
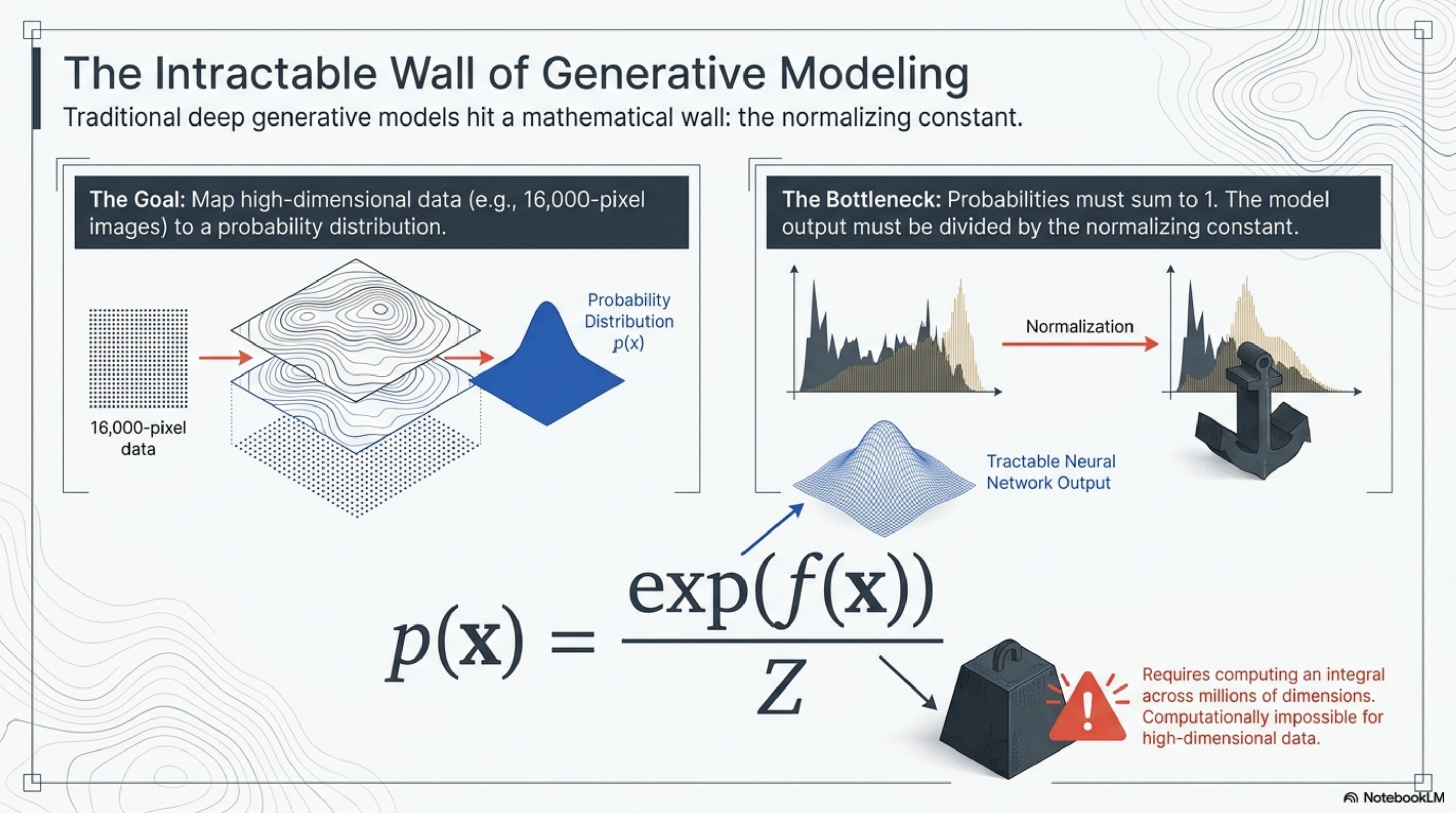
The intractable wall
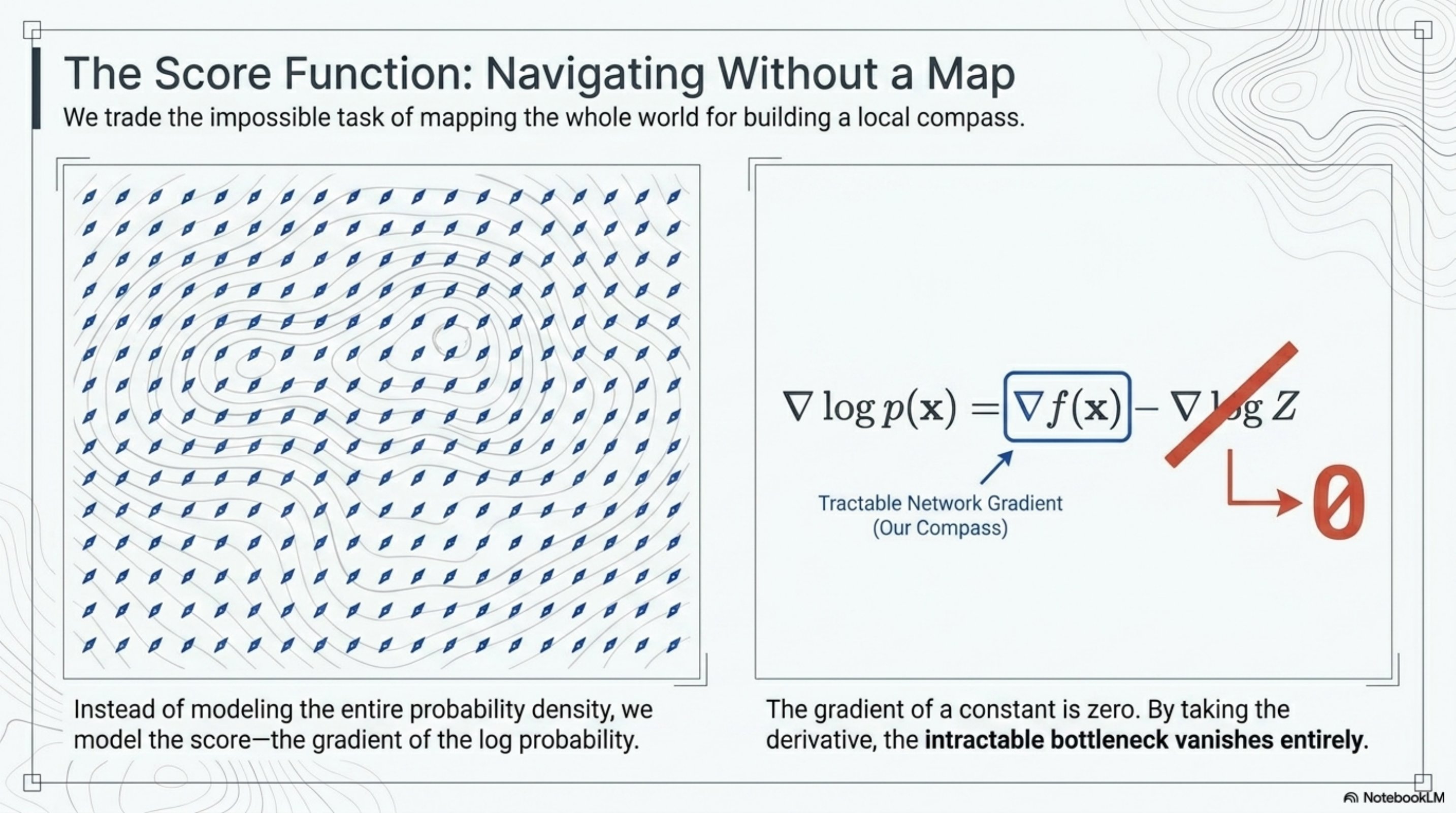
Trade the map for a compass: the score function
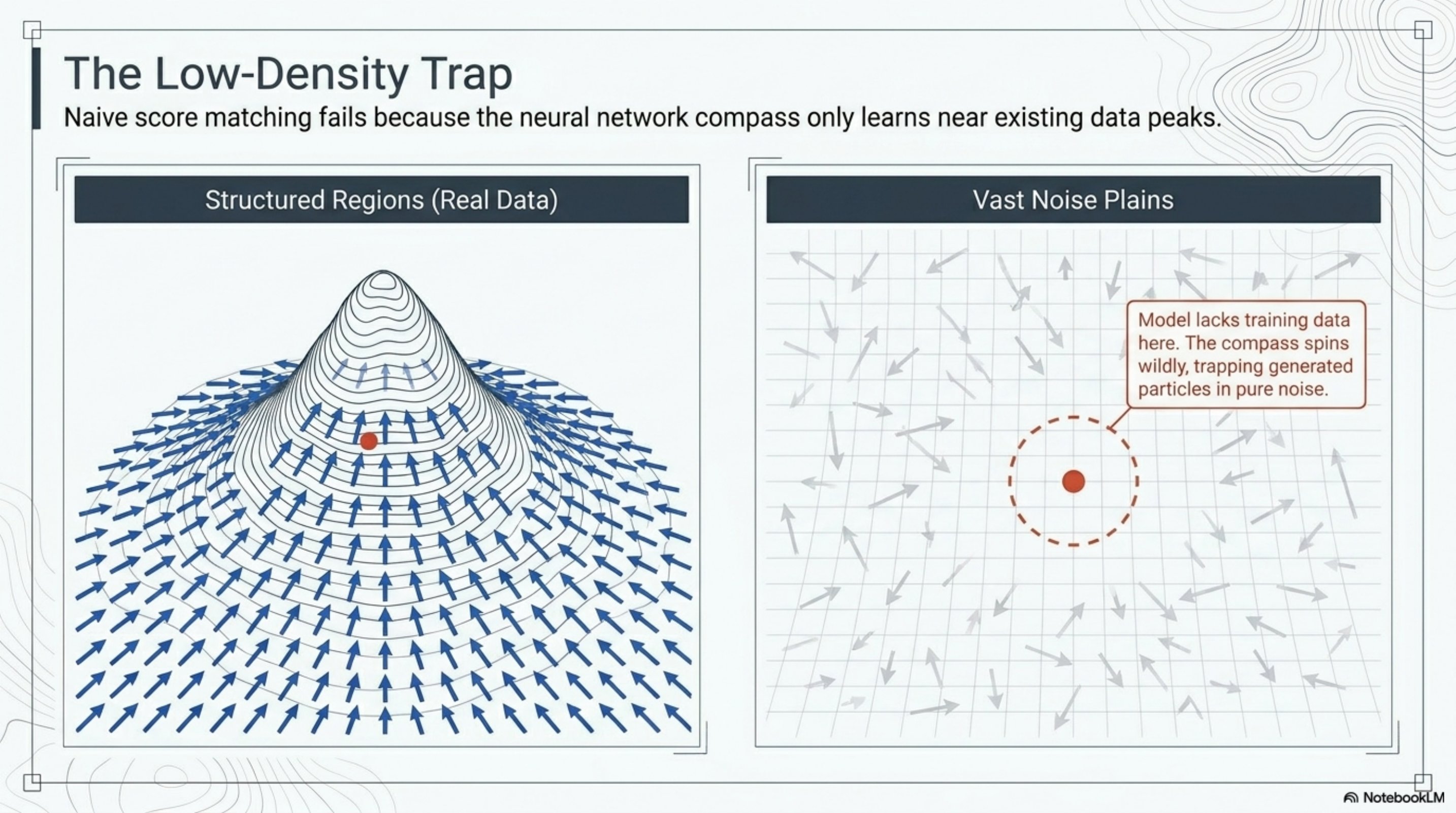
The low-density trap
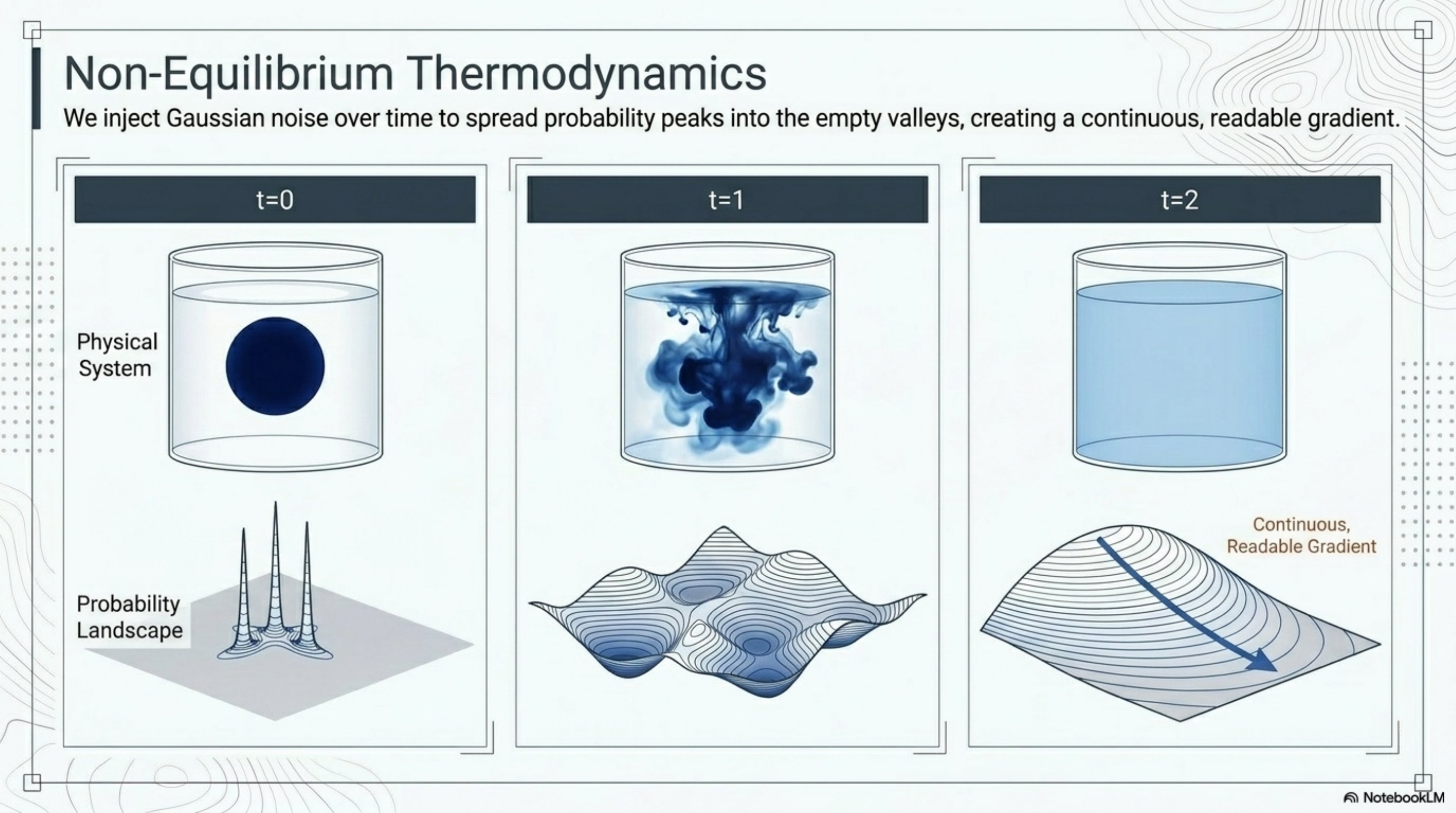
Noise as a bridge
The forward SDE
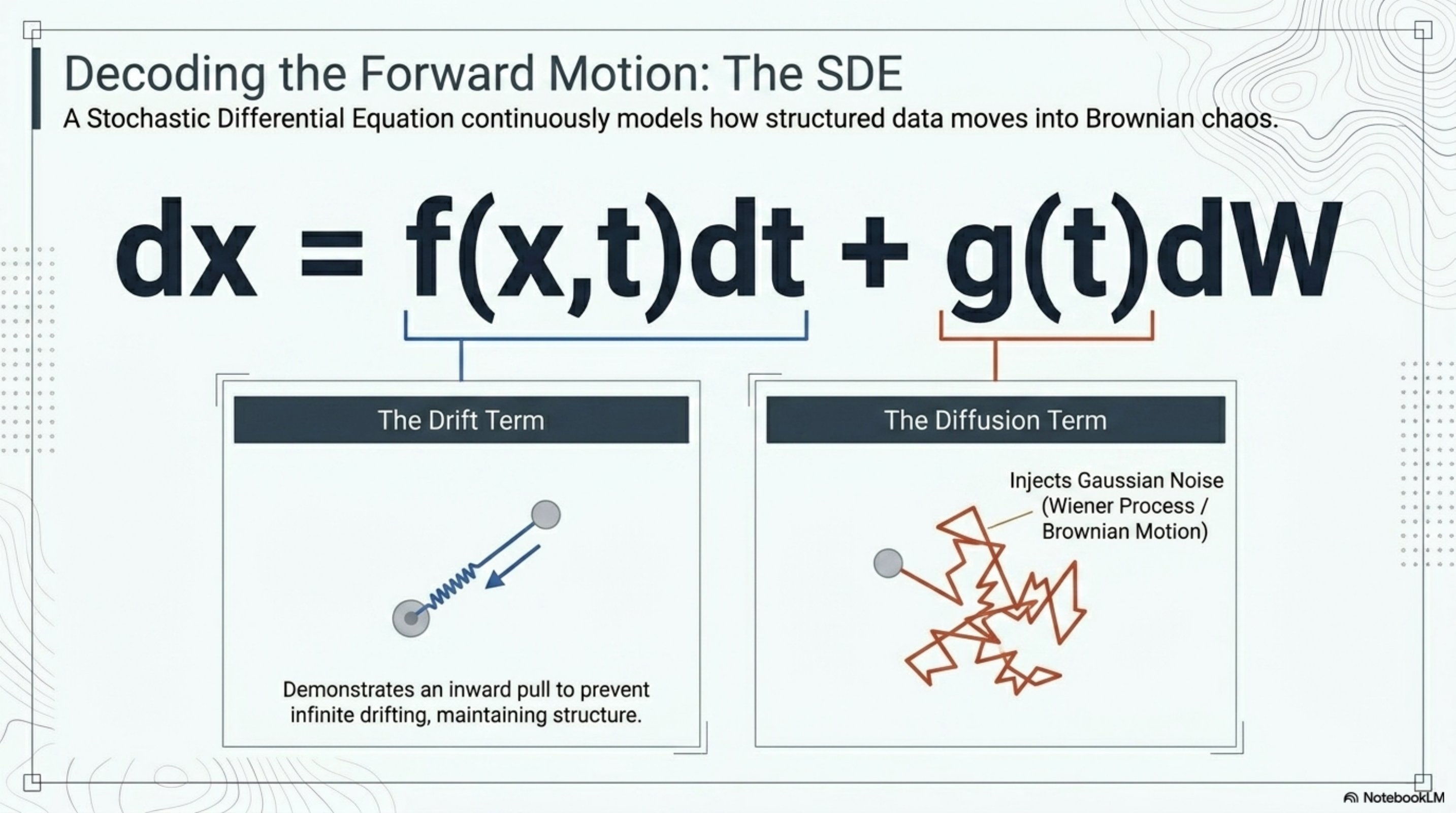
- Drift : a deterministic pull. In Variance-Preserving (VP) SDEs the drift contracts toward the origin to stop variance from blowing up; in Variance-Exploding (VE) SDEs it is zero.
- Diffusion : a scalar volatility schedule controlling how fast Gaussian noise is injected.
Training the score network

DSM is the standard choice. With Gaussian perturbation :
so the DSM loss reduces to a re-weighted noise-prediction loss — this is exactly the DDPM training objective up to a -dependent constant. The DDPM noise predictor and the score network are the same model with a different sign and scale.
Lecture: ≈ 22:00–34:00 walks through all three variants.
Reversing the SDE
![The reverse SDE equation dx = [f(x,t) − g²(t) ∇ log p(x)] dt + g(t) dW̄, with the score term highlighted as 'our trained neural network model'. Below: a curved arrow leading from a noisy random-pixel image on the right back to a clean data sample on the left, with compass icons marking each integration step.](https://mintcdn.com/aegeanaiinc/2VQk5QOBgDu4yUFC/aiml-common/lectures/diffusion/score-based/images/topo-08.png?fit=max&auto=format&n=2VQk5QOBgDu4yUFC&q=85&s=b9b631f46a5c3a1e5d74c05f9ec9205a)
Two solvers: stochastic vs deterministic
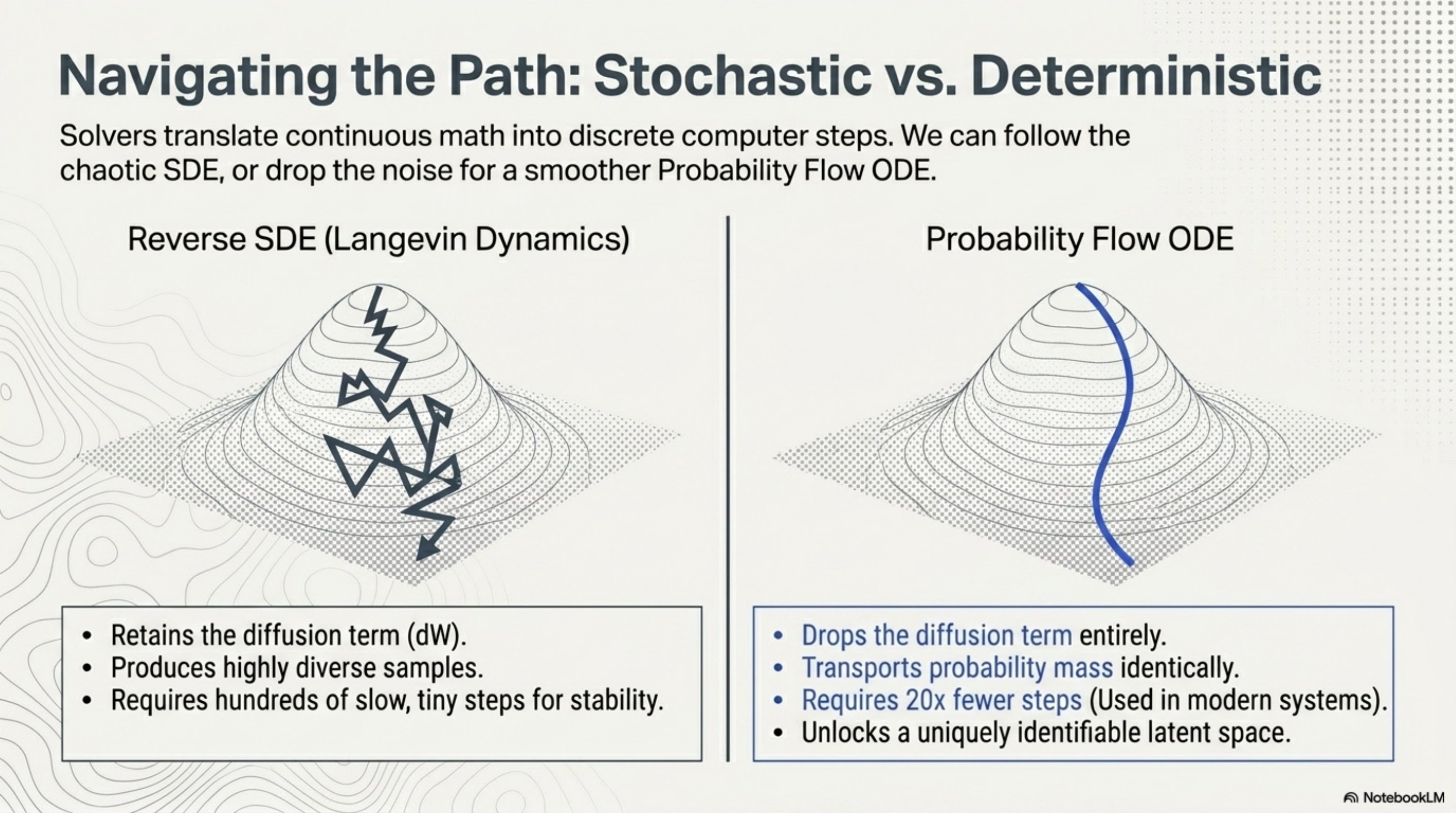
- Fewer steps. ODE solvers (Heun, DPM-Solver, RK45) converge in 20–50 NFEs versus the 500–1000 needed by reverse-SDE samplers. This is what production systems use.
- A bijection between data and noise. The ODE is invertible. Each data point maps to a unique latent code in the prior, which gives you exact log-likelihoods (via the change-of-variables formula and Hutchinson’s estimator) and a meaningful semantic latent space — for free, after training.
Conditional generation via Bayes’ rule
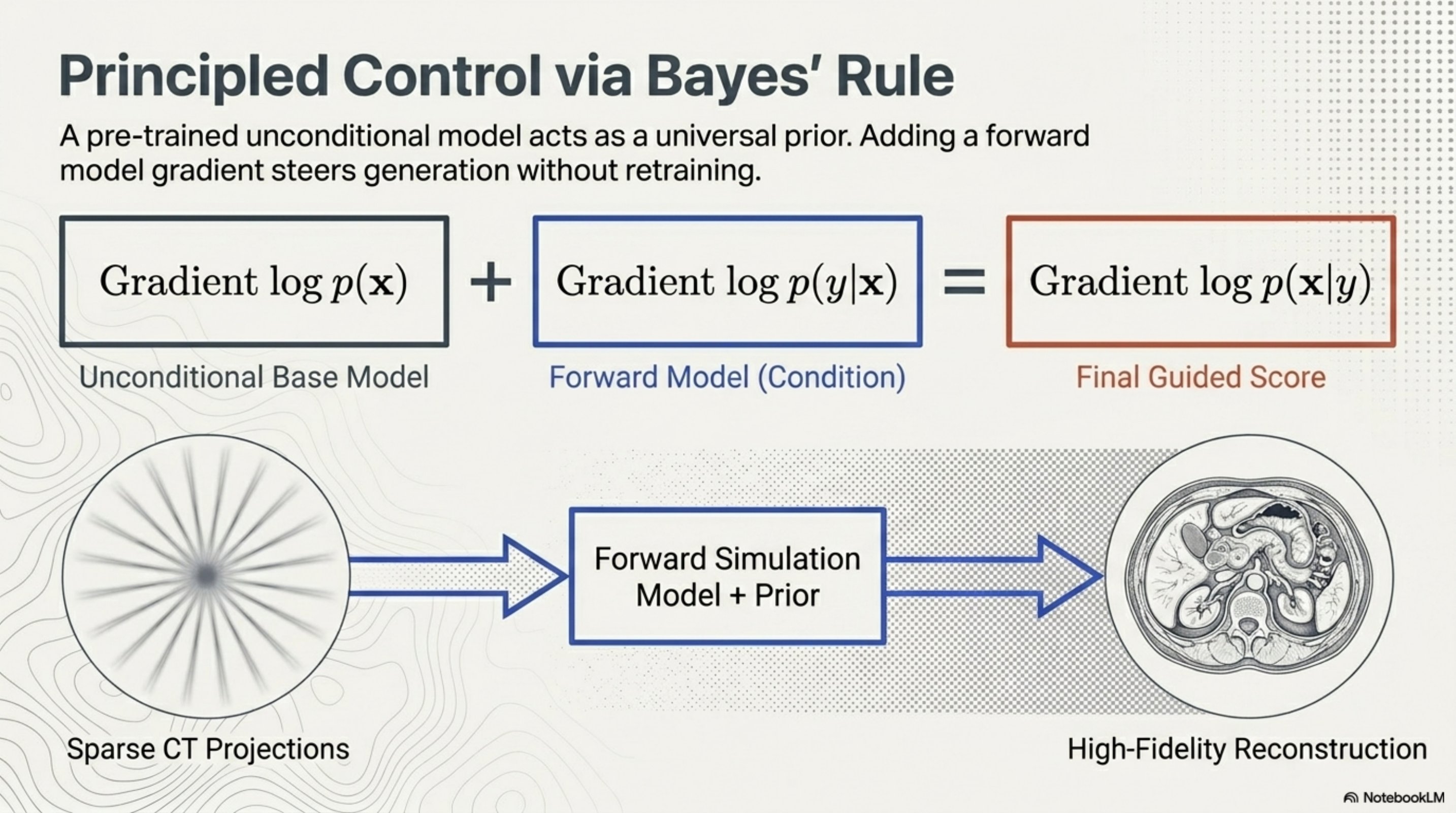
- Inverse problems in medical imaging. is a sparse-view CT sinogram; is the (linear, known) Radon transform plus measurement noise. The diffusion prior is a generic image model trained once, and the same prior reconstructs MRI, CT, and microscopy images.
- Class-conditional generation. is a classifier; classifier guidance (and its classifier-free cousin) is the same idea.
- Text-to-image. is a text embedding; the conditional score is approximated jointly with the unconditional one in a single network.
Where score-based models fit

- Sample quality rivals or exceeds GANs on benchmark image datasets (FID on CIFAR-10, ImageNet, LSUN).
- Mode coverage is high: there is no adversary to collapse onto a few easy modes; the loss is a simple regression.
- Architectural freedom matches GANs — any network that maps works as a score model. No invertibility constraint, no encoder-decoder bottleneck.
- Exact likelihoods are available via the probability-flow ODE — something GANs cannot offer at all and VAEs only bound.
End-to-end picture
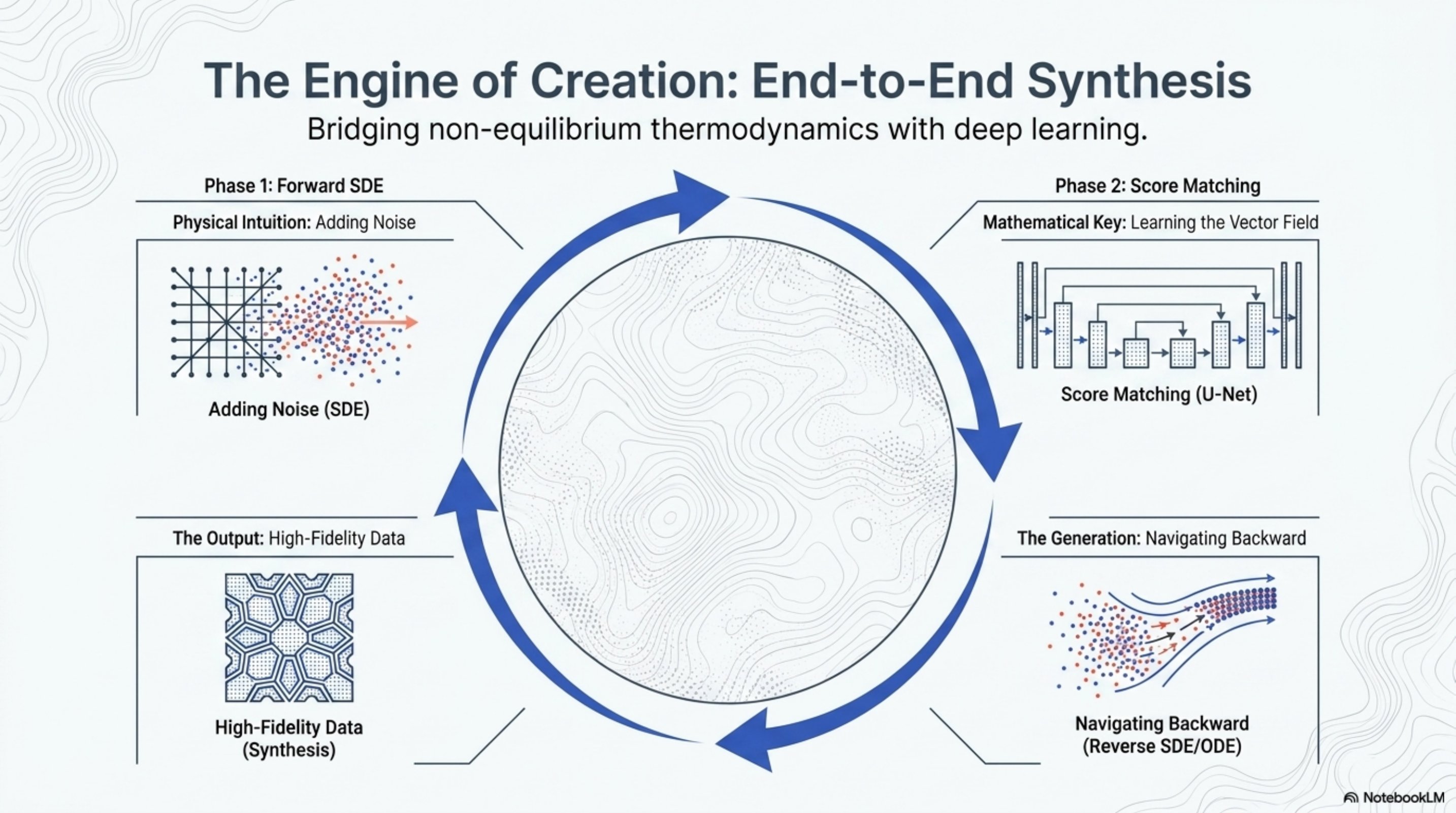
- Forward SDE smoothly noises clean data into a tractable prior.
- Score matching trains against the perturbation kernel via the DSM loss — equivalent to noise prediction up to scaling.
- Reverse SDE / probability-flow ODE plugs the trained score back into the dynamics and integrates from to .
- Output: samples drawn from , with optional conditioning grafted on by additive scores.
Hands-on companions
Three sections elsewhere in this chapter let you exercise each piece of the framework on a low-dimensional problem you can plot:- Score on a mixture of Gaussians — derive and visualize for a 2D MoG, then watch Langevin dynamics descend it.
- Yang Song’s tutorial section — the official MNIST score-SDE walkthrough: VE-SDE, NCSN++, ancestral and Predictor-Corrector samplers, and the probability-flow ODE.
- Brownian motion — eight trajectories of , the forward SDE in particle form.
- DDPM on a 2D MoG — the discrete-time Variance-Preserving instance, with noise prediction.
- DDIM on a 2D MoG — the deterministic () sampler, a first-order discretization of the probability-flow ODE.
References
- Song, Sohl-Dickstein, Kingma, Kumar, Ermon, Poole. Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021. arxiv.org/abs/2011.13456
- Song, Ermon. Generative Modeling by Estimating Gradients of the Data Distribution. NeurIPS 2019. arxiv.org/abs/1907.05600
- Vincent. A Connection Between Score Matching and Denoising Autoencoders. Neural Computation 2011.
- Anderson. Reverse-time diffusion equation models. Stochastic Processes and their Applications, 1982.
- Hyvärinen. Estimation of non-normalized statistical models by score matching. JMLR 2005.
- Song, Garg, Shi, Ermon. Sliced Score Matching: A Scalable Approach to Density and Score Estimation. UAI 2019. arxiv.org/abs/1905.07088