- Aleatoric uncertainty (), also called statistical or data uncertainty, is the irreducible noise in the data-generating process itself: sensor noise, measurement error, intrinsic randomness, label ambiguity. It is a property of the world, not of your model, so it cannot be reduced by collecting more data or choosing a better hypothesis. In object detection, for instance, bounding boxes drawn by different annotators vary slightly, and motion blur makes object boundaries genuinely ambiguous. Even with infinite training data this floor on the achievable error remains.
- Epistemic uncertainty (), also called model or knowledge uncertainty, is uncertainty about the model: the parameters you inferred from a finite training set, the regions of input space you never observed, the capacity and assumptions you imposed. It is reducible: it shrinks as the training set grows, as you improve the model, and as you tune capacity and regularization toward the optimum (the optimization from the regression section). A model trained only on adult scans, for example, is highly epistemically uncertain on pediatric ones, a gap that more representative data closes.
Two ways to write the total uncertainty
The bias-variance form above comes from the squared-error decomposition. An equivalent, model-centric statement is the law of total variance, which is the form you meet in Bayesian neural networks, Gaussian processes, and deep ensembles: The first term averages the noise the model expects given its parameters (the aleatoric floor); the second measures how much the model’s mean prediction moves as the parameters change across plausible fits (the epistemic spread). This is exactly the quantity that connects to the learning problem: the gap is largely epistemic, and training reduces it by minimizing . Even once , the aleatoric term survives, because the world itself is noisy.The data-generating process
The targets are a deterministic signal corrupted by additive Gaussian noise, The noise is the aleatoric uncertainty: even if we knew exactly, every observed would still scatter around it with variance . This is exactly the Gaussian likelihood from conditional MLE read as the data-generating truth, so is the aleatoric term that a fixed-variance maximum-likelihood fit assumes, and the conditional mean is the point prediction the model targets. The model used throughout is the degree-9 polynomial ridge regressor from that section, here with a small penalty chosen so the fit stays stable across sample sizes.Estimating epistemic uncertainty by retraining
Epistemic uncertainty lives in the randomness of : a different training set yields a different fitted model. We approximate the distribution of the predictor by drawing many independent training sets, fitting the same ridge model to each, and looking at how the predictions spread. Each thin curve below is one trained model; their spread at a given is the epistemic uncertainty there.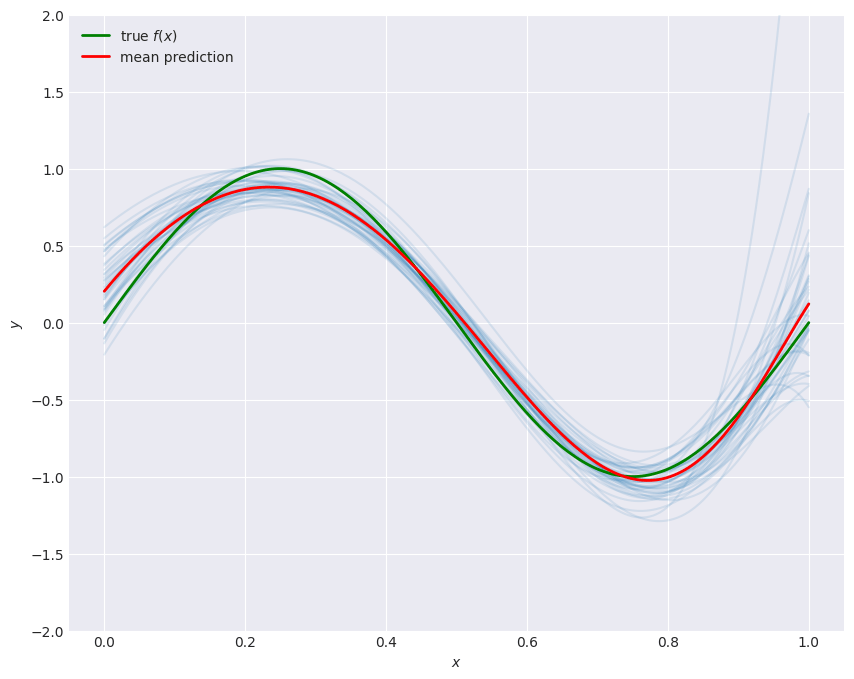
Predictive uncertainty bands
Stacking the two sources gives the total predictive uncertainty. At each the variance of a future observation is The inner band is epistemic only (model spread); the outer band adds the aleatoric noise floor. The epistemic band widens where training points are scarce (near the boundaries), while the aleatoric contribution is constant everywhere, a fixed property of the noise.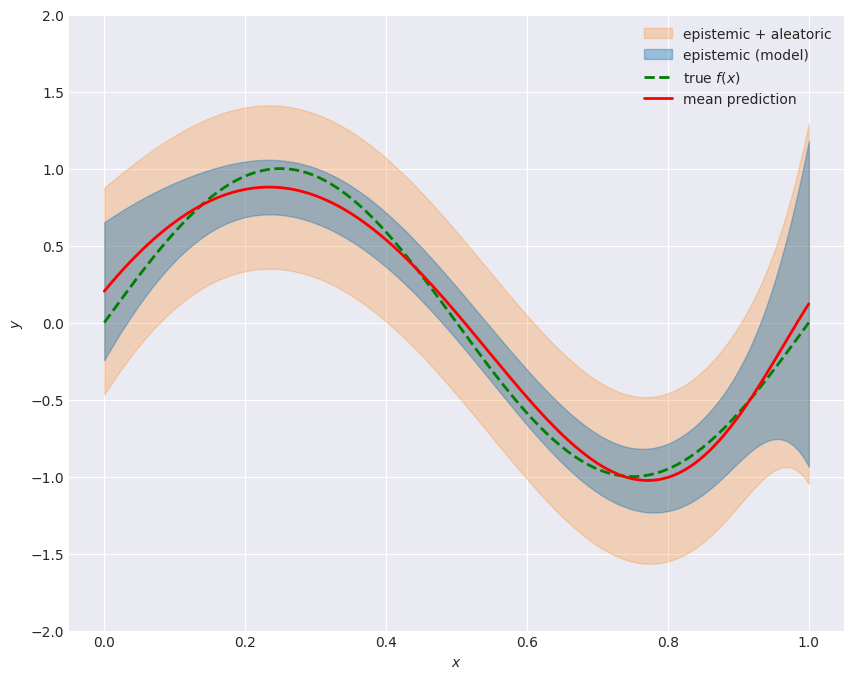
The pointwise error breakdown
Averaged over training sets, the expected squared error at each is the sum of three nonnegative pieces, The stacked plot shows their relative sizes across the input range. The grey aleatoric floor is flat; the bias and variance terms are the epistemic part, the only error the model can actually influence.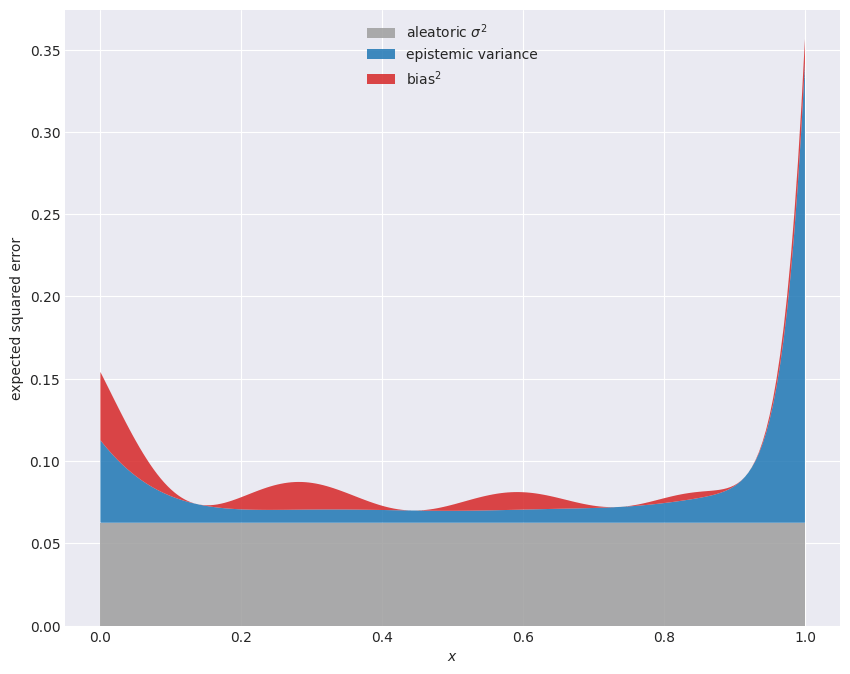
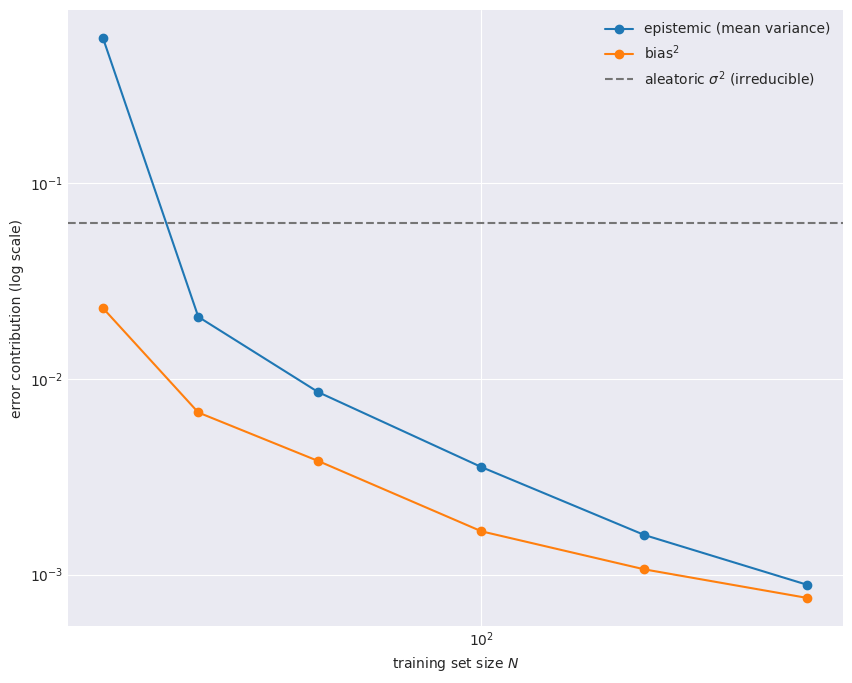
Aleatoric is irreducible; epistemic vanishes with data
The decisive difference between the two is what happens as the training set grows. Re-running the experiment for increasing , the epistemic variance falls steadily toward zero, more data pins down , while the aleatoric floor stays put. No amount of data removes it.