The target distribution
The same 2D Mixture of Gaussians used by the DDPM, DDIM, and Brownian motion tutorials: three anisotropic Gaussians, seed 42, 300 points total. To DDPM you trained a noise predictor . Here you train a score predictor that approximates , the gradient of the log-density of the data after Gaussian smoothing at scale .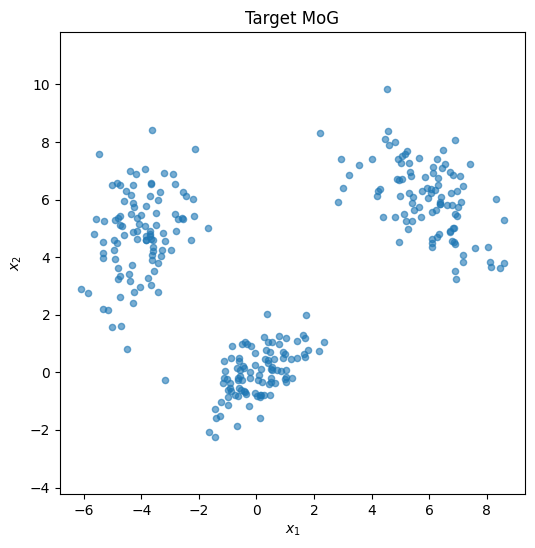
Denoising score matching
We perturb data with Gaussian noise at scale : The score of the smoothed density satisfies so the denoising score-matching objective trains to estimate across a range of noise scales. The weighting makes the loss balanced across scales, Song & Ermon 2019. We use a logarithmic noise schedule with , .Training
Standard DSM loop: sample a batch, sample a per-example , perturb, predict the score, minimize the noise-conditional loss.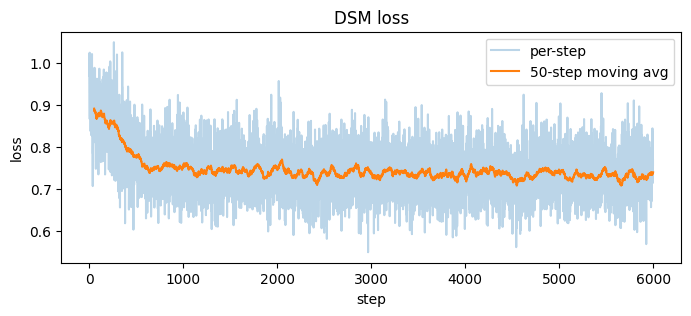
The learned score field
Evaluate on a grid at low noise (), at this scale the score points toward the data manifold, so the field should converge into the three MoG modes.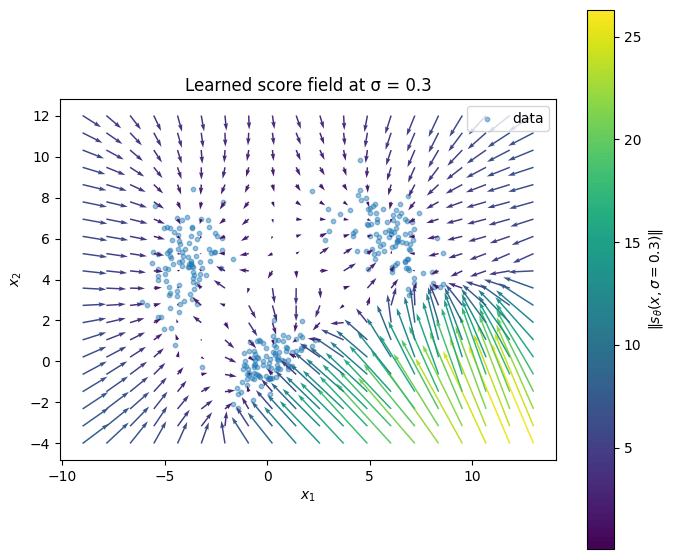
Annealed Langevin sampling
Generate samples by running Langevin dynamics at decreasing noise levels: with step size , Song & Ermon’s recipe. Larger steps cover broad regions of space; smaller steps refine onto the data manifold.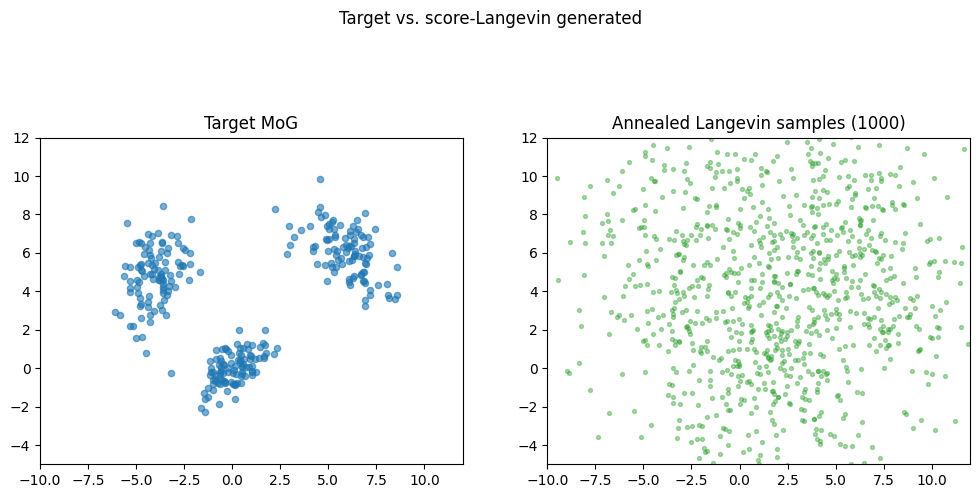
Reverse-time SDE
The variance-exploding (VE) SDE has forward and reverse-time form Discretize with Euler-Maruyama from down to . This is the same chain as DDIM at in the score-SDE framework.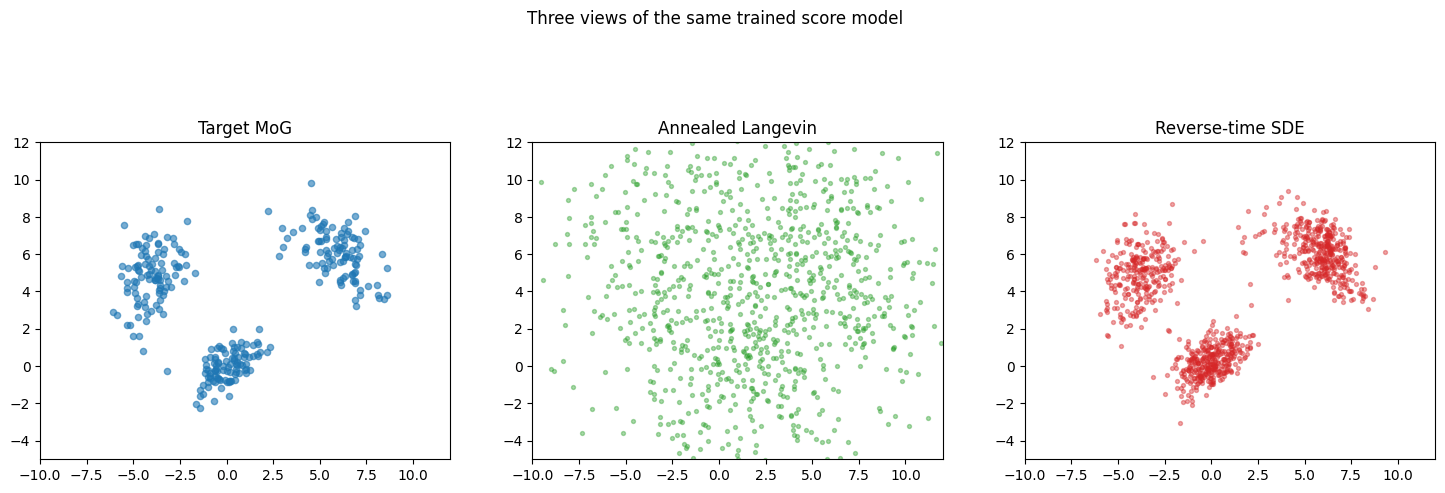
Connections to other concepts
- Score-matching is the unifying view. DDPM’s noise predictor is, up to the scaling , a score predictor; DDIM’s deterministic sampler is the probability-flow ODE limit of the same score-SDE. The framework above subsumes both.
- Sampler decoupling. Once you have , you can swap samplers: annealed Langevin, reverse SDE, probability-flow ODE, predictor-corrector. The trained network is unchanged.
- The information-theoretic angle. is the local geometry of , the same quantity that, integrated through Fisher-information identities, gives mutual information bounds. See AURA-672 for the score → Fisher → MI thread.
References
- Song, Ermon. Generative Modeling by Estimating Gradients of the Data Distribution. NeurIPS 2019. arxiv.org/abs/1907.05600
- Song, Sohl-Dickstein, Kingma, Kumar, Ermon, Poole. Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021. arxiv.org/abs/2011.13456
- Vincent. A Connection Between Score Matching and Denoising Autoencoders. Neural Computation 2011.