Diffusion models at a glance
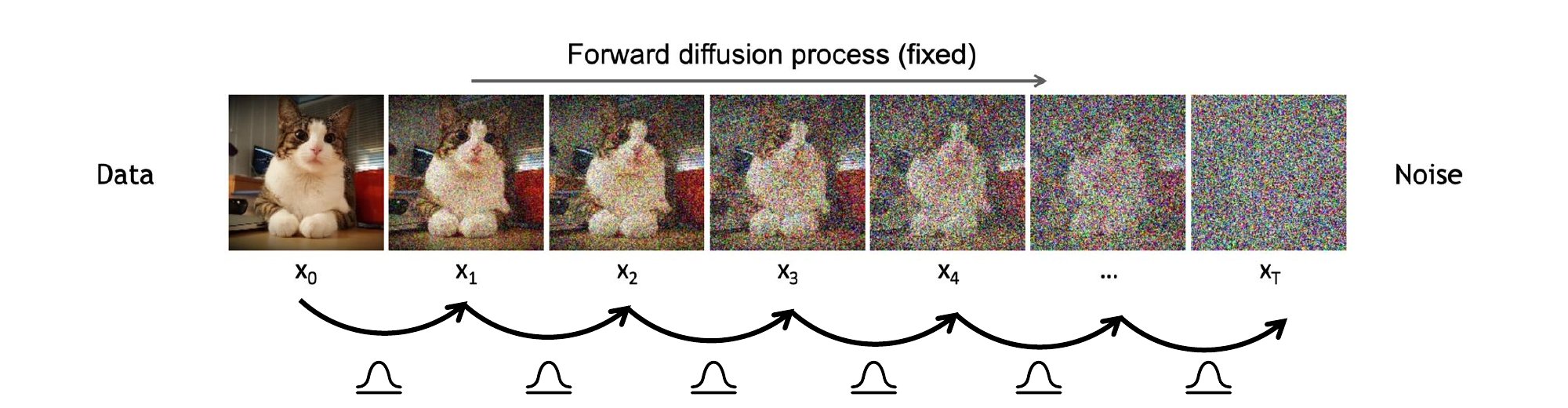
A denoising diffusion model is built from two coupled Markov chains running in opposite directions over the same set of intermediate states :- Forward diffusion process (fixed). Gradually corrupts a clean data point into pure Gaussian noise by adding a small amount of Gaussian noise at each step. No learned parameters; specified entirely by a noise schedule . Read it as a stack of fixed VAE encoders.
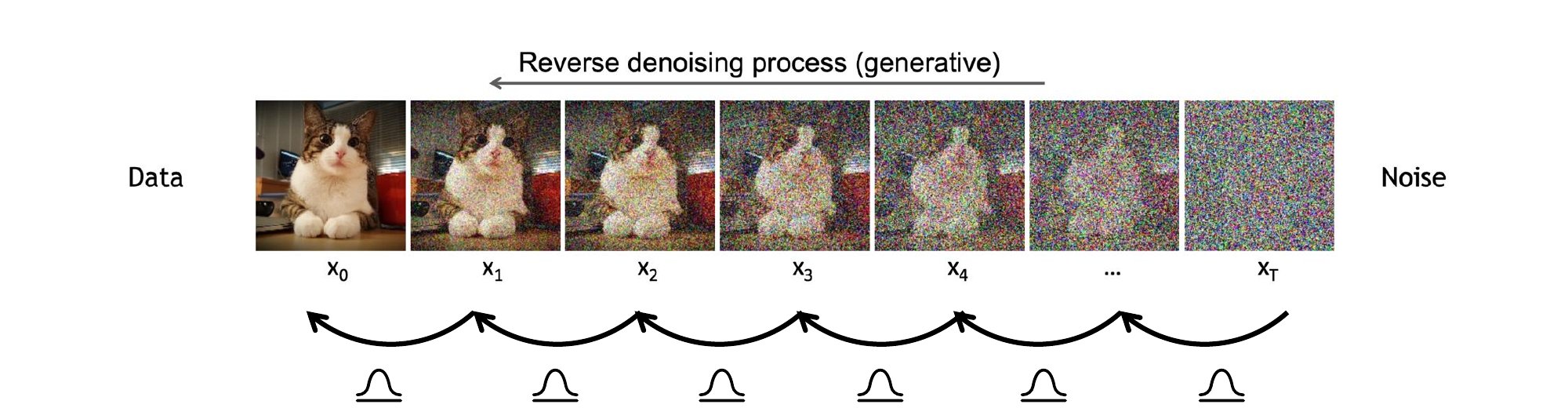
- Reverse denoising process (learnable). Starts from pure noise and gradually denoises down to . Read it as a stack of learnable VAE decoders — but with a single neural network shared across all timesteps and conditioned on .

images/forward-chain.mermaid.md

images/reverse-chain.mermaid.md
Bishop’s linear-Gaussian theorem applied to one diffusion step
A single noising step couples and through a linear-Gaussian relationship, an instance of Bishop’s linear-Gaussian theorem on the gaussians prerequisite page. Recognizing the kernel as a special case of Bishop’s template lets us read off the marginal in closed form and gives a clean route to the multi-step closed-form jump in the next section. Specialize the theorem to one DDPM step. Take , , with prior . The forward kernel is the linear-Gaussian conditional which matches Bishop’s template with , , conditional precision , and prior precision . Plugging into Bishop’s marginal formula gives the forward marginal This is the workhorse. Every later result composes the forward kernel: the full forward chain , the closed-form one-shot jump , and the forward posterior that turns out to be the right reverse-direction target — exact in closed form for any data distribution, and the object the learned will be trained to imitate. The next two sections build out the forward chain; after that the learned is introduced.The forward process: composing steps
The single-step kernel , repeated times with a fixed schedule , defines the full forward chain: Closed-form jump from to any . Because each step is linear-Gaussian and they compose, you can sample in a single shot without simulating the intermediate states. Define and the cumulative product . Iterating Bishop’s per-step recursion across steps gives This identity is what makes DDPM training cheap: at every gradient step you draw a random and compute directly from rather than rolling out the chain. The schedule is designed so that , which makes regardless of . The endpoint of the forward chain is therefore (approximately) data-independent pure noise — the same prior the reverse chain will start from.The reverse process: parameterizing what hides
To generate, we want to draw and then iteratively sample The catch: as a function of alone is not directly tractable at sampling time. Even though and are jointly distributed under the forward joint, computing this conditional requires marginalizing over the data distribution — which is precisely what we are trying to model. DDPM’s modeling choice: approximate the reverse step with a learned Gaussian, Two reasons this functional form is reasonable:- Small- limit. When each forward step injects only a little noise, the true reverse conditional — even with a non-Gaussian data distribution — is well-approximated by a Gaussian (Sohl-Dickstein et al. 2015). That is the local justification for choosing a Gaussian functional form for .
- Conditioned on , is genuinely Gaussian. A close cousin, , is exactly Gaussian for any data distribution — Bayes’ rule on the forward joint with as a fixed parameter (full derivation in the Notes on the reverse conditional deep-dive below). Training will use this two-conditional form (which has available) as the target the learned should match.
- is the only learned quantity. A single neural network produces it for every , with fed in through a sinusoidal time embedding so the same weights handle every noise level.
- is typically fixed by the schedule, commonly either or the DDPM posterior variance from , so the variance is not learned in the basic DDPM.
Notes on the reverse conditional
With both chains in place, three observations are worth flagging — one notational, two structural. The deep-dive at the end is safe to skip on a first reading.- Notation: what does and does not mean. The symbol does not tag a direction in time. The forward process defines a joint distribution , and anything you can compute from that joint stays inside the q-family. Both and its time-reversal live in it. But only some of these conditionals stay analytically simple after marginalizing over the data distribution: is fixed and explicit by construction, while is generally not available in closed form unless extra Gaussian assumptions are imposed. The contrast is with , which is the learned generative model used at sampling time, where (and therefore the data distribution) is no longer available.
- What targets. The training target the learned is fitted against is the forward posterior , which is exactly Gaussian for any data distribution (see the deep-dive below). At sampling time is unavailable, so the network’s job is to predict what that posterior would have said using only and .
- Variance accumulates predictably. Each forward step adds to a -shrunken copy of . The closed-form jump in the forward-process section is precisely the iteration of this rule across steps.
Optional deep-dive: why q(xₜ₋₁ ∣ xₜ, x₀) is Gaussian for any data distribution
Optional deep-dive: why q(xₜ₋₁ ∣ xₜ, x₀) is Gaussian for any data distribution
The naive reverse conditional — conditioning only on the current noisy state — is not in closed form for an arbitrary data distribution: it requires marginalizing over , which is exactly what we are trying to model. The standard DDPM derivation (Ho et al. 2020, eq. 6-7) sidesteps that by working with — conditioning on both the current noisy state and the original clean sample — which is exactly Gaussian for any .The two-conditional form is Gaussian for any data distribution . Apply Bayes’ rule on the forward joint:By the Markov property of the forward chain, is the Gaussian noising kernel. The other two terms are the closed-form jumps from derived in the forward-process section, both Gaussian. The product/quotient of three Gaussians (in ) is again Gaussian. The data distribution never enters because is a fixed parameter here, not a random variable being marginalized over — its value just shifts the means.By contrast, without marginalizes out:a mixture of Gaussians weighted by the posterior , generally non-Gaussian unless itself is Gaussian. The two-conditional form avoids this entirely: with as a fixed parameter, the data distribution drops out of the algebra and the closed form holds regardless of . That is the forward posterior that appears in the ELBO derivation below — at training time you have available, and the result is a Gaussian whose mean and variance are explicit functions of alone.
Optional worked example: a three-step diffusion run end-to-end
Optional worked example: a three-step diffusion run end-to-end
Consider a toy diffusion model with only three noising steps: is a clean data sample (for example, an image) and is almost Gaussian noise. Pick a forward noise scheduleand define together with the cumulative productForward process. The forward process is fixed: it gradually corrupts the data byFor the three steps,Equivalently, you can sample any noisy point directly from :so the final noisy sample isReverse process. The reverse process tries to undo the corruption: . Parameterize the learned reverse kernel asinstantiated at the three steps as , , .A note on notation: and are written with a single argument because is already pinned down by the subscript on . In code, and are a single shared network used at every timestep, conditioned on through a learned time embedding; the argument is implicit in the input typing.In DDPM the network predicts the noise that was added. Plugging that into the reverse mean givesStarting from , the three reverse transitions areThe essential idea: the forward chain adds known Gaussian noise, and the reverse chain learns how much noise to remove. Putting both directions on the same picture,
What the network outputs
The reverse-step distribution is parameterized as but what the neural network literally computes is a design choice. There are three algebraically equivalent options:- Predict the mean directly — . The most direct read of the parameterization above; the network output is a vector with the shape of , used as the mean of the reverse Gaussian.
- Predict the noise — . The network outputs a vector with the shape of that estimates the noise that was added when forming from via the closed-form jump. The reverse-step mean is then derived analytically:
- Predict the clean data — . The network outputs an estimate of the original . The reverse-step mean is derived from the forward posterior with the network’s plugged in for the unknown .
- Given : solve for .
- Given : solve for .
- The training target has fixed scale at every , so the regression problem is well-conditioned across all noise levels.
- The corresponding training loss collapses to a plain unweighted MSE — the derived in the next section.
- The network’s job becomes a single intuitive task: “look at this noisy data and tell me the noise that was added”.

images/network-io.mermaid.md
The data input dimension is whatever has (2 for the MoG example, 3×H×W for images). The timestep enters through a sinusoidal time embedding (the original DDPM lifts Vaswani’s positional-encoding formula and feeds the integer into it) so a single set of weights handles every noise level. At sampling time, the predicted noise gets plugged into the analytic reverse-step mean above, and a small amount of fresh Gaussian noise is added (controlled by ) to draw . The next section derives why training this network on the noise-prediction MSE is exactly the right loss to maximize the data likelihood.
Training objective: from VAE ELBO to the DDPM loss
You now have a fixed forward chain and a parameterized reverse chain . The remaining question is what loss to train on. The answer is the same Evidence Lower Bound (ELBO) derived for VAEs (see Optimization and the ELBO for the single-latent derivation), applied here to a deep, Markov latent chain whose encoder happens to be fixed. DDPM is a hierarchical VAE with two simplifying choices: the latent is a Markov chain , and the encoder is fixed, namely hand-designed Gaussian noise injection with no learnable parameters. Hierarchical here means a stack of latents rather than the single latent from the basic VAE architecture. A generic hierarchical VAE (NVAE, ladder-VAE, ResNet-VAE) learns both the top-down decoder and a bottom-up encoder at every level; DDPM keeps the top-down chain learnable and freezes the bottom-up chain to a fixed Gaussian schedule.| VAE | DDPM |
|---|---|
| Single latent | Chain |
| Encoder , learned | Forward process , fixed Gaussians |
| Decoder | Reverse chain |
| Prior | Endpoint |
A telescoping decomposition
Both chains are Markov, so the joint distributions factorize across . Applying Bayes’ rule to rewrite each forward step in terms of the forward posterior telescopes the bound into three pieces (Ho et al., eq. 5): Each piece has a direct VAE counterpart:- is the reconstruction term, playing the same role as in the single-latent VAE, just at the bottom rung of the chain instead of after one decoder pass.
- is the prior-matching term, the same role as in the VAE. Because the forward process is fixed and the schedule is chosen so that for large , this term has no parameters to optimize: it is approximately constant during training, and DDPM drops it from the loss.
- are the per-step transition KLs between the analytically tractable forward posterior , whose closed form was derived in Bishop’s linear-Gaussian theorem applied to one diffusion step near the top of this page, and the learned reverse step . These have no counterpart in a single-latent VAE; they appear because the chain has rungs.
Why this is operationally simpler than a hierarchical VAE
Fixing the encoder buys two simplifications that ordinary VAEs cannot exploit:- No encoder gradient. The forward process has no . The bound-tightening role the encoder plays in a VAE (gradients on minimizing the posterior KL) disappears entirely. Training is a single-network problem in .
- All terms share parameters. In the standard fixed-variance DDPM setup, both and are Gaussians with matched prescribed covariance, so the learnable part is the mean. Combining the reparameterization from the worked example above with the noise-prediction parameterization collapses each , up to a -dependent weight, to a noise-prediction MSE (Ho et al., §3.2): Dropping the -dependent weight gives the simple training objective that produced DDPM’s image-quality results.
References
- Kingma, Welling. Auto-Encoding Variational Bayes. ICLR 2014. arxiv.org/abs/1312.6114
- Ho, Jain, Abbeel. Denoising Diffusion Probabilistic Models. NeurIPS 2020. arxiv.org/abs/2006.11239
- Sohl-Dickstein et al. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. ICML 2015. arxiv.org/abs/1503.03585
- Song et al. Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021. arxiv.org/abs/2011.13456
PyTorch reference
| PyTorch class | Description |
|---|---|
nn.Conv2d | Applies a 2D convolution over an input signal composed of several input planes. |
nn.GroupNorm | Applies Group Normalization over a mini-batch of inputs. |
nn.Linear | Applies an affine linear transformation to the incoming data: . |
nn.SiLU | Applies the Sigmoid Linear Unit (SiLU) function, element-wise. |