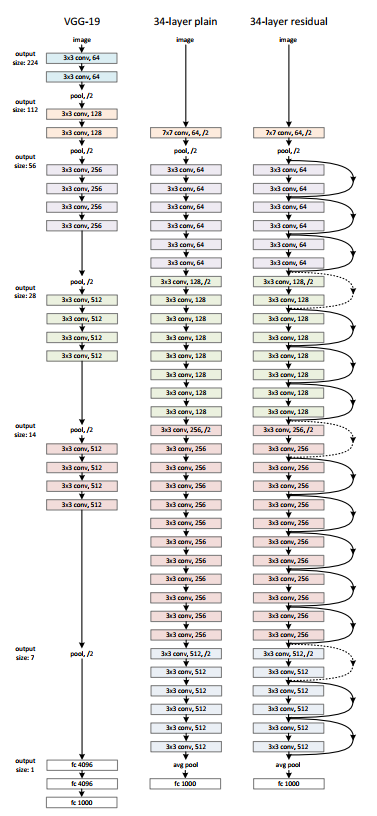
Performance advantages of ResNets
We now show that ensemble learning performance advantages are present in residual networks.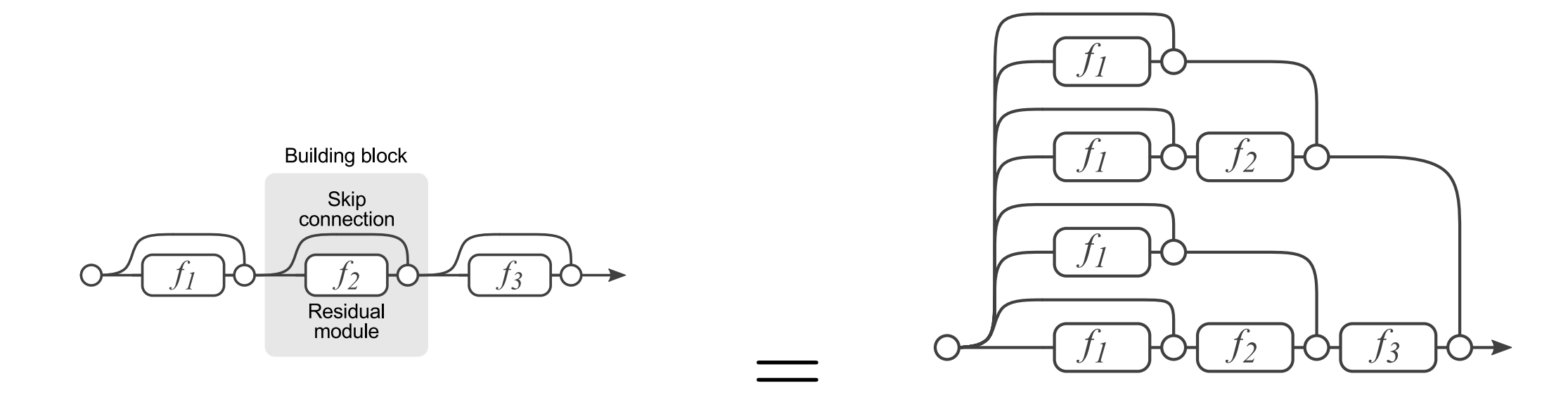
- We see many diverse paths to the gradient as it flows from the to the trainable parameter tensors of each layer.
- We see elements of ensemble learning in the formation of the hypothesis .
- We can eliminate layers from the architecture (blocks) without having to redimension the network, allowing us to trade performance for latancy during inference.
References
- He, K., Zhang, X., Ren, S., Sun, J. (2015). Deep Residual Learning for Image Recognition.
- Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A. (2016). Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning.
- Veit, A., Wilber, M., Belongie, S. (2016). Residual Networks Behave Like Ensembles of Relatively Shallow Networks.
- Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K. (2016). Aggregated Residual Transformations for Deep Neural Networks.
- Zagoruyko, S., Komodakis, N. (2016). Wide Residual Networks.