Detect objects in an image
Object detection is demonstrated in this short video clip that shows the end result - placing bounding boxes around classes of interest.
The difference between classification and object detection is shown below.

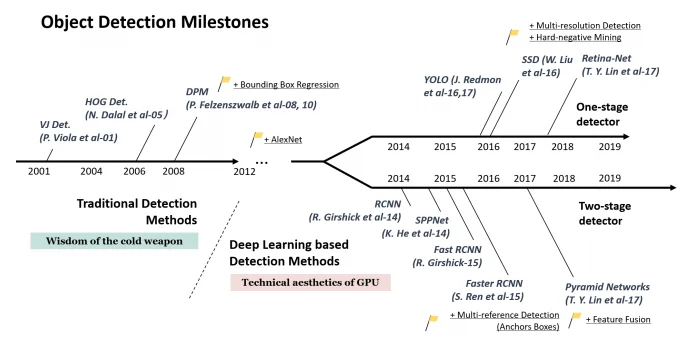
- Region proposals.
- Fully Convolutional Networks (FCNs).
Semantic segmentation
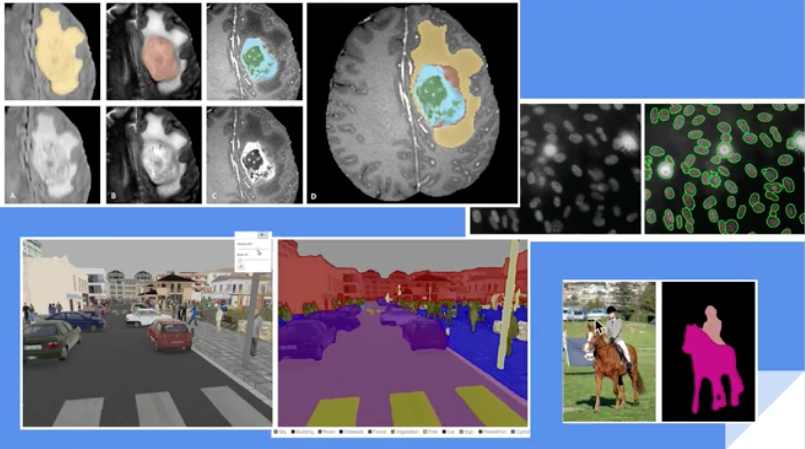
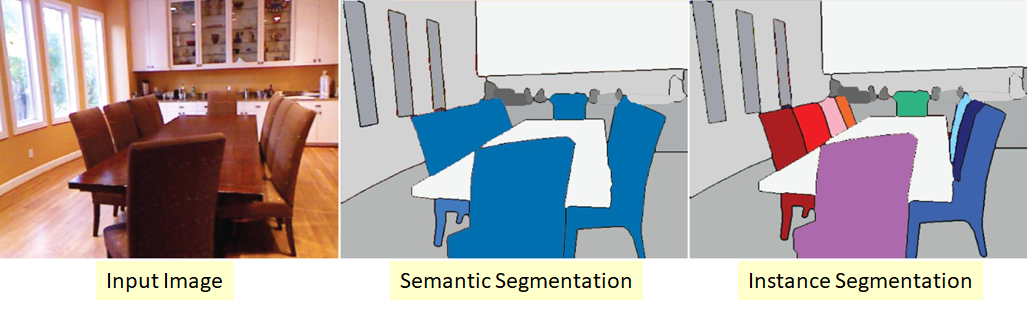
Instance segmentation
Datasets for computer vision tasks
COCO

- 80 object classes. These are the so-called thing classes (person, car, elephant, …).
- 91 stuff classes. These are the so-called stuff classes (sky, grass, wall, …). Stuff classes cover the majority of the pixels in COCO (~66%). Stuff classes are important as they allow to explain important aspects of an image, including scene type, which thing classes are likely to be present and their location (through contextual reasoning), physical attributes, material types and geometric properties of the scene.
- 5 captions per image
- Keypoints for the “person” class
- Detection Task: Object detection and semantic segmentation of thing classes.
- Stuff Segmentation Task: Semantic segmentation of stuff classes.
- Keypoints Task: Localization of person’s keypoints (sparse skeletal points).
- DensePose Task: Localization of people’s dense keypoints, mapping all human pixels to a 3D surface of the human body.
- Panoptic Segmentation Task: Scene segmentation, unifying semantic and instance segmentation tasks. Task is across thing and stuff classes.
- Image Captioning Task: Describing with natural language text the image. This task ended in 2015. Image captioning is very important though and other datasets exist to supplement the curated COCO captions.
References
- Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., et al. (2016). The Cityscapes Dataset for Semantic Urban Scene Understanding.
- Lin, T., Maire, M., Belongie, S., Bourdev, L., Girshick, R., et al. (2014). Microsoft COCO: Common Objects in Context.
- Redmon, J., Divvala, S., Girshick, R., Farhadi, A. (2015). You only look once: Unified, real-time object detection.
- Redmon, J., Farhadi, A. (2016). YOLO9000: Better, Faster, Stronger.
- Ren, S., He, K., Girshick, R., Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.
- Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A. (2014). Object detectors emerge in deep scene CNNs.
- Zhou, B., Khosla, A., Lapedriza, À., Oliva, A., Torralba, A. (2014). Object detectors emerge in deep scene CNNs.