From KL divergence to the ELBO
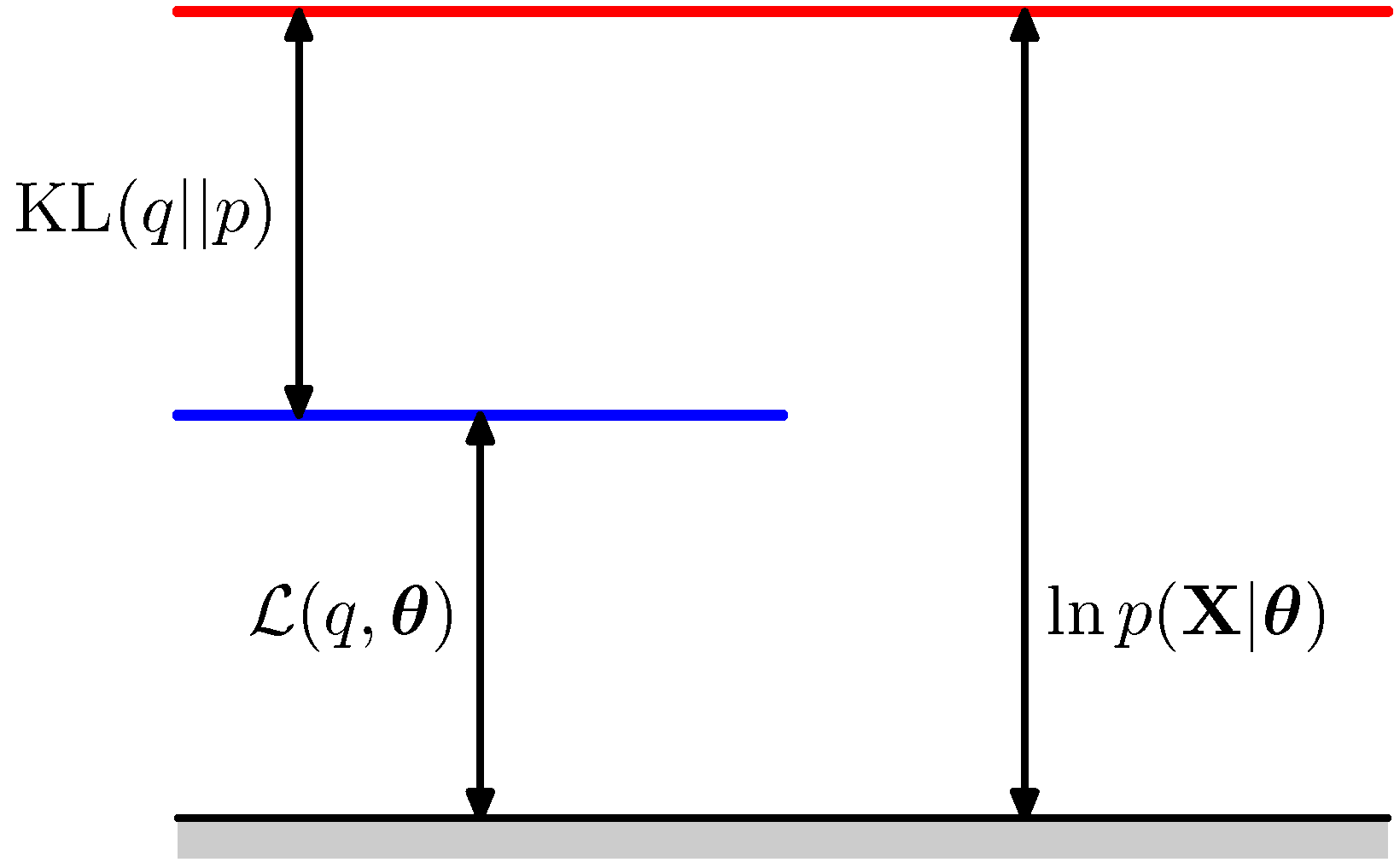
During the treatment of entropy, we have met the concept of relative entropy or KL divergence that measures the “distance” between two distributions referenced on one of them. We will use KL divergence to obtain a suitable loss function that will be used in the optimization of this approximation via the network. Ultimately we are trying to minimize the KL divergence between the true posterior and the approximate posterior : Applying Bayes’ rule to replace the posterior : Separating the log of the product: Distributing the sum: Since does not depend on , it can be pulled out of the sum. And since is a valid distribution, : Rearranging: The bracketed quantity is the Evidence Lower Bound (ELBO). It is a function of both the encoder parameters (through ) and the decoder parameters (through the joint ).Why is it a lower bound?
The KL divergence is non-negative, with equality if and only if almost everywhere. Dropping the KL term from the equality above therefore turns it into an inequality: The KL is the gap between the bound and the true marginal log-likelihood. The closer the encoder approximates the true posterior, the tighter the bound.A practical form: reconstruction minus KL
The joint factors as , where is the (fixed, parameter-free) prior — typically . Substituting and expanding the log: This is the form actually computed in code:- The reconstruction term is the expected log-likelihood of the observed data under the decoder when is drawn from the encoder. Maximizing it pushes the decoder to put high probability on real data.
- The KL regularizer pulls the encoder’s posterior toward the prior . This prevents the encoder from collapsing into a different point distribution for every datapoint and is what makes the latent space dense and continuous.
Why is the ELBO useful for optimization?
Re-arrange the identity to put the ELBO on one side: Joint SGD over on the ELBO does two coupled jobs at once:- Encoder step (gradients on ). With fixed, is constant in , so maximizing over is exactly equivalent to minimizing the posterior KL. The encoder learns to track the true posterior, tightening the bound.
- Decoder step (gradients on ). The ELBO is a lower bound on , so increasing over raises a lower bound on the marginal log-likelihood. The marginal itself rises only as fast as the bound is tight; the encoder’s quality controls the slack.