- Build a minimal ResNet block with and without batch normalization
- Train both variants on CIFAR-10 and compare convergence speed, final accuracy, and gradient health
- Visualize how BN stabilizes the distribution of intermediate activations across training
CIFAR-10 data loaders
We use standard CIFAR-10 normalisation (channel mean and std computed from the training set).ResNet building blocks
We implement two variants of the basic residual block:ResBlock, with batch normalization (use_bn=True, default)ResBlock, without batch normalization (use_bn=False)
Training loop
We train both variants for the same number of epochs with the same SGD + cosine-annealing schedule and compare:- Training loss and test accuracy per epoch
- Gradient norms at the stem layer (a proxy for gradient health)
Results: training loss, test accuracy, and gradient norms
The three plots below summarise the effect of batch normalisation on a residual network trained on CIFAR-10.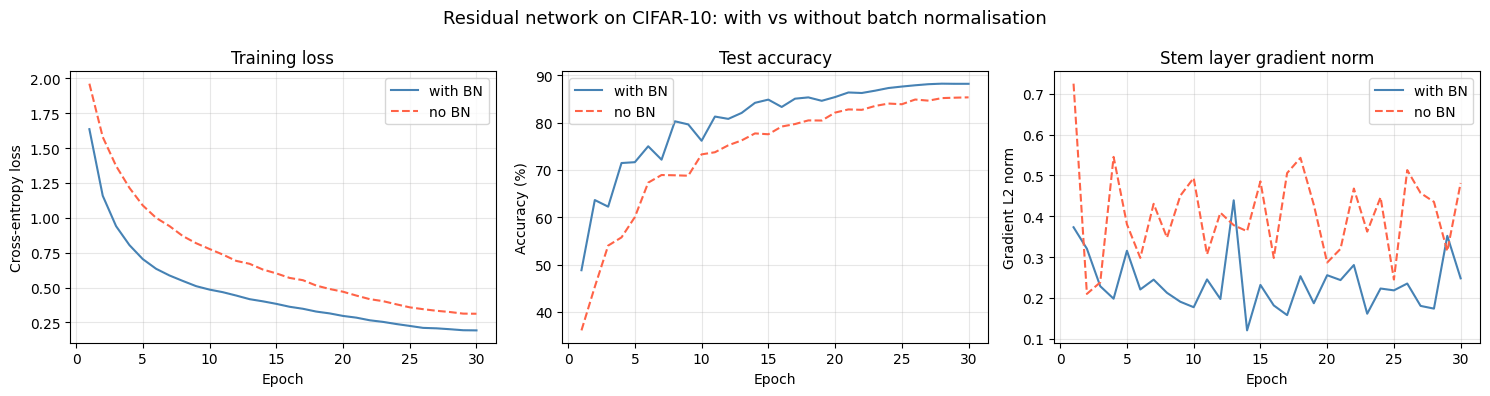
Activation distribution across training
To see why BN helps, we capture the distribution of activations at the output oflayer1 at epochs 1, 15, and 30. Without BN the distribution drifts and widens; with BN it stays anchored near zero.
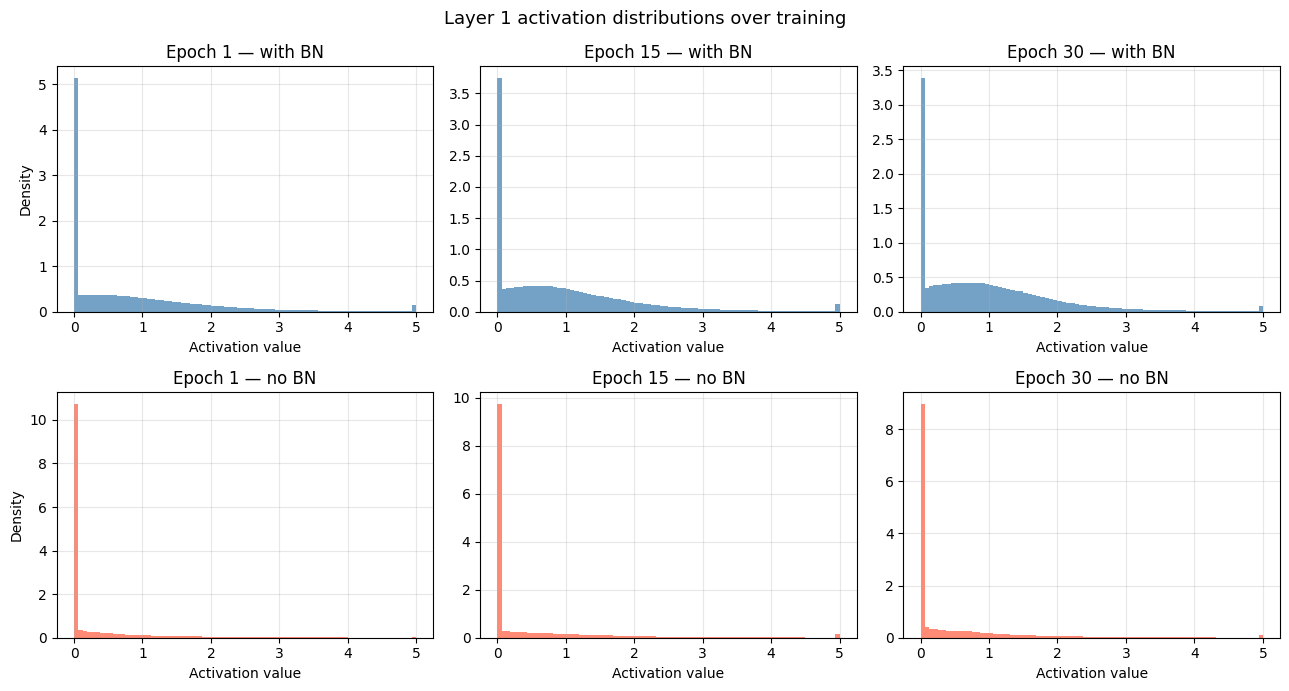
Summary
These results confirm why every modern ResNet variant (ResNet-50, ResNeXt, Wide-ResNet) applies batch normalization after each convolution before the non-linearity.