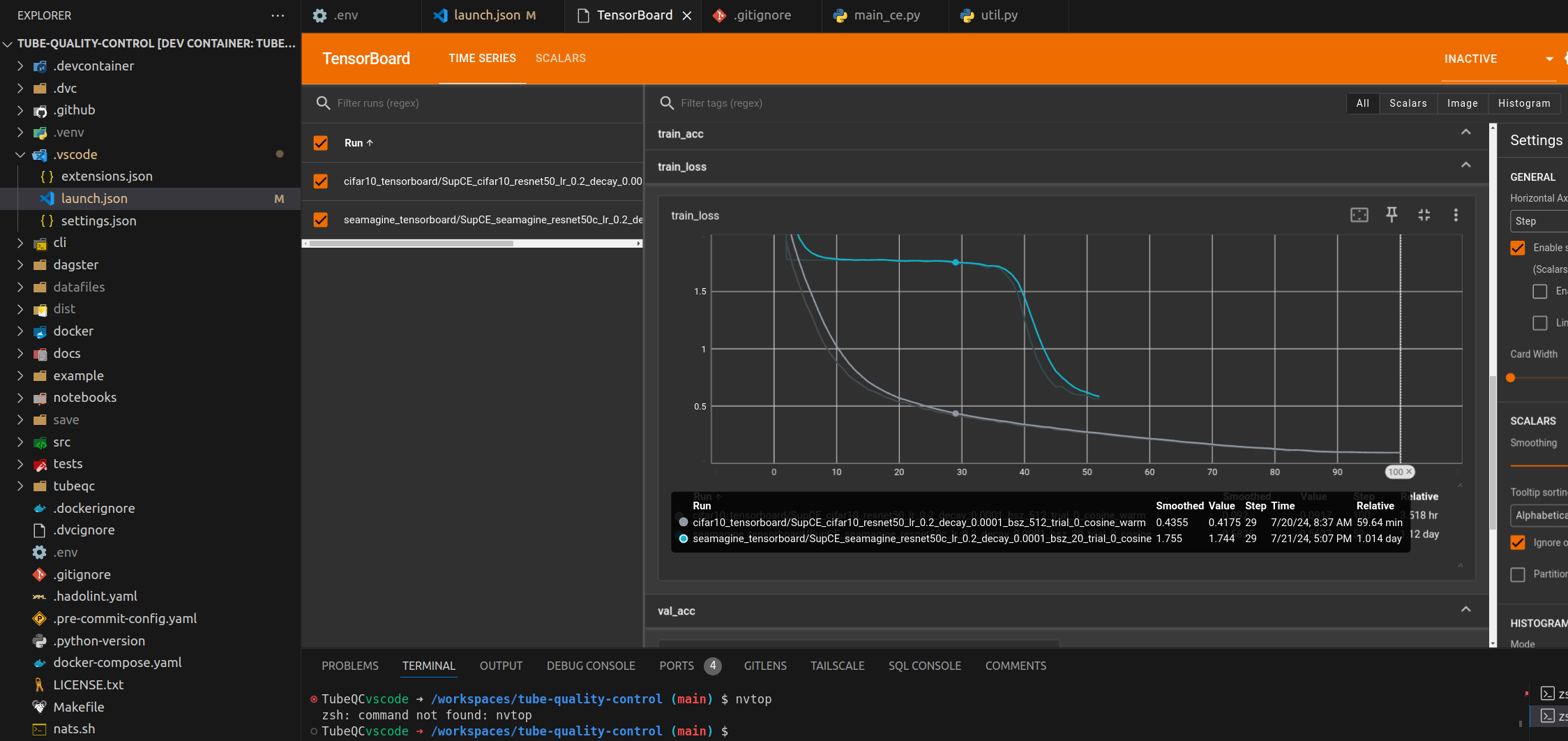
Self-supervised Learned (SSL) Representations
In what we will be calling from now on Self-Supervised Learning (SSL), we implicitly provide a supervisory signal to the representation learning process to improve performance by pulling the similar images closer together and pushing the dissimilar ones further apart. The modeling approach follows this pipeline:Introduction to Contrastive Learning
The idea around contrastive learning is to pull together an anchor and a “positive” sample in embedding space, and push apart the anchor from many “negative” samples. Since no labels are available, a positive pair often consists of data augmentations of the sample, and negative pairs are formed by the anchor and randomly chosen samples from the mini-batch.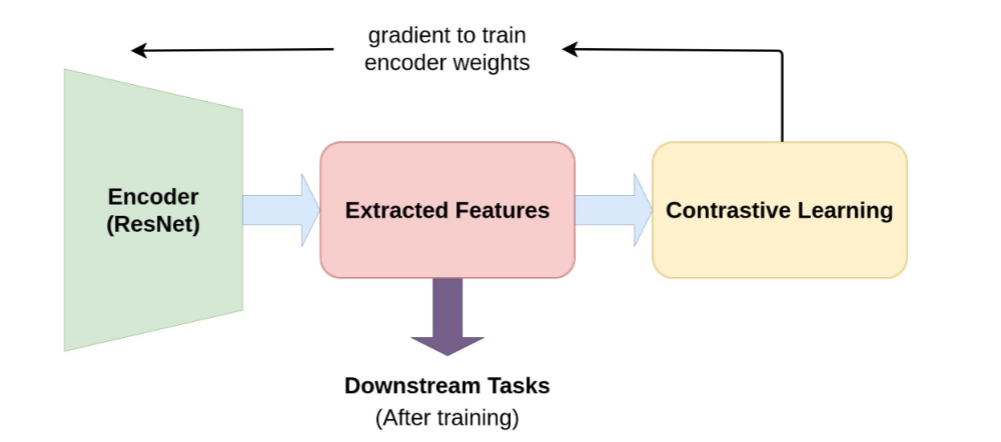
Supervised Contrastive Learning
Supervised contrastive learning extends the contrastive learning paradigm by incorporating label information when available. This allows the model to leverage both the self-supervised contrastive signal and the supervised classification signal.