Odds and the Logistic Sigmoid
If is a probability of an event, then the ratio is the corresponding odds, the ratio of the event occurring divided by not occurring. For example, if a race horse runs 100 races and wins 25 times and loses the other 75 times, the probability of winning is 25/100 = 0.25 or 25%, but the odds of the horse winning are 25/75 = 0.333 or 1 win to 3 loses. In the binary classification case, the log odds is given by The logistic function of any number is given by: and is plotted below. It maps its argument to the “probability” space [0,1].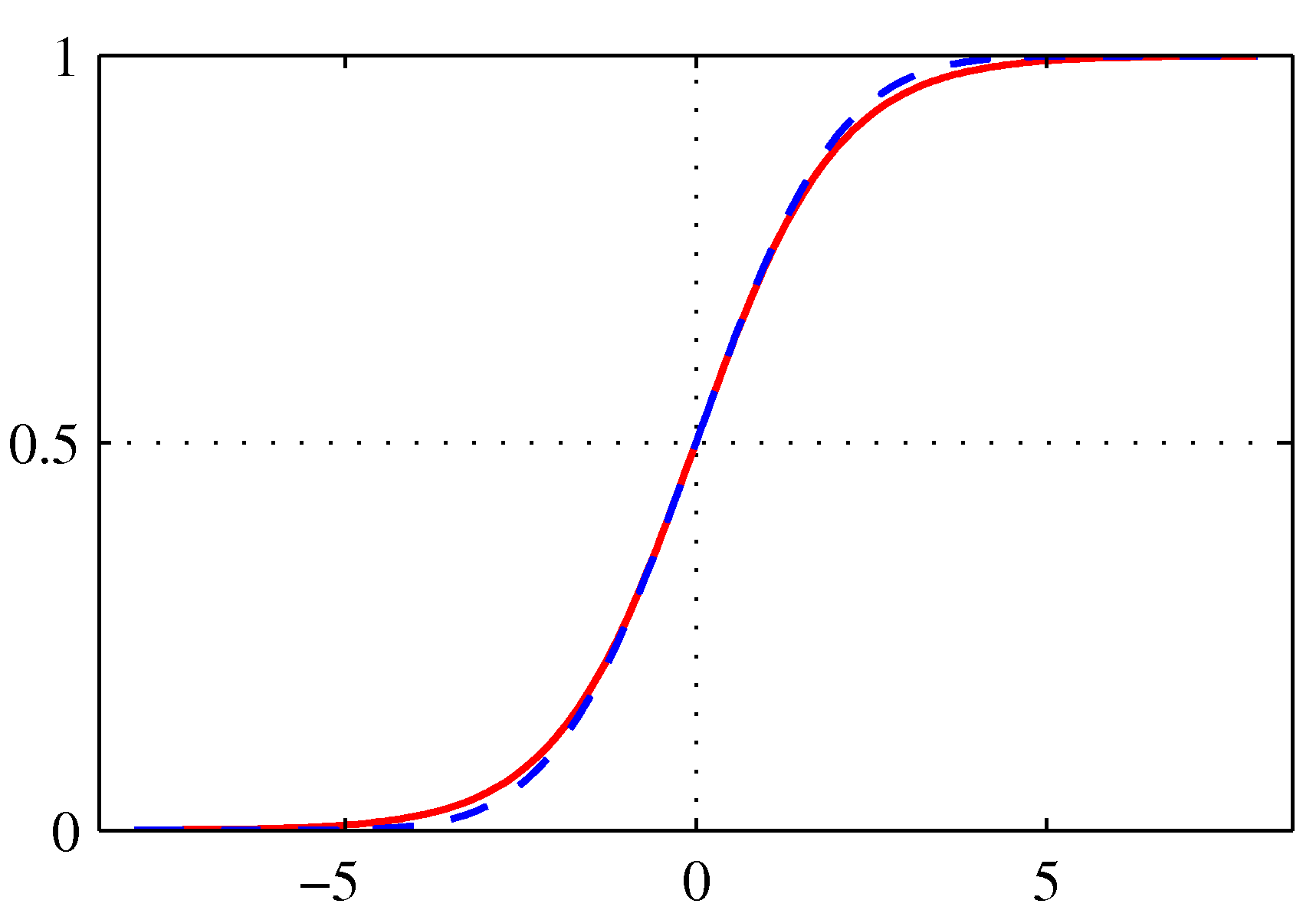
Binary case
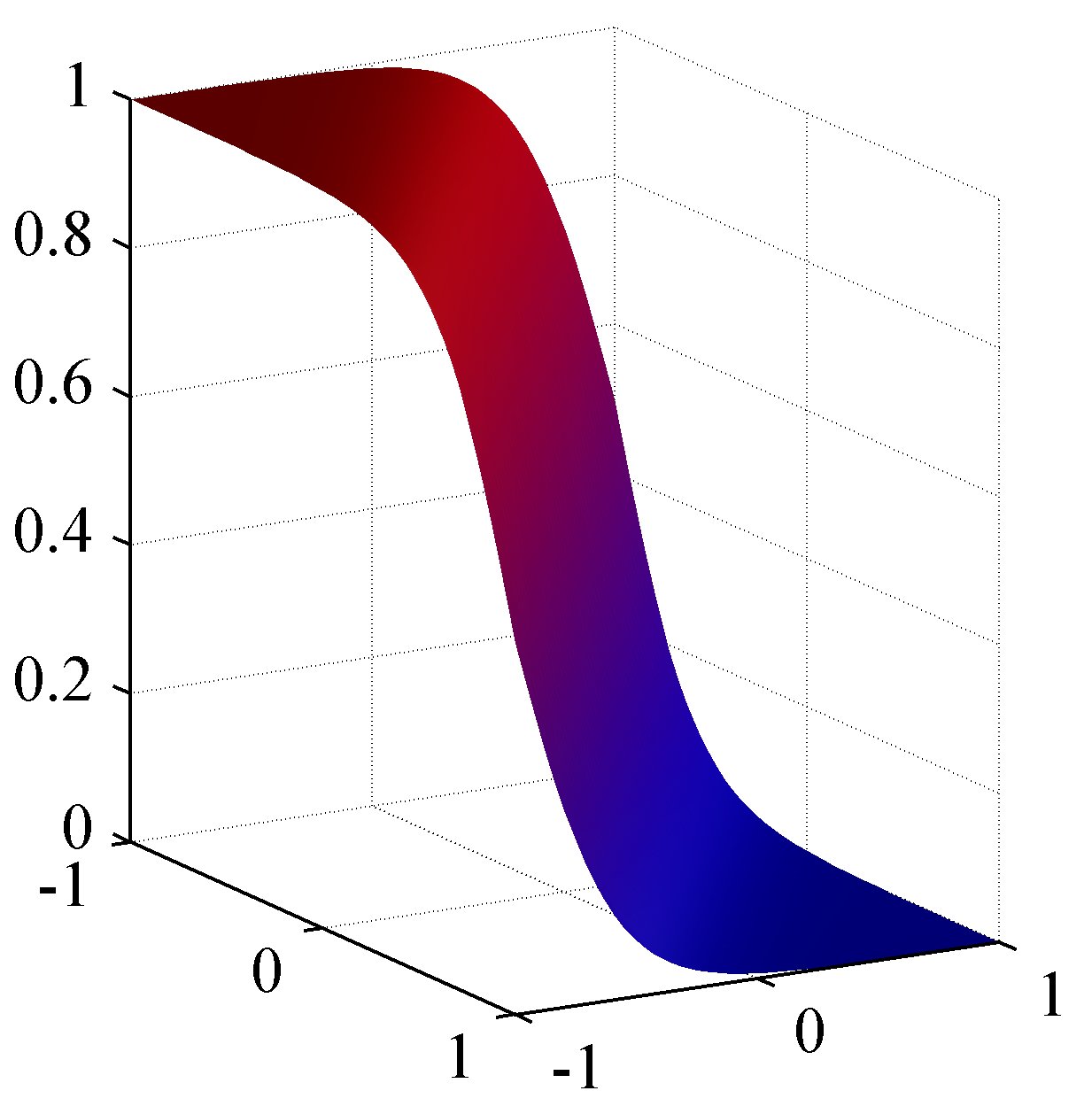
If we consider the two class problem, we can write the posterior probability as, where . Given the posterior distribution above, we have for the specific linear activation, This model is called logistic regression - despite its name its models a classification task. The figure below shows the corresponding posterior distribution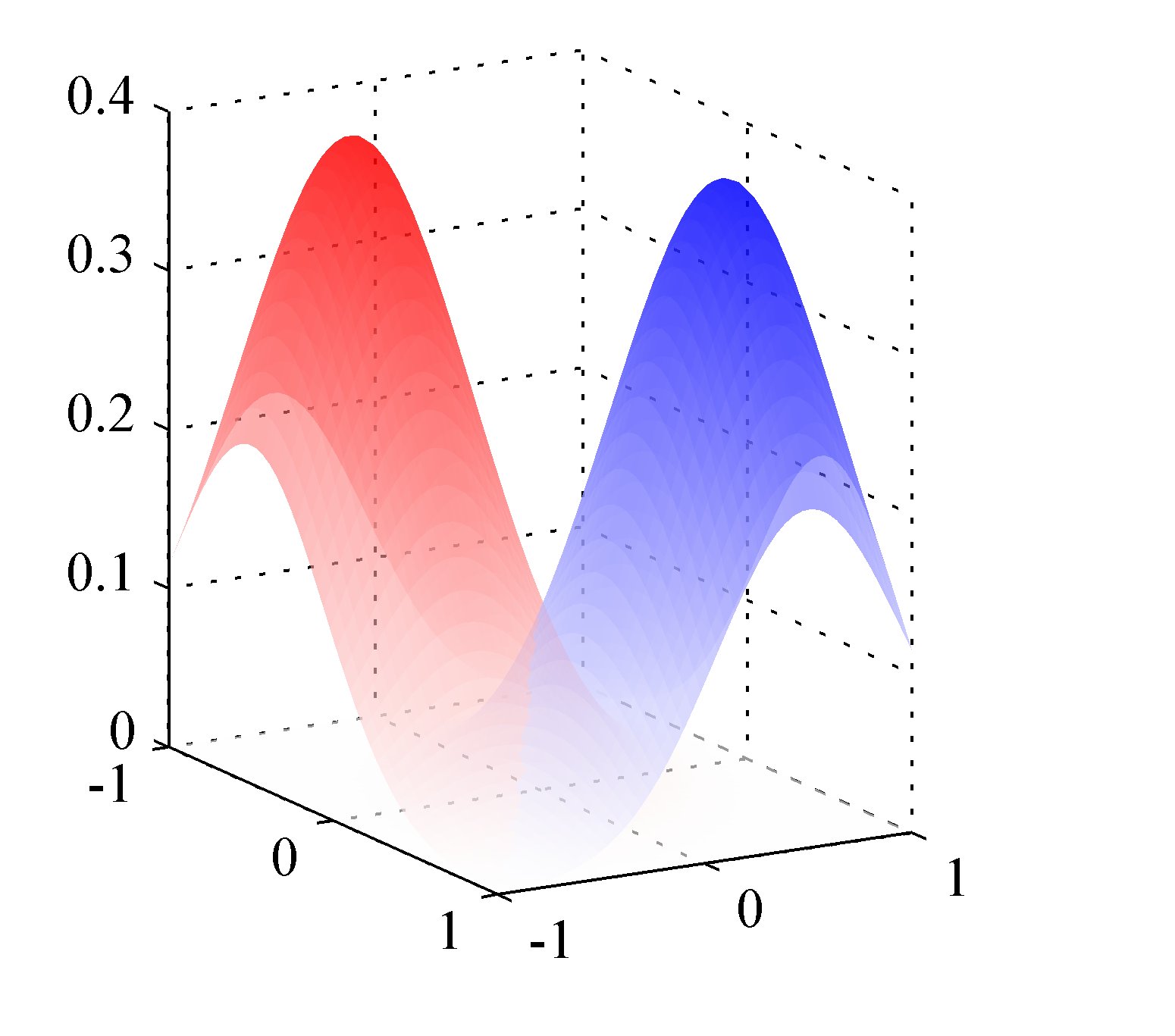
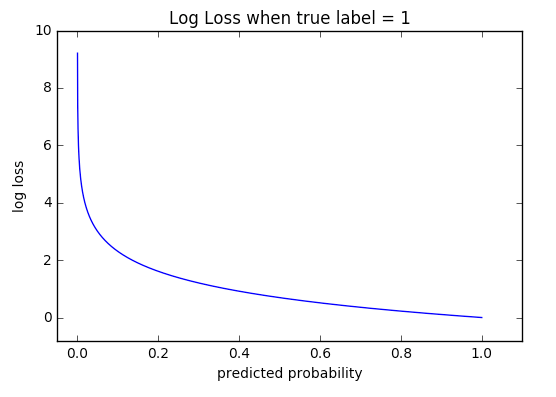
which is called cross entropy loss function - probably the most widely used error function (in classification as well as regression) due to its information theoretic roots.
Optimizing LR parameters with SGD
Minimizing the Binary CE (log-loss) starts from the negative log likelihood: We need to minimize it with respect to and this requires calculating its gradient. The gradient can be derived to be: The expression above defines the batch gradient decent algorithm. We can then readily convert this algorithm to mini-batch SGD by considering mini-batch updates of size i.e. instead of we sum over where the later is a hyperparameter. Key references: (Letham et al., 2015; Lundberg & Lee, 2017; Ribeiro et al., 2016; Tran et al., 2016; Zhang et al., 2018)References
- Letham, B., Rudin, C., McCormick, T., Madigan, D. (2015). Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model.
- Lundberg, S., Lee, S. (2017). A Unified Approach to Interpreting Model Predictions.
- Ribeiro, M., Singh, S., Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier.
- Tran, D., Kucukelbir, A., Dieng, A., Rudolph, M., Liang, D., et al. (2016). Edward: A library for probabilistic modeling, inference, and criticism.
- Zhang, B., Lemoine, B., Mitchell, M. (2018). Mitigating Unwanted Biases with Adversarial Learning.