Why DDIM
In the DDPM tutorial you trained a noise predictor and used the stochastic DDPM reverse chain to generate samples. Two practical pain points come up immediately:- It is slow. DDPM samples by stepping through every timestep . With or that is hundreds of network calls per sample.
- It is non-deterministic. Even with a fixed initial noise , the reverse chain injects fresh noise at each step, so you cannot reproduce a specific sample or do clean latent interpolation.
- Lets you skip timesteps (e.g. take 50 steps instead of 500, a 10× speedup).
- Has a tunable noise level where recovers DDPM and is fully deterministic.
Same target distribution as the DDPM tutorial
The 3-cluster MoG, seed 42, 300 points. We then train the same MLP noise predictor with the same DDPM objective.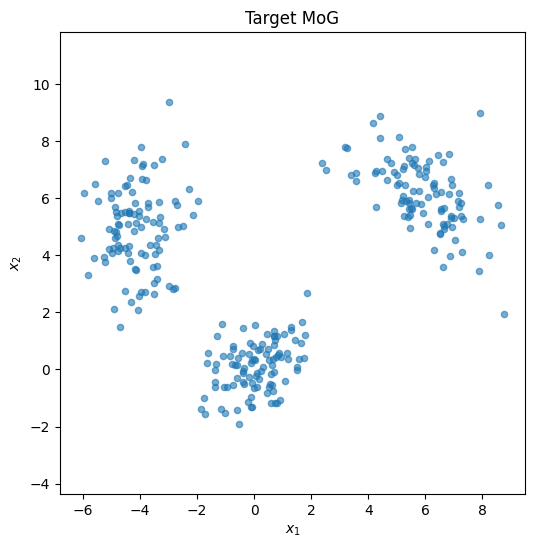
Forward (noising) process
Same fixed Markov noising chain as DDPM: . We visualize a few specific timesteps so the noise schedule is concrete before training.
Train the noise predictor (same architecture and objective as DDPM)
DDIM and DDPM share the training step, only the sampler differs.The DDIM update rule
Given the trained , define a strictly increasing sub-sequence . The DDIM reverse step from to is with the predicted clean sample and the per-step noise scale Two regimes:- , full noise. The sampler becomes equivalent to DDPM (after accounting for sub-sequence corrections).
- , deterministic. The reverse step is a pure ODE-like update, disappears, and the same always produces the same .
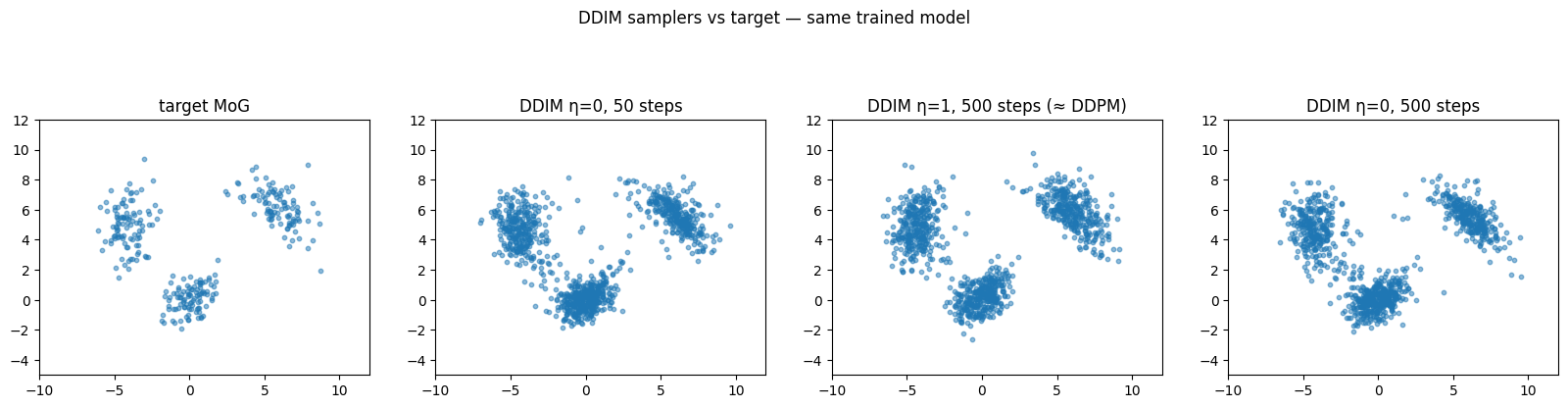
DDIM in 50 steps versus DDPM-equivalent in 500 steps
Three samplers, same model, 1000 generated points each:- DDIM η=0, 50 steps, fast, deterministic.
- DDIM η=1, 500 steps, equivalent to DDPM, sanity check.
- DDIM η=0, 500 steps, deterministic with the full timestep grid.
Determinism: same noise, same sample
With the sampler is a deterministic function of the initial noise . Run it twice with the same and you get bit-identical outputs, regardless of how many steps you take.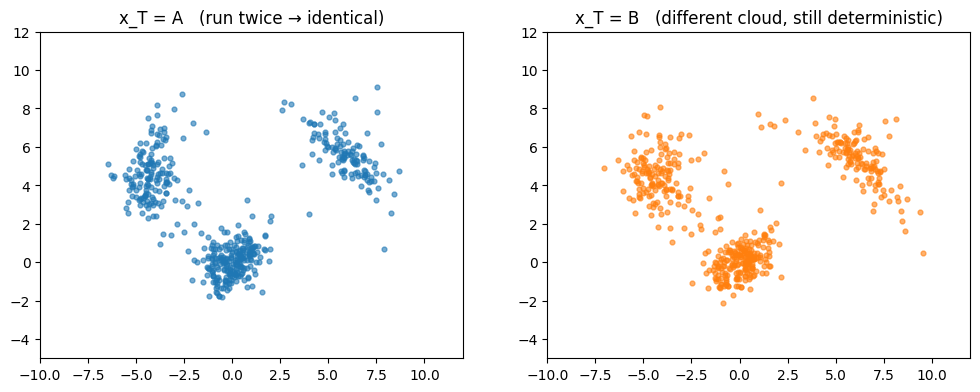
Latent interpolation: slerp on
Because DDIM is a deterministic invertible map, you can pick two endpoints in noise space and walk a path between them; each intermediate noise decodes to a coherent point in data space. The right path on the unit sphere is spherical linear interpolation (slerp), which preserves the Gaussian magnitude.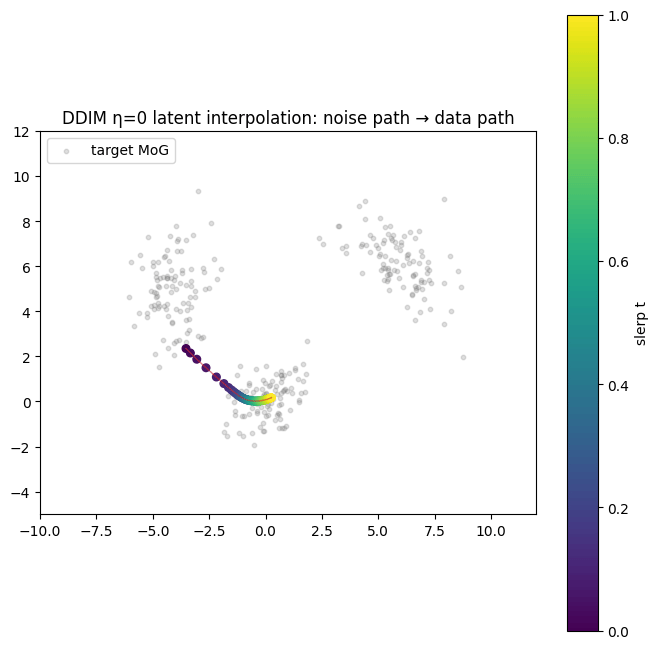
Connections to other concepts
- Sampler decoupling. Training trains; sampling samples. DDIM proves you can swap samplers freely as long as marginals are preserved. Modern stacks ship many samplers (DDIM, DPM-Solver, Euler, Heun, …) on top of the same DDPM-trained network.
- Step count is a knob, not a constant. Image-generation pipelines routinely use 20-50 DDIM steps in production where DDPM would take 1000.
- Deterministic = invertible. DDIM gives you a noise-to-data map you can run forwards and backwards, enabling editing and interpolation.
- Bridge to flows and ODEs. Deterministic DDIM is the discretization of a probability-flow ODE. That connection underlies most of the recent diffusion-model speedup work (consistency models, rectified flow, …).
- Score-based unification. The Score MoG Tutorial makes that ODE bridge concrete: train on the same MoG, then sample via annealed Langevin or the reverse-time SDE. Deterministic DDIM is the probability-flow ODE limit of that score-SDE.
References
- Song, Meng, Ermon. Denoising Diffusion Implicit Models. ICLR 2021. arxiv.org/abs/2010.02502
- Ho, Jain, Abbeel. Denoising Diffusion Probabilistic Models. NeurIPS 2020. arxiv.org/abs/2006.11239
- Song et al. Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021. arxiv.org/abs/2011.13456