Skip to main contentIntroduction
The training pipeline was built around the PyTorch framework and includes the elements shown below.
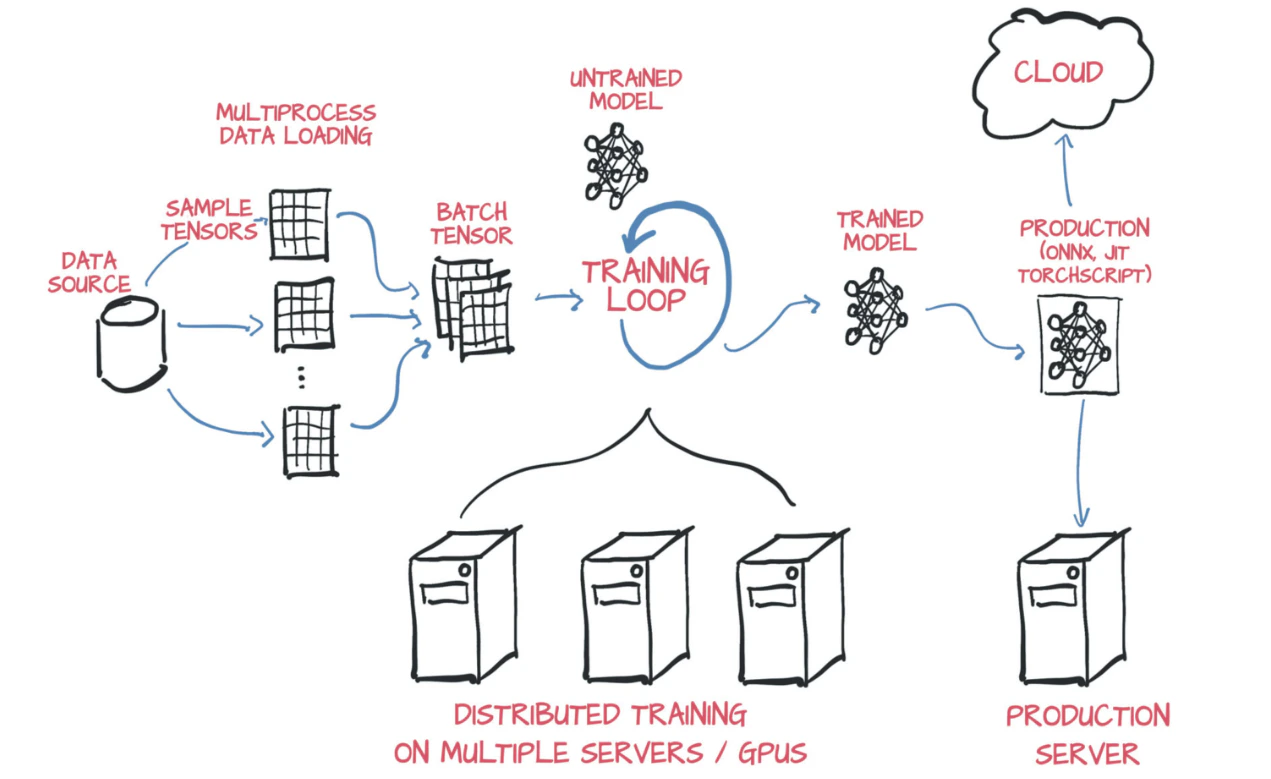 Although the models developed in other sections of representation learning include training, this section outlines what generally needs to be kept in mind when training AD models across the different approaches.
Although the models developed in other sections of representation learning include training, this section outlines what generally needs to be kept in mind when training AD models across the different approaches.
Model Repository
The trained model ends up in an S3 bucket and has a unique ID associated with the experiment ID of the training job. The experiment ID itself can track the exact version of the model development code based on the git commit.
Training Considerations
Data Pipeline Integration
The training pipeline consumes data from the data pipeline in the form of:
- Parquet files for efficient batch loading
- Transformed images with appropriate augmentations
- Train/validation splits for model evaluation
Experiment Tracking
All training runs are tracked using ClearML, which captures:
- Hyperparameters and configuration
- Training metrics (loss, accuracy)
- Model artifacts and checkpoints
- Code version and git commit
Hardware Requirements
Training anomaly detection models requires:
- GPU with sufficient VRAM for batch processing
- Fast storage for data loading
- Experiment tracking infrastructure