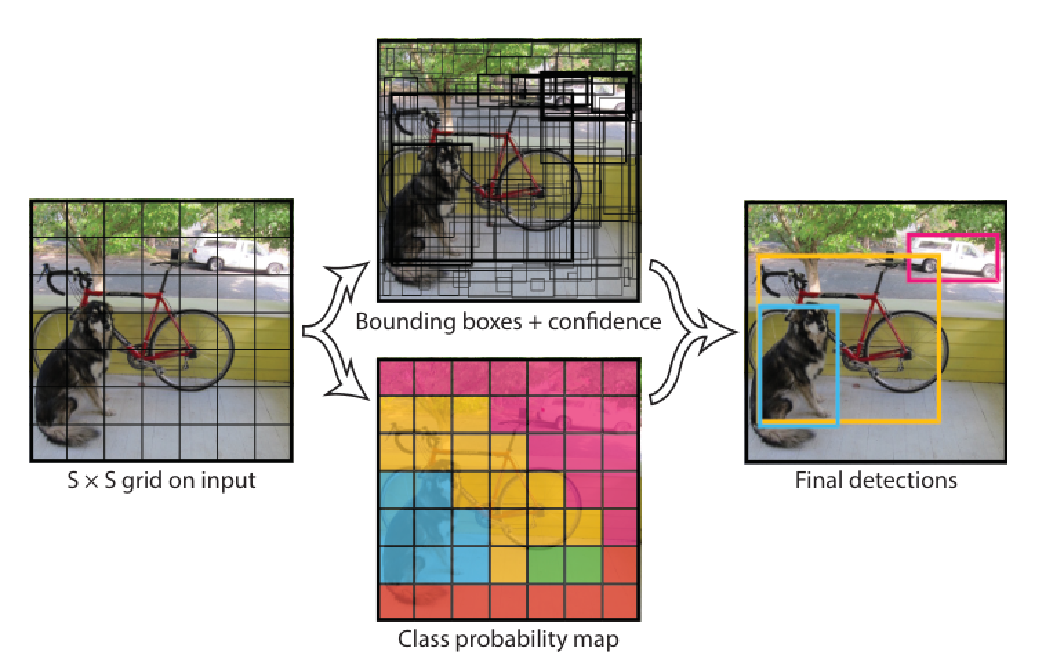
Class-specific confidence at test time
At inference we combine per-cell conditional class probabilities with the per-box confidence to score each box for each class: This produces class-specific confidence scores used before NMS.Network architecture and activations
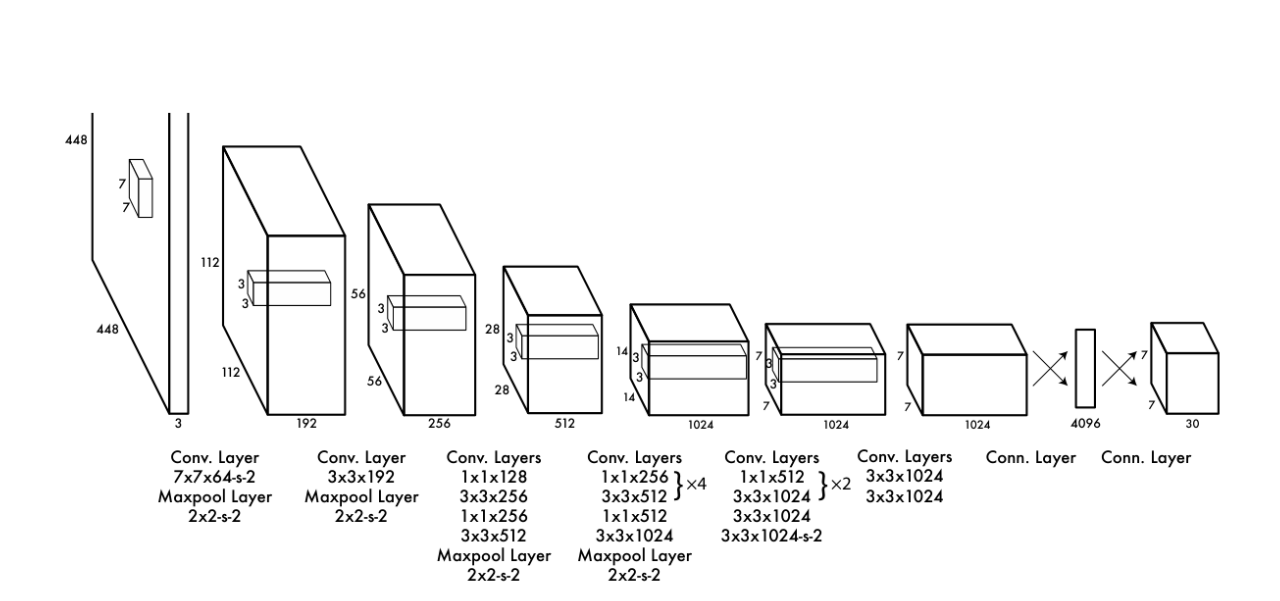
Training targets and responsibility
Because each cell predicts boxes, YOLO assigns “responsibility” to exactly one of the predictors for a given object: the predictor whose current box has the highest IoU with that object’s ground-truth. This specialization improves recall. Consequence for targets:- Only the responsible predictor for a cell/object receives coordinate and objectness regression targets for that object.
- The other predictor(s) in that cell are trained toward “no object” for confidence, reducing spurious positives.
The multi-part loss
YOLOv1 optimizes a sum-squared error over location, size, objectness (confidence), and classification, with two balancing coefficients and . To de-emphasize scale sensitivity, the loss regresses instead of . Here iff predictor in cell is responsible for some object; for “no object” cases; and . Classification loss is applied only when a cell contains an object.Optimization details
Typical training recipe (VOC): ~135 epochs, batch size 64, momentum 0.9, weight decay . LR warmup from to , then for 75 epochs, for 30, for 30. Regularization via dropout (rate 0.5 after first FC) and data augmentation (random scale/translation up to 20%, exposure/saturation jitters in HSV up to 1.5×).End-to-end inference
- Preprocess: resize the image (e.g., to ) and forward once through the CNN.
-
Decode raw outputs:
- For each cell and predictor : convert normalized to image coordinates; take the predicted confidence .
- Combine with class probabilities using Eq. (1) to get class-specific scores .
-
Filter and suppress:
- Discard low-score boxes.
- Perform non-max suppression per class. While not as critical as in proposal-based pipelines, NMS adds ~2–3 mAP points by removing duplicates from neighboring cells.
Strengths and limitations
- One-shot, global reasoning; extremely fast.
- Different error profile vs. R-CNN family (fewer background false positives, more localization errors).
- Limitations: fixed grid capacity (crowded small objects), coarse features due to downsampling, and sensitivity to small-box localization.
- Grid cell owns an object if the object’s center falls inside.
- Exactly one predictor per owned object learns its geometry (IoU-based responsibility).
- Confidence objectness IoU; class probs are cell-level. Eq. (1) fuses them into a per-class score.
- Loss trades off localization, objectness, and classification with ; sizes use square-root to temper scale effects. Eq. (3).
PyTorch sections
The following sections progressively build a complete YOLOv11 anchor-free detector from scratch in PyTorch.Data Pipeline
COCO data loading, letterbox resizing, mosaic augmentation, and multi-scale target encoding for anchor-free detection.
Backbone
Conv-BN-SiLU blocks, Bottleneck, C3k2 (CSP), SPPF, and the full backbone producing P3/P4/P5 features.
Neck and Head
FPN top-down and PAN bottom-up feature aggregation, C2PSA attention, decoupled anchor-free head with DFL.
Loss and Training
IoU variants (GIoU/DIoU/CIoU), Task-Aligned Learning, BCE + CIoU + DFL composite loss, training loop.
Inference and Evaluation
Prediction decoding, NMS from scratch, COCO mAP evaluation, Grad-CAM visualization.
PyTorch reference
Key references: (Redmon et al., 2015; Redmon & Farhadi, 2016; Liu et al., 2015; Canziani et al., 2016; Godard et al., 2016)
References
- Canziani, A., Paszke, A., Culurciello, E. (2016). An Analysis of Deep Neural Network Models for Practical Applications.
- Godard, C., Aodha, O., Brostow, G. (2016). Unsupervised Monocular Depth Estimation with Left-Right Consistency.
- Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., et al. (2015). SSD: Single Shot MultiBox Detector.
- Redmon, J., Divvala, S., Girshick, R., Farhadi, A. (2015). You only look once: Unified, real-time object detection.
- Redmon, J., Farhadi, A. (2016). YOLO9000: Better, Faster, Stronger.