What is the Average Precision (AP) metric
The AP is the approximation of the Area Under the Curve (AUC). This approximation involves interpolation that eliminates the noisy Precision vs Recall curve - effectively converting this curve to a monotonic curve. This is shown next.Example of calculating AP
The following example is based on here and its corresponding implementation Considering the set of 12 images in the figure below:
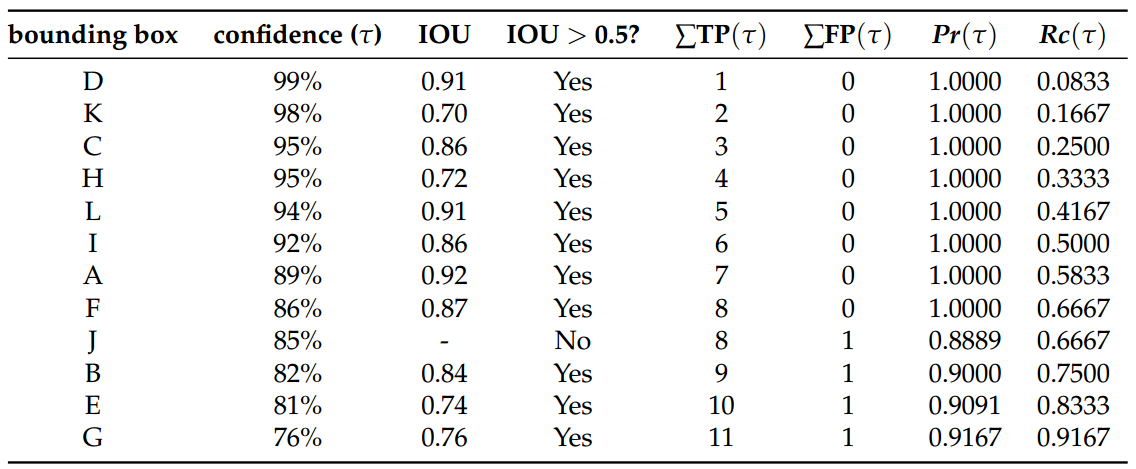
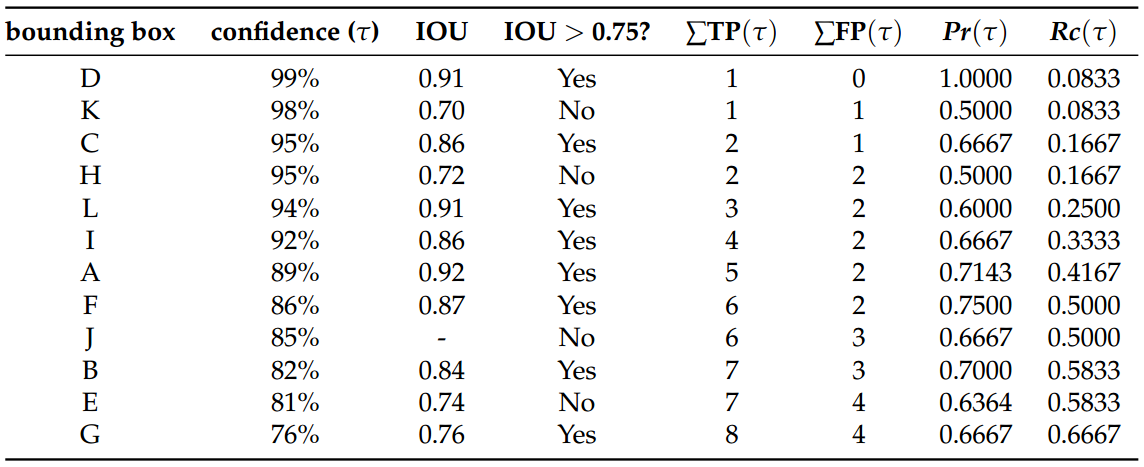
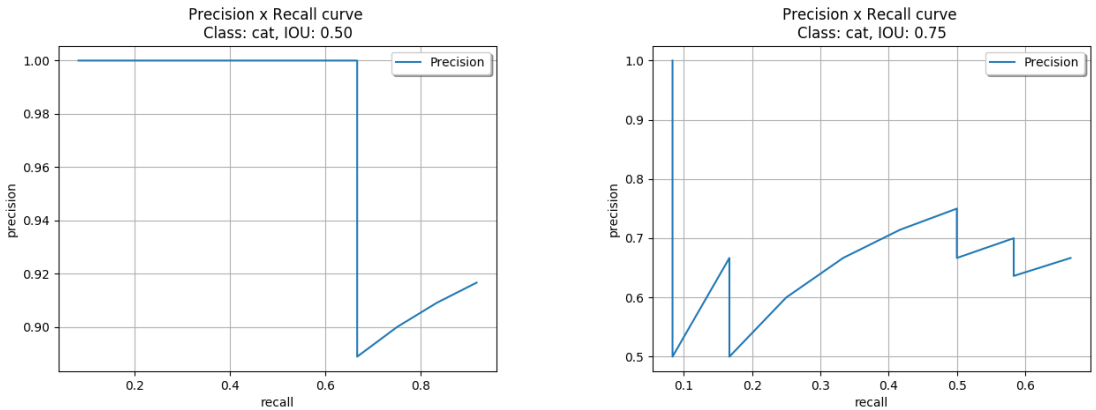
- With a less restrictive IOU threshold (t=0.5), higher recall values can be obtained with the highest precision. In other words, the detector can retrieve about 66.5% of the total ground truths without any miss detection.
- Using t=0.75, the detector is more sensitive with different confidence values. This is explained by the amount of ups and downs of the curve.
- Regardless the IOU threshold applied, this detector can never retrieve 100% of the ground truths (recall = 1). This is due to the fact that the algorithm did not predict any bounding box for one of the ground truths in image (e).
 ”
When an IOU threshold t=0.5 was applied (plots of the first row in image above), the 11-point interpolation method obtained AP=88.64% while the all-point interpolation method improved the results a little, reaching AP=89.58%. Similarly, for an IOU threshold of t=0.75% (plots of the second row in image above), the 11-point interpolation method obtained AP=49.24% and the all-point interpolation AP=50.97%.
In both cases, the all-point interpolation approach considers larger areas above the curve into the summation and consequently obtains higher results.
When a lower IOU threshold was considered, the AP was reduced drastically in both interpolation approaches.
Please note that MS COCO AP results are reported with interpolation over points.
”
When an IOU threshold t=0.5 was applied (plots of the first row in image above), the 11-point interpolation method obtained AP=88.64% while the all-point interpolation method improved the results a little, reaching AP=89.58%. Similarly, for an IOU threshold of t=0.75% (plots of the second row in image above), the 11-point interpolation method obtained AP=49.24% and the all-point interpolation AP=50.97%.
In both cases, the all-point interpolation approach considers larger areas above the curve into the summation and consequently obtains higher results.
When a lower IOU threshold was considered, the AP was reduced drastically in both interpolation approaches.
Please note that MS COCO AP results are reported with interpolation over points.
Mean AP (mAP)
In classification problems with multiple classes the mean AP is simply the sample mean of across the C classes. Key references: (Girshick et al., 2013; Redmon & Farhadi, 2016; Huang et al., 2016; Lin et al., 2014; Real et al., 2017)References
- Girshick, R., Donahue, J., Darrell, T., Malik, J. (2013). Rich feature hierarchies for accurate object detection and semantic segmentation.
- Huang, J., Rathod, V., Sun, C., Zhu, M., Korattikara, A., et al. (2016). Speed/accuracy trade-offs for modern convolutional object detectors.
- Lin, T., Maire, M., Belongie, S., Bourdev, L., Girshick, R., et al. (2014). Microsoft COCO: Common Objects in Context.
- Real, E., Shlens, J., Mazzocchi, S., Pan, X., Vanhoucke, V. (2017). YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video.
- Redmon, J., Farhadi, A. (2016). YOLO9000: Better, Faster, Stronger.