- Redundancy to ensure that the inference pipeline is always available.
- A vector store that contains the nominal vectors that are representative of the nominal data distribution that is specific to the manufacturing machine.
- A mechanism to address the cold-start problem detailed in the cold start section.
- An acceleration device that is capable of running the inference pipeline at a rate of 10fps.
- A mechanism to interface with the analytics subsystem.
Profiling and Benchmarking
Inference and tagging of a product as anomalous or not must be completed at maximum 100ms ensuring a throughput of 10 products per second. The generation of embeddings for the pretrained CNN unsupervised model is for a 224x224 image on the order of 10ms without any optimization (fp32) or batching. The vector store is able to perform nearest neighbors search in approx 10ms-15ms (P99) latency for a 2048-dim vector.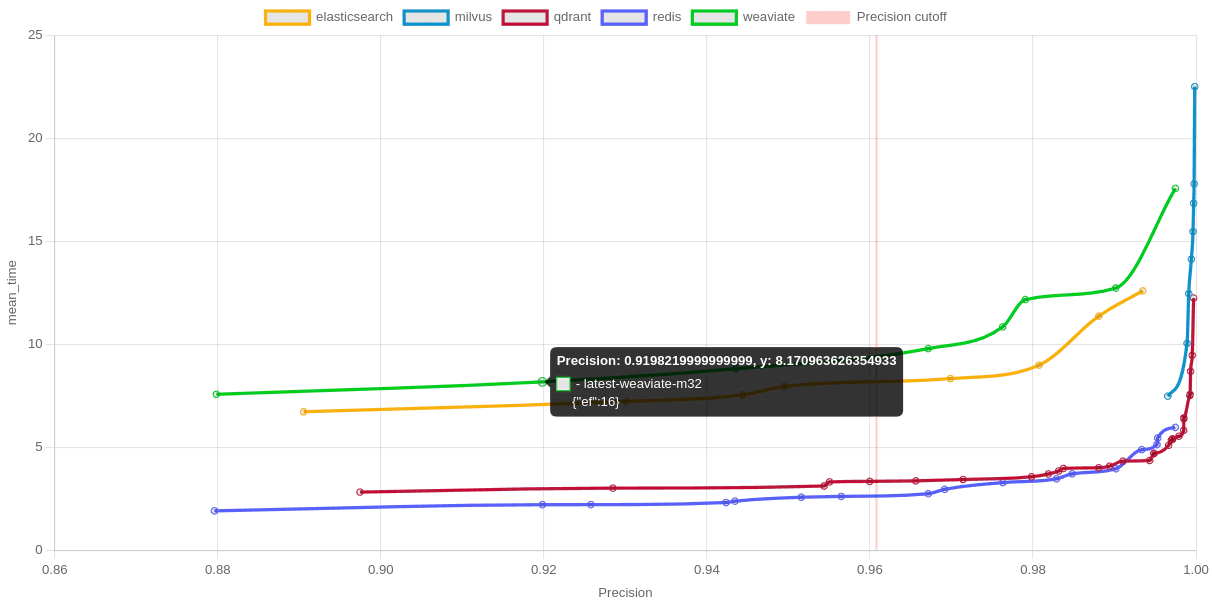
Recommended Hyper-edge Compute Nodes
The compute nodes are selected based on the following criteria:- Hybrid cloud deployment: with a mix of on-prem and cloud nodes.
- Redundancy: to ensure that the inference pipeline is always available.
- Security: to ensure that the inference pipeline is secure.
- Ruggedness: to ensure that the inference pipeline is able to withstand harsh manufacturing environments.
Inference Pipeline Options
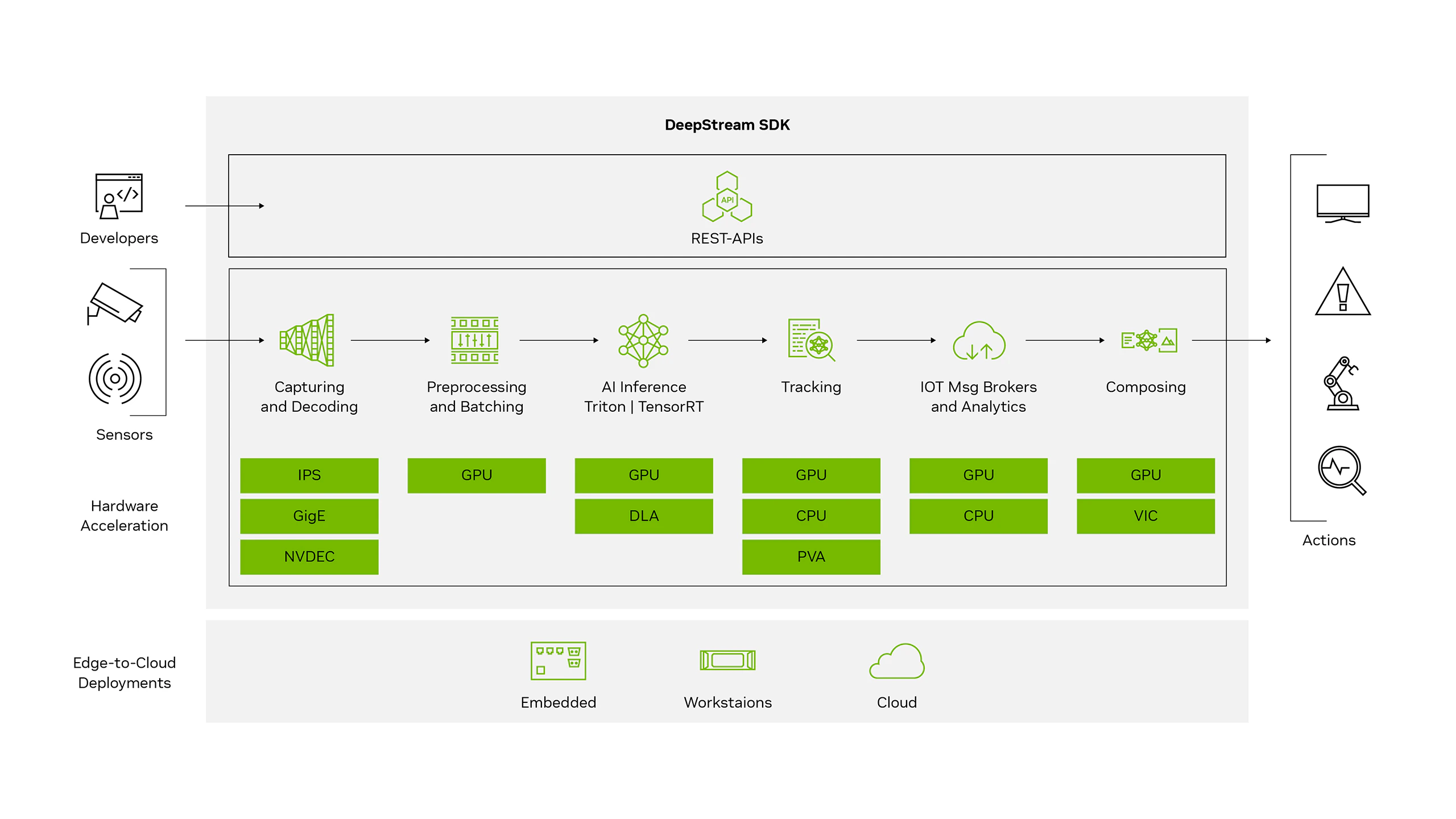
Option 1 - Deepstream SDK
This option uses a well-known framework for real-time computer vision by NVIDIA and assumes an NVIDIA accelerator card with memory sized to handle the embeddings generated by the pretrained CNN model and a small batching factor. The framework is itself based on GStreamer and is capable of handling multiple video streams in parallel, paving the way for amortizing the cost of the accelerators over multiple manufacturing machines. The Deepstream SDK is hosted in a containerized environment and is capable of interfacing with the vector store and the analytics subsystem.