- Robot pose (planar): .
- Map : occupancy grid (binary / probabilistic) or geometric (polygonal, mesh).
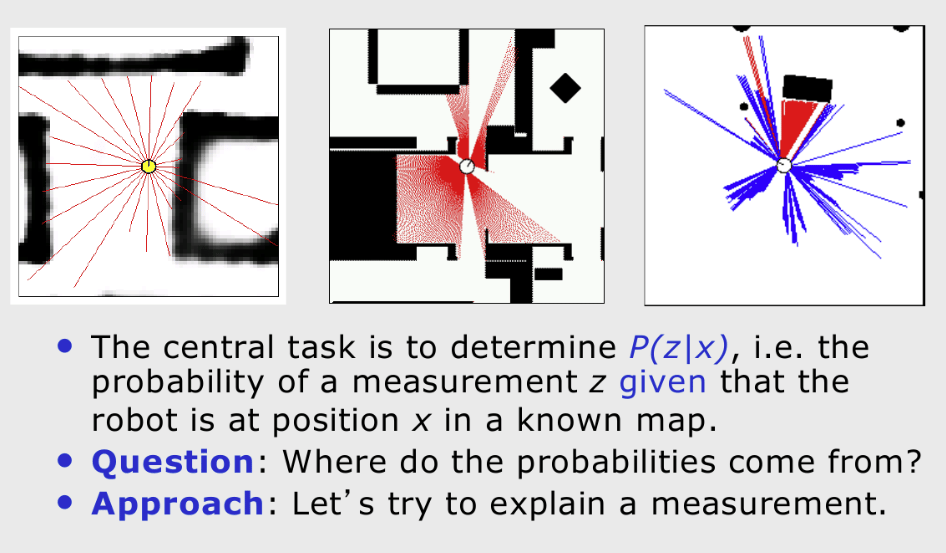
- Scan: with beam angles relative to sensor frame.
- Maximum sensor range: .
- Expected (ideal) range along beam : found via ray casting.

Beam-Based Forward Model (Mixture)
Real measurements exhibit multiple phenomena: precise hits, unexpected short returns, max-range (no return), and random noise. Model each beam as a weighted mixture: with .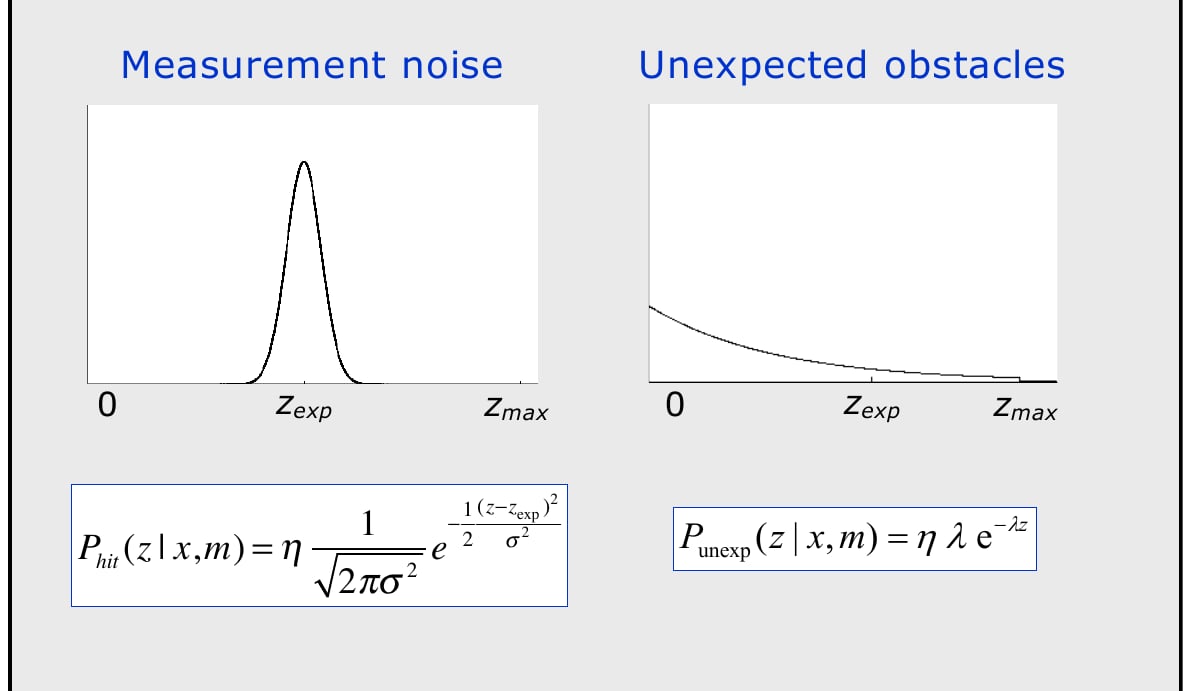
Precise Hit Component
normalizes over .Unexpected Short Return
Captures unmodelled obstacles between sensor and predicted surface:
Max Range
Random Noise
Final Per-Beam Likelihood
Log form for numerical stability:Parameter Estimation
Given training set :- Closed-form for using weighted residual variance if component assignments known.
- Use EM:
- E-step: responsibilities .
- M-step: ; update via weighted MLE.
Dynamic Obstacles
Augment forward model with dynamic layer : where could emphasize short / random returns; from motion segmentation. Key references: (Zeng et al., 2016)References
- Zeng, A., Song, S., Nießner, M., Fisher, M., Xiao, J., et al. (2016). 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions.