torch.optim. Throughout, is the parameter vector and is the gradient.
A ravine
Take an anisotropic quadratic that is steep in one coordinate and shallow in the other, The Hessian has eigenvalues and , so the condition number is . Gradient descent is stable only while , set by the steep direction, but then the shallow direction contracts by just per step. With large the steep coordinate oscillates while the shallow one barely moves: the familiar zigzag down a narrow valley.Momentum
Momentum accumulates a running velocity that averages successive gradients. Oscillating components (the steep direction) cancel, while the consistent component (the shallow floor) builds up, so the iterate accelerates along the valley instead of bouncing across it: with momentum coefficient . Nesterov momentum evaluates the gradient at a look-ahead point , which corrects overshoot and usually converges a little faster.Adaptive methods: RMSProp and Adam
A different fix rescales each coordinate by its own recent gradient magnitude, so steep directions take smaller steps and shallow directions larger ones automatically. RMSProp keeps an exponential average of squared gradients and divides by its root, Adam combines this with momentum, tracking averages of both the gradient () and its square (), each bias-corrected, Each optimizer below is a small step function that reads and updates its own state; a shared runner iterates it and records the path.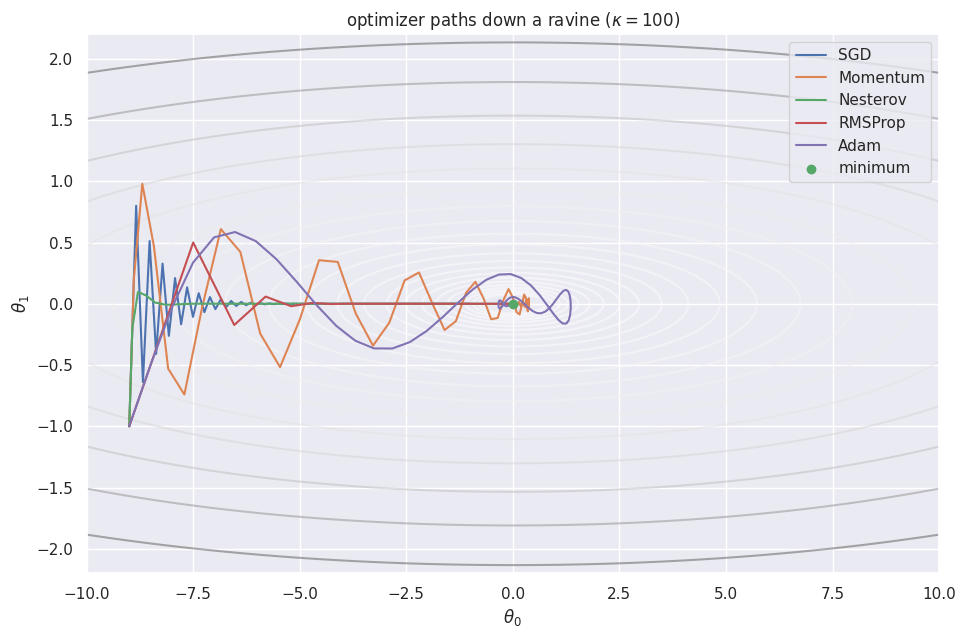
Saddle points
In high dimensions most critical points where the gradient vanishes are not minima but saddles, low along some directions and high along others. A clean two-dimensional model is with a saddle at the origin. Starting almost on the ridge () the gradient in the escape direction is tiny, so plain gradient descent and momentum dawdle near the origin, while the per-coordinate scaling in RMSProp and Adam amplifies the weak direction and breaks away sooner.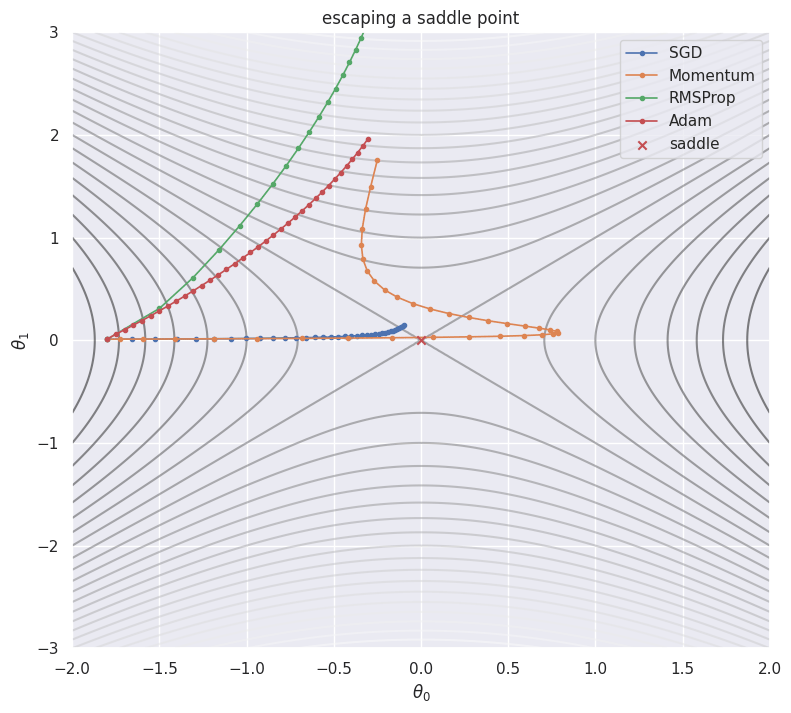
The same optimizers in PyTorch
torch.optim ships these as one-line choices. Vanilla SGD takes a momentum argument, and Adam is its own class. Optimizing the ravine through autograd reproduces what you built by hand.
Takeaways
- Plain gradient descent is limited by the steepest direction, so on an ill-conditioned ravine it zigzags and the shallow direction crawls.
- Momentum averages gradients into a velocity that cancels the oscillation and accelerates along the valley; Nesterov sharpens this with a look-ahead gradient.
- Adaptive methods (RMSProp, Adam) rescale each coordinate by its own gradient history, which both fixes the conditioning and helps escape saddle points where one direction is nearly flat.
- Adam is momentum plus per-coordinate scaling with bias correction, the common default; well-tuned SGD with momentum often matches or beats it on large problems.
torch.optimprovides all of these; the update rules are exactly the ones implemented here by hand.
References
- Goodfellow, I., Vinyals, O., Saxe, A. (2014). Qualitatively characterizing neural network optimization problems.
- Kingma, D., Ba, J. (2014). Adam: A Method for Stochastic Optimization.