The dataset
Read the daily grid-load cycle as your regression target: the input is normalized time across one day and the output is the system-wide load. You fetch one real day of MISO load from the gridstatus.io API, standardize it to zero mean and unit variance, and then sample just ten readings as the training set, deliberately small so a degree-9 polynomial can overfit it, the same regime the closed-form page studied. The remaining readings of the day are held out to score the regularization strength .MISO is the Midcontinent Independent System Operator, the regional grid operator that runs the wholesale electricity market and balances generation against demand across 15 US states and the Canadian province of Manitoba. The daily rise-and-fall you are modeling is the real load pattern published on the gridstatus.io MISO load dataset; the figure below is one real day of it, pulled from the 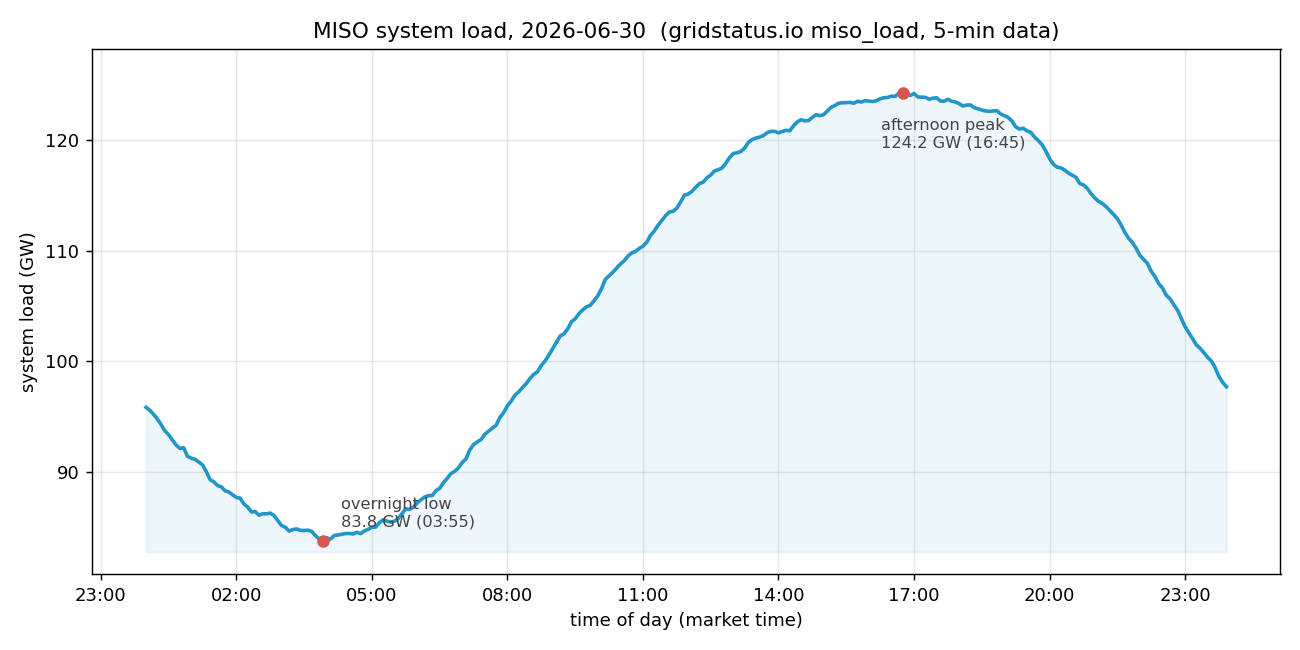
miso_load dataset via the gridstatus API.miso_load dataset.Getting this prediction wrong is not academic. Operators schedule generation ahead of time against a load forecast, and the grid must match supply to demand second by second. Underpredict and too little generation is online to meet demand, forcing emergency purchases, frequency drops, and in the worst case load shedding (rolling blackouts); overpredict and expensive units are committed and paid for nothing. A model that generalizes poorly, one that chases the noise instead of the true demand curve, feeds a bad forecast straight into grid stability.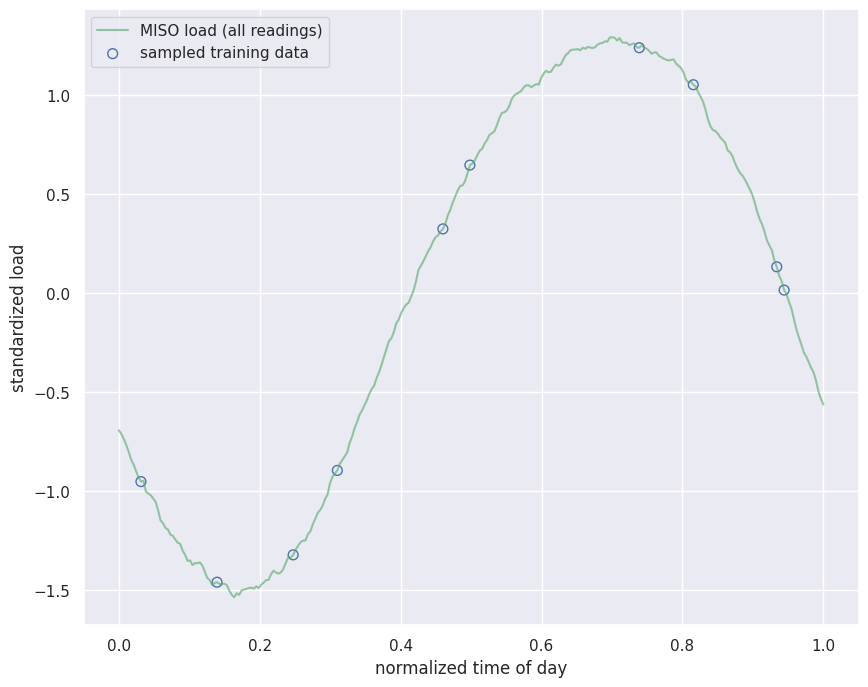
Standardized polynomial features
The model is a degree-9 polynomial, . Raw monomials on span many orders of magnitude, which makes the gradient steps lopsided and the penalty act unevenly across coordinates. Standardizing each feature to zero mean and unit variance puts every coordinate on the same footing, so a single learning rate and a single are meaningful and the value of transfers directly from the closed-form page, which uses the same standardized features. The intercept is absorbed by centering the targets at .The regularized objective and the SGD update
SGD minimizes the same ridge objective the closed-form page solves exactly, the sum of squared residuals plus an penalty, Its minimizer satisfies the normal equations , so using this convention makes here identical to the closed-form . Each SGD step draws a mini-batch of size and follows an unbiased estimate of the full gradient, scaling the batch sum by :Choosing by nested hyperparameter search
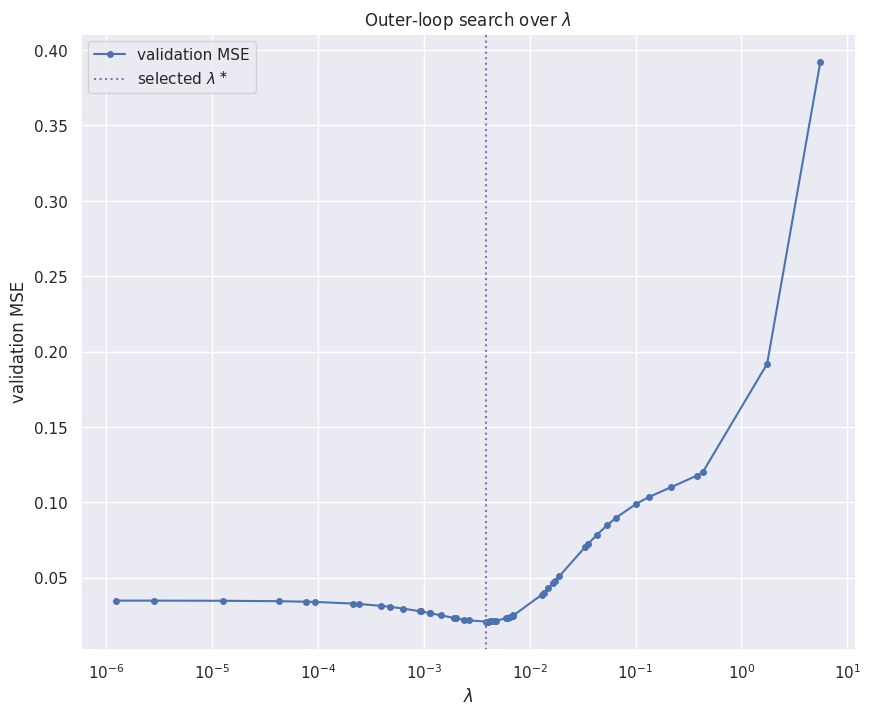
The regularization strength is a hyperparameter: it cannot be read off the training loss, which always prefers because less shrinkage fits the ten points more tightly. It has to be chosen by held-out performance, and that takes two nested loops.- The inner loop is a full SGD fit of the degree-9 model at a fixed ; it returns the validation error of the trained weights.
- The outer loop is the hyperparameter search. Optuna proposes a candidate over a wide logarithmic range, reads back the validation error from the inner fit, and uses it to propose the next candidate, converging on the that minimizes held-out error.
The selected fit
With chosen by the search, fit the degree-9 model at that value and compare the iterative SGD solution against the closed-form ridge solution at the same . They should coincide: SGD is just an iterative route to the same regularized optimum.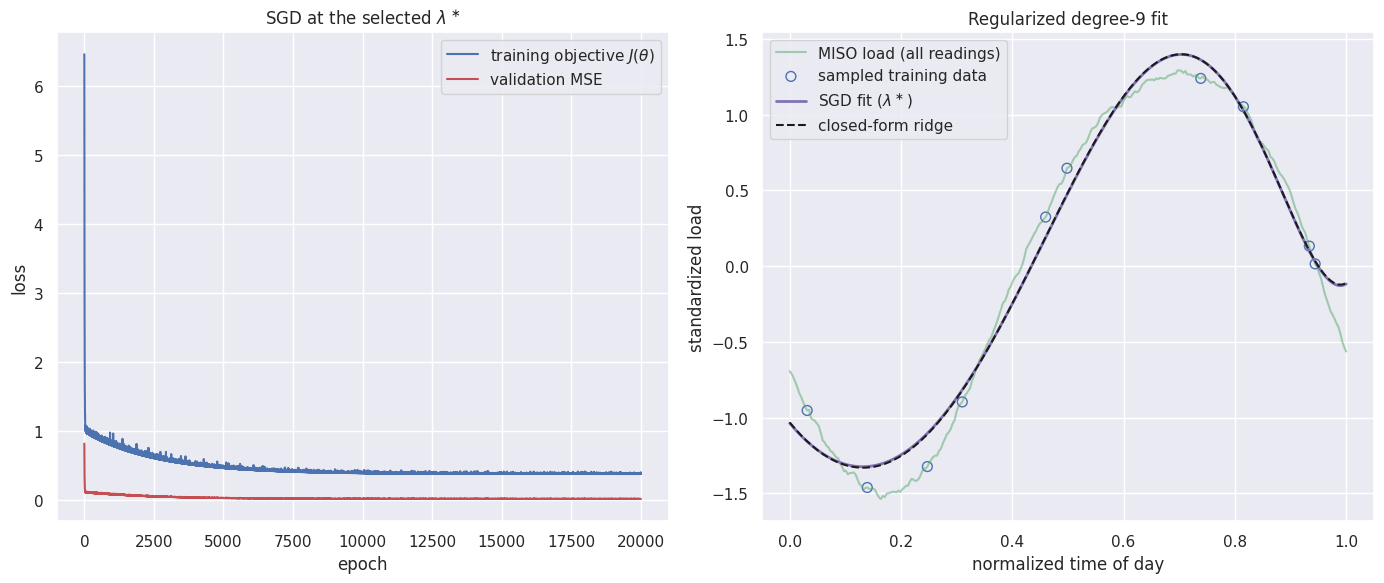
Takeaways
- Choosing is model selection by nested search: an outer Optuna loop proposes over a wide logarithmic range, and an inner SGD loop trains the degree-9 model at each candidate and reports its held-out error. The training loss alone cannot choose , it always prefers less shrinkage.
- SGD minimizes the regularized empirical risk: the penalty enters the gradient as , shrinking the weights every step and curbing the degree-9 overfitting. At the selected the iterative SGD fit and the direct closed-form solve reach the same regularized optimum.
- Standardizing both the features and the load makes a single meaningful across every coordinate, so the outer search operates on a well-conditioned problem. Tuned from scratch on this real grid-load sample, the search settles near , the same order as the the closed-form page found on a unit-variance sinusoid, an independent confirmation rather than a borrowed constant.
References
- Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M., Pfau, D., et al. (2016). Learning to learn by gradient descent by gradient descent.
- Bottou, L., Curtis, F., Nocedal, J. (2016). Optimization Methods for Large-Scale Machine Learning.
- Keskar, N., Mudigere, D., Nocedal, J., Smelyanskiy, M., Tang, P. (2016). On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima.