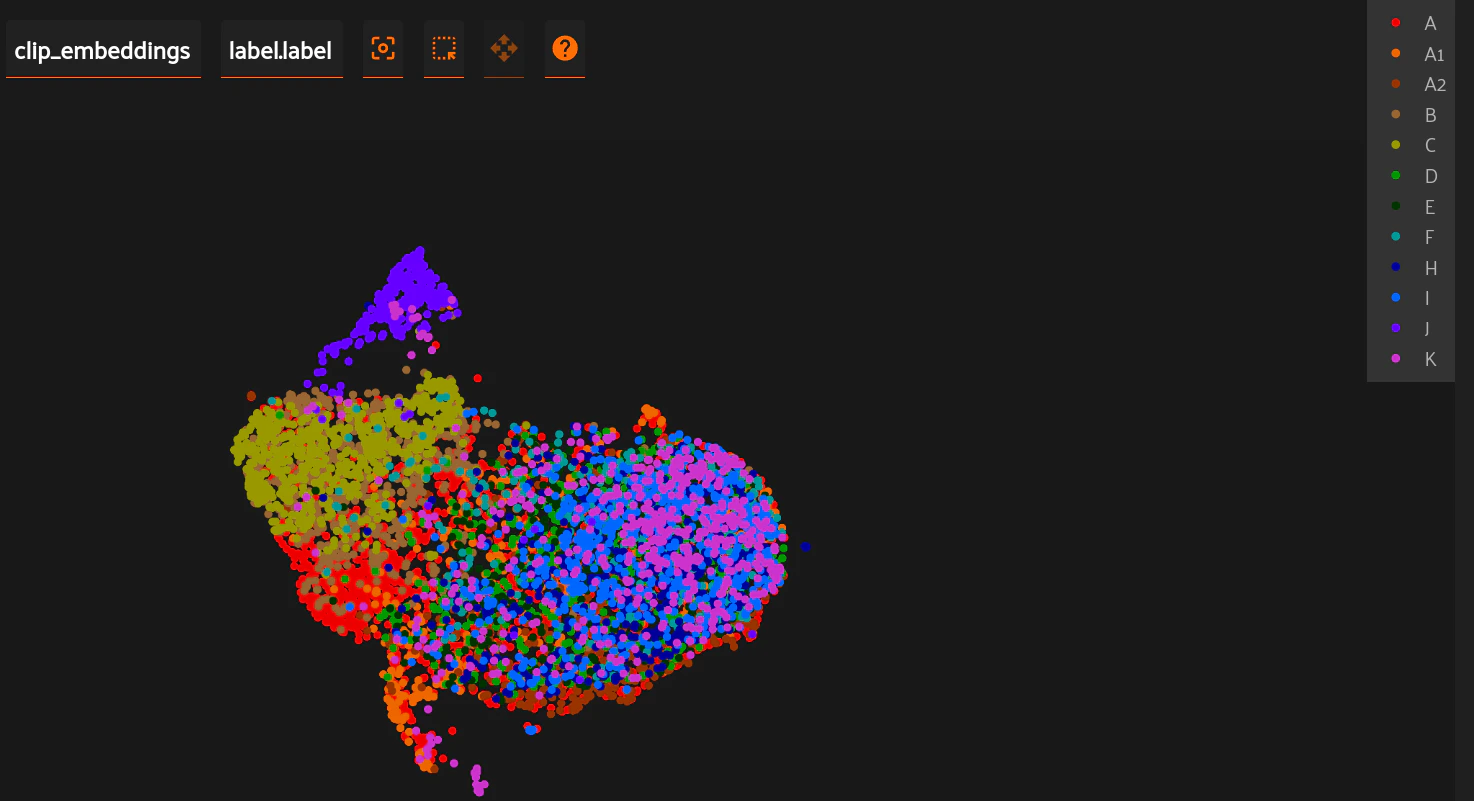
CLIP (Contrastive Language-Image Pre-training) is a model that was pretrained on a large dataset of images and text pairs and is able to perform zero-shot classification. Zero-shot classification is a relatively recent development where the model is able to classify images into a large number of classes without having seen any examples from that class during training. We use the CLIP model to extract features from the Seamagine dataset and subsequently perform anomaly detection using the kNN features of the vector database. The performance of this model is expected to be better than the ResNet-50 model due to its more sophisticated architecture as a backbone.How CLIP Works
CLIP transformers are pretrained on a large dataset of images and text pairs. The model learns to align image and text representations in a shared embedding space, enabling:- Zero-shot classification without task-specific training
- Rich visual representations that capture semantic meaning
- Transfer learning capabilities across diverse visual tasks
Results