The core dimensional constraint
Let . A residual unit computes and addition requires identical tensor shapes: Hence the skip connection must handle two mismatches:- channel mismatch:
- spatial mismatch: (typically caused by stride-2 downsampling)
Residual block, skip connection options
![Residual unit data flow. Input x [B, Cᵢₙ, H, W] passes through the residual branch Conv 3×3 stride s, BN + ReLU, Conv 3×3 stride 1, BN into an addition node. In parallel, the skip connection takes one of two routes: an Identity branch when Cᵢₙ=Cₒᵤₜ and s=1, otherwise a 1×1 Conv with stride s (Option B). Both routes feed the same addition node, whose output goes through ReLU to produce y [B, Cₒᵤₜ, H/s, W/s].](https://mintcdn.com/aegeanaiinc/GzniP9C4vDOR6BiK/aiml-common/lectures/cnn/resnet-skip-dimensioning-fpn/images/residual-block-skip.svg?fit=max&auto=format&n=GzniP9C4vDOR6BiK&q=85&s=8eaa8c41489b31ee7661a5e9a17c078d)
images/residual-block-skip.mermaid.md
Addition requires identical tensor shapes: both the residual branch and the skip connection must produce .
ResNet-style block with correct skip connection dimensioning
We implement a standard BasicBlock with:- residual branch: 3×3 conv → BN → ReLU → 3×3 conv → BN
- skip connection:
- identity if stride=1 and
- otherwise a 1×1 conv (projection), with the same stride as the residual branch’s downsampling
Option A vs. Option B (ResNet paper terminology)
In the ResNet paper’s discussion:- Option A: downsample the skip connection (stride 2) and zero-pad channels to match .
- Option B: downsample and project with 1×1 conv to match dimensions.
- the feature hierarchy is consumed downstream (e.g., lateral merges), so having a learned projection at stage transitions is robust,
- and it matches the canonical ResNet-{50,101,152} “option B” design in the CVPR paper.
A minimal ResNet-like backbone that exposes {C2, C3, C4, C5}
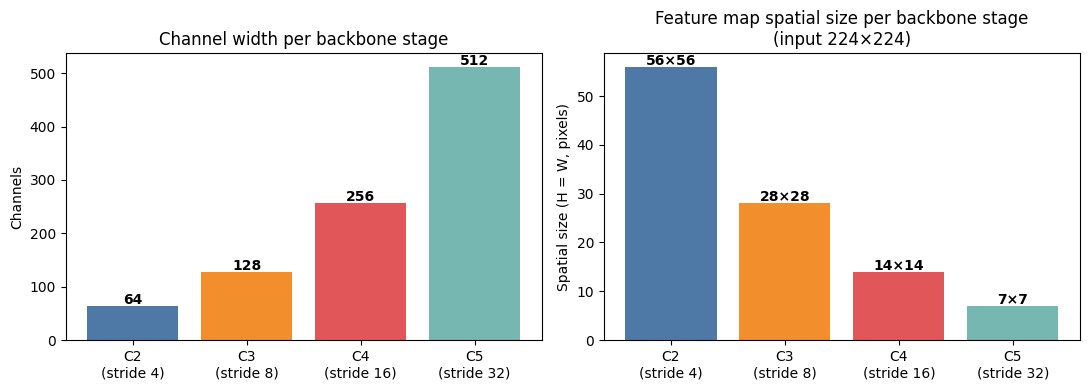
FPN (Lin et al.) uses the outputs of each ResNet stage’s last block: {C2, C3, C4, C5} with strides {4, 8, 16, 32} relative to the input. We build a small backbone that mirrors this structure (conceptually like a tiny ResNet-18).Backbone stage layout, strides and channel widths

images/backbone-stages.mermaid.md
Each stage transition uses a stride-2 first block with a 1×1 projection skip connection (Option B) to match dimensions.
FPN module implementation
Canonical FPN design choices (as in Lin et al.):- 1×1 lateral conv to unify channels to
- top-down upsample by factor 2 (nearest neighbor is typical)
- element-wise addition (requires same and same )
- 3×3 conv “smoothing” on each merged map
- optional via stride-2 3×3 conv on (common in detection systems)
FPN top-down pathway, lateral merges and channel unification

images/fpn-top-down.mermaid.md
The 1×1 lateral convolutions unify heterogeneous backbone channels (64/128/256/512) to a uniform before the element-wise additions. The additions require strict spatial and channel alignment, which the lateral convolutions and upsample guarantee.
What “preferred approach for FPN” means (operationally)
In a modern featurizer intended for FPN-style consumption, the pragmatic default is:-
Backbone (ResNet-style):
- Identity skip connection if matches
- 1×1 projection skip connection (with stride=2 when downsampling) otherwise
This matches the ResNet paper’s “projection to match dimensions” guidance and the widespread “option B” practice in deep variants.
-
FPN neck:
- 1×1 lateral convs to unify all to channels
- top-down nearest-neighbor upsample by 2
- elementwise addition
- 3×3 smoothing conv
- optional from via stride-2 3×3 conv
References (primary sources)
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. CVPR 2016. arXiv:1512.03385.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Identity Mappings in Deep Residual Networks. ECCV 2016. arXiv:1603.05027.
- Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie. Feature Pyramid Networks for Object Detection. CVPR 2017. arXiv:1612.03144.
PyTorch reference
References
- Dong, X., Wu, J., Zhou, L. (2017). How deep learning works -The geometry of deep learning.
- He, K., Zhang, X., Ren, S., Sun, J. (2016). Identity mappings in deep residual networks.
- Tan, M., Le, Q. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.
- Wightman, R., Touvron, H., Jégou, H. (2021). ResNet strikes back: An improved training procedure in timm.
- Zagoruyko, S., Komodakis, N. (2016). Wide Residual Networks.